




之前的文章,我们一起聊了 GPU 与 CPU 相关,可以先回顾一下:聊聊 GPU 与 CPU的那些事-优快云博客
既然大模型要用 GPU,作为个人学习使用,当然得买消费级的显卡,比如Geforce RTX4090,但这也不便宜啊,而且只有 24G 的显存。再看看那些模型的显存需求,看来也不太够用啊。
那么,最简单省事的方案是什么呢?
作为个人开发者,最简单的方案就是用 MacBook Pro M 系列芯片。
我们一起来看看。
目前最新的是 M4 系列芯片。

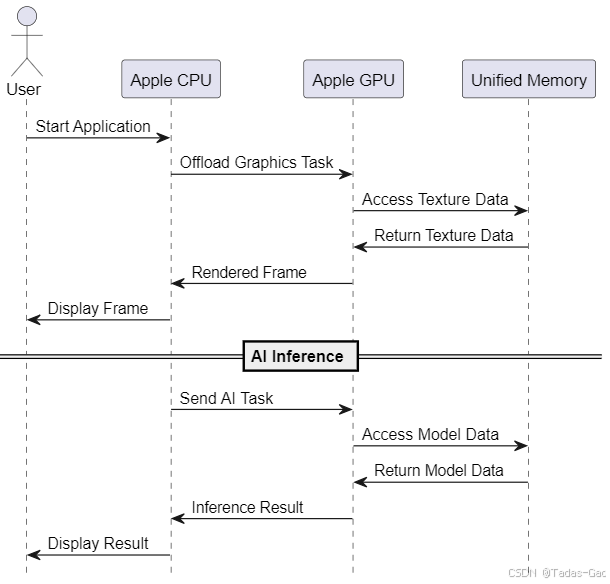
什么是统一内存架构(UMA)?
统一内存架构是一种计算机系统架构,其中CPU和GPU共享同一块物理内存。这种设计消除了不同计算单元之间的数据传输瓶颈,提高了整体系统的效率和性能。UMA的主要优点包括减少延迟、提高带宽利用率和简化编程模型。
苹果公司的统一内存架构
苹果在其基于M1、M1 Pro、M1 Max以及最新的M4芯片的Mac产品中采用了统一内存架构。这些芯片采用了高度集成的设计,将CPU、GPU、神经引擎(Neural Engine)、内存和其他组件集成在一个单一封装内。
-
高带宽低延迟内存:苹果的统一内存架构使用了高带宽低延迟的内存,确保CPU和GPU可以快速访问数据。这大大提高了系统的响应速度和计算效率。
-
共享内存池:所有计算单元共享同一个内存池,避免了传统架构中数据在不同内存之间复制的开销。这种设计不仅提高了性能,还简化了编程模型,使得开发者可以更容易地优化应用程序。
-
高度集成的系统封装(SoC):苹果的SoC设计将多个计算单元紧密集成在一起,缩短了数据传输路径,进一步减少了延迟。
Intel的内存架构
Intel在其处理器中也采用了类似的高带宽内存技术,如HBM(High Bandwidth Memory),并在其Xe架构中实现了一定程度的统一计算。然而,Intel的传统架构中,CPU和GPU仍然主要依赖于各自独立的内存,尽管通过共享虚拟内存和高速缓存来提高效率,但在完全统一内存方面与苹果的解决方案相比还有一定差距。
AMD的内存架构
AMD的Heterogeneous System Architecture(HSA)是其统一内存架构的核心。HSA允许CPU和GPU共享物理内存,并通过Infinity Fabric实现高效的数据传输。虽然HSA在一定程度上实现了统一计算,但在内存带宽和延迟方面,与苹果的高带宽内存设计相比,仍存在一些技术差异。
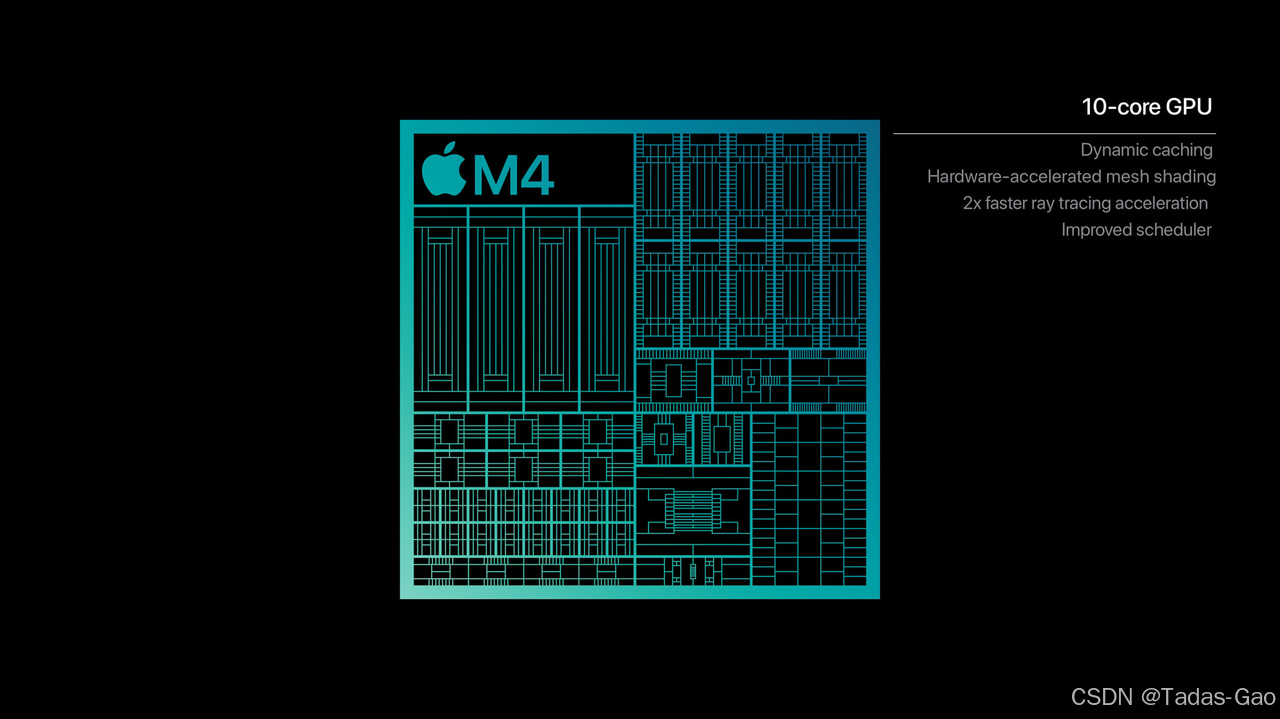
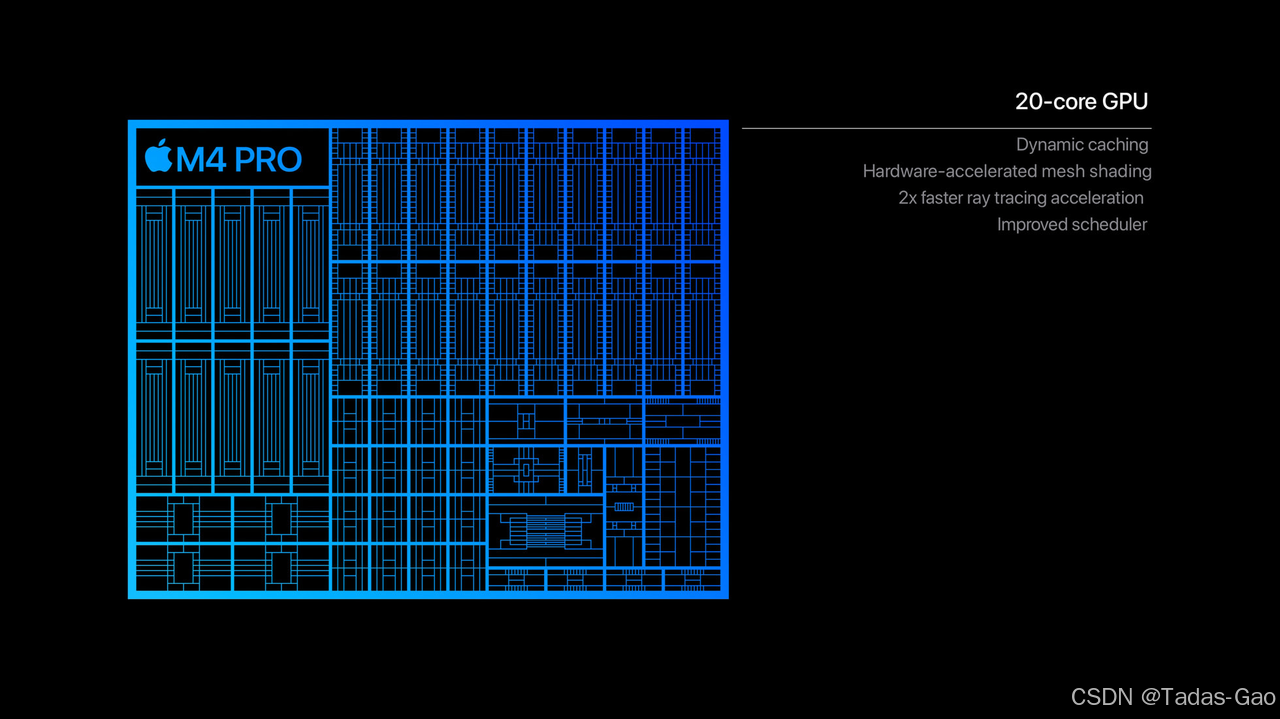
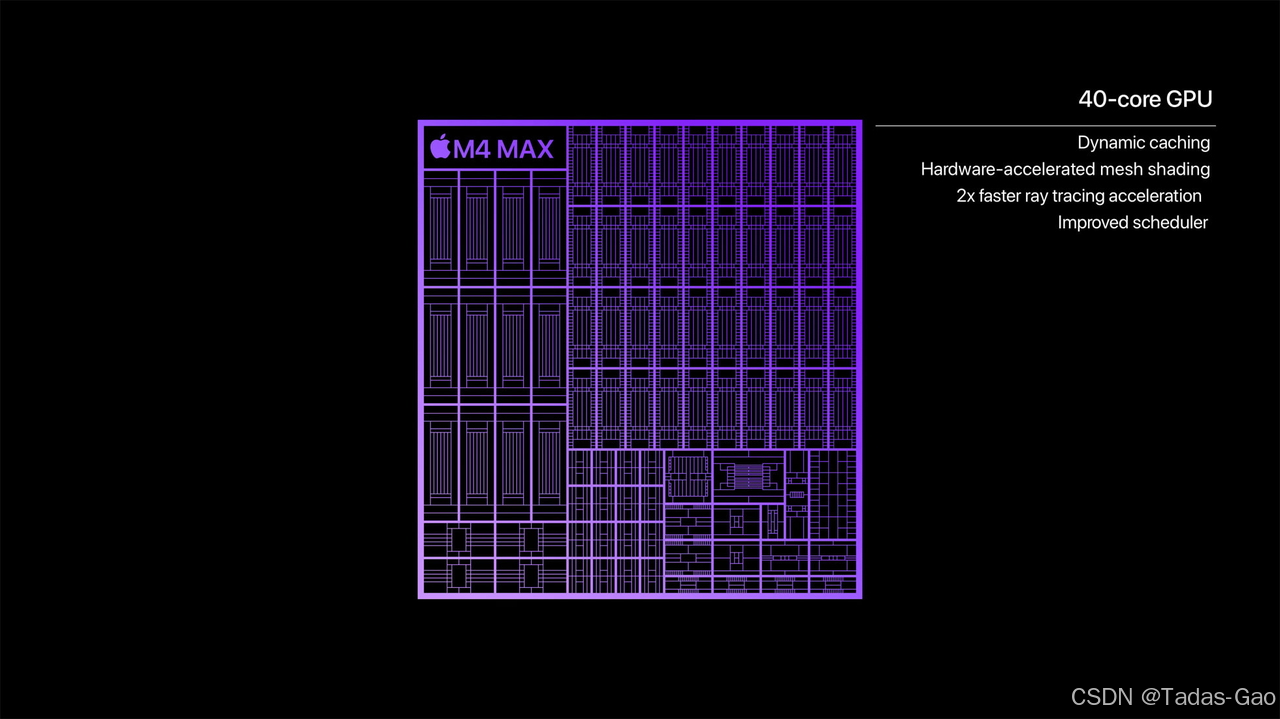
M4 Max 芯片支持最高 128GB 高速统一内存和最高 546GB/s 内存带宽,内存带宽是最新型 AI PC 芯片的 4 倍之多,使开发者可轻松与拥有近 2000 亿参数的大语言模型进行交互。
M4系列的GPU还新引入了Dynamic Caching,也就是动态缓存。传统GPU还在根据最大任务需求提前预留内存呢!M4已经可以根据实际需求动态调整局部内存使用了,GPU平均利用率大幅提升。这个技术本身对开发者透明,也就是说,专业级的app可以更加充分发挥GPU的性能了。

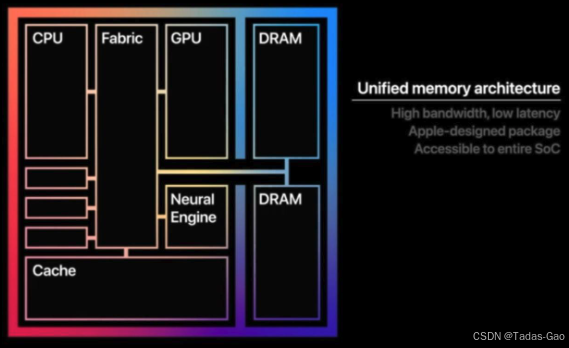
简单来说,苹果这个UMA架构指的就是内存和SoC上的各个专用处理器通过Fabric实现互联,达到各个专用处理器都可以快速访问内存,甚至是访问同一块内存而设计的全新架构。
CPU、GPU、NPU、视频引擎等处理器的内存不再是物理层面独立的内存块,在这个架构下不同专用处理器可以访问同一块内存区域。
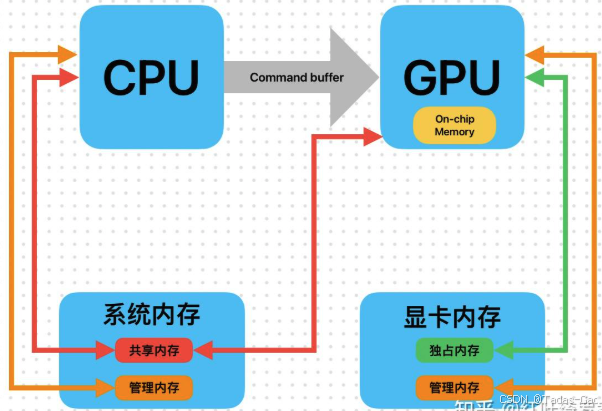
传统PC的CPU和GPU还在通过总线互相拷贝数据。显卡本身有着自己独立的内存,CPU处理的一些系统内存数据需要拷贝到显卡内存继续处理,整个处理过程存在各种数据同步。
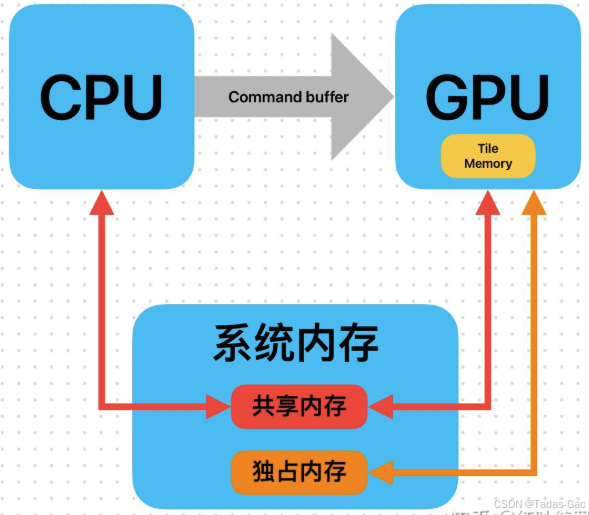
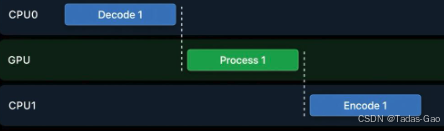
CPU和GPU有着一大块共享内存,这部分数据CPU和GPU随时都可以按需直接使用。当然,GPU也依然会有部分自己独占的内存。在这套架构下,CPU0处理完的数据交给GPU处理,GPU处理完交给CPU1处理,整个过程不需要任何内存数据拷贝。
说到CPU和GPU都能使用这个DRAM,肯定有人已经开始好奇了,那是不是意味着这些DRAM可以用作GPU的显存呢?答案是肯定的。UMA架构下,GPU就是直接拿系统内存当显存用的。一旦意识到这一点,其实基本也就不会吐槽苹果的金子内存了!因为当你把它当显存用的时候,那可比给显卡加内存便宜太多了。

而且更关键的是,对于Apple Silicon M系列芯片而言,DRAM可以做到拿出2/3以上当成显存使用。比如32GB版本的MacBook,可以拿出21GB当成显存,64GB则可以拿出48GB当显存。

M4 Max支持128GB的大内存,显存预估能够达到85GB以上。而消费级显卡天花板 RTX 4090(1.5 - 2 万元),也仅仅给到了 24GB 显卡内存;RTX5090(1.7 万元起),也仅仅给到了 32GB。即使是 RTX 6000 Ada(稳定在 4.7 万元),显存也只给到了 48GB。
带宽也很重要,再来谈谈带宽。高带宽意味着短时间内可以向内存读写更多的内容,在处理重度任务时比较有优势,比如视频渲染、大模型训练等等。
M1 Pro和M2 Pro都做到了200GB/s的内存带宽,M1 Max和M2 Max则做到了400GB/s 的内存带宽,M1 Ultra和M2 Ultra更是做到了800GB/s的内存带宽。
M3 Max(10P + 4E)版本采用的是300GB/s内存带宽,M3 Max(12P + 4E)版本才是400GB/s内存带宽。相较于传统PC架构下,比较不错的双通道DDR5,差不多也就是76GB/s的内存带宽。实际上,很多人用的还都是DDR4,双通道也就50GB/s的内存带宽。M4 Max 的内存带宽达到了惊人的546GB/s,干重活的能力非常厉害。
这是个什么水准?高通对标M2 Max的X Elite,借助高频的LPDDR5x,也才把内存带宽做到136GB/s,而苹果M2 Max做到了400GB/s。
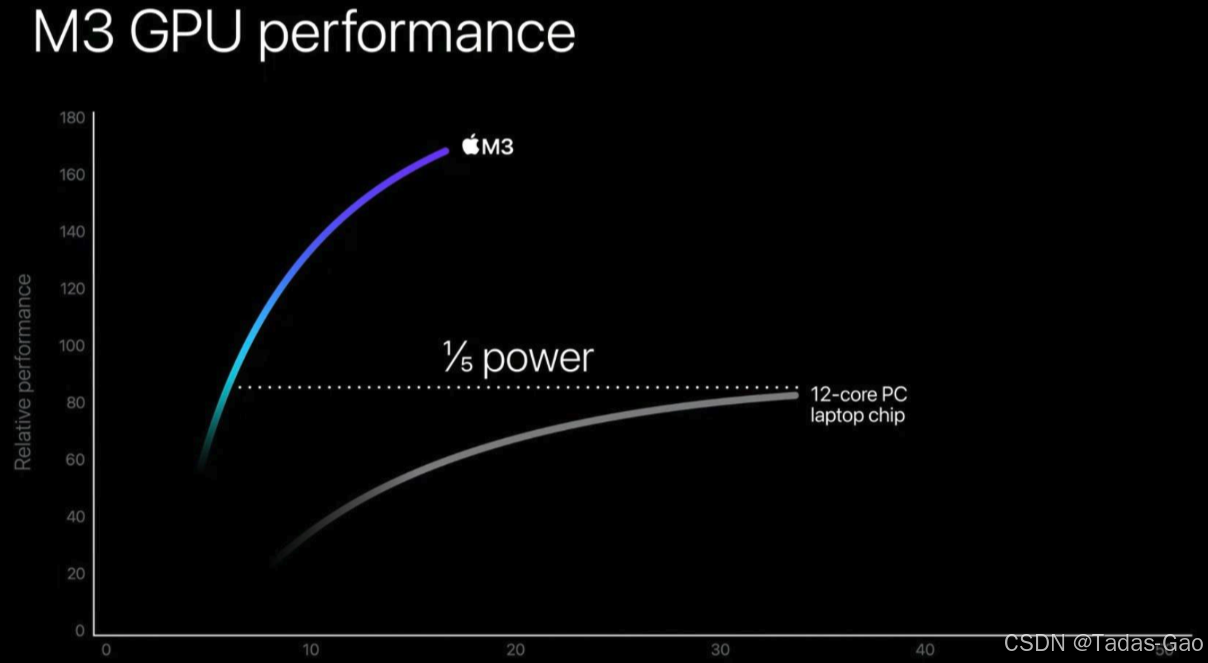
功耗上来讲,对标同类笔记本,M系列芯片基本只要1/4甚至1/5的功耗,就能达到同样的性能了。
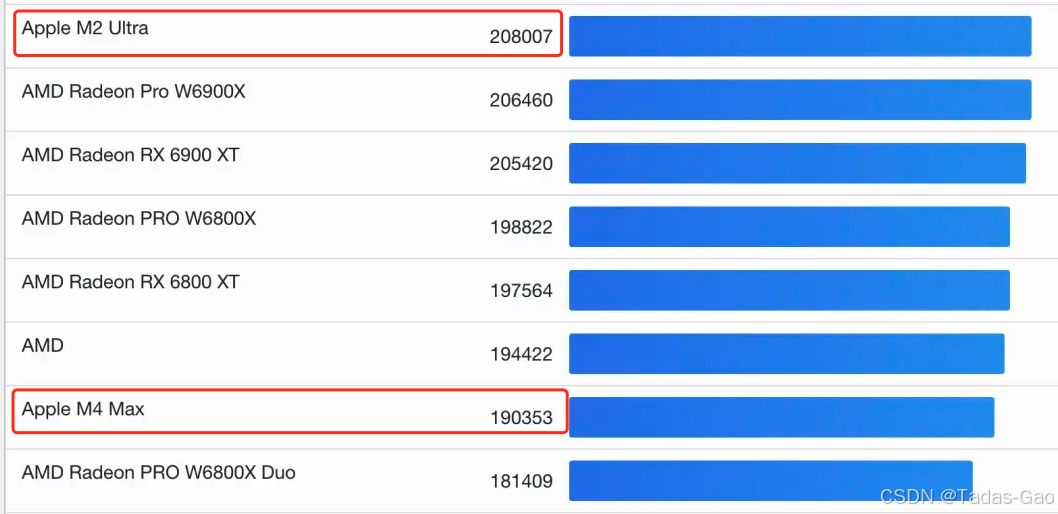
M4 Max的GPU Metal跑分很高,离M2 Ultra只差一点点了。所以说,M4 Max就是性能怪兽,无论是CPU还是GPU都非常变态。



















 5206
5206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











