




CPU 与 GPU
CPU 的处理⽅式以“顺序处理”为主。也就是说,CPU 会逐步、⼀条接⼀条地执⾏指令,这与并⾏处理不同。虽然多核技术和超线程技术可以在⼀定程度上缓解这种顺序处理的局限,但它并不是为⼤规模并⾏计算设计的。相⽐于能够⼀次处理⼤量数据的图形处理器(GPU),CPU 更适合处理复杂且需要精确计算的任务。
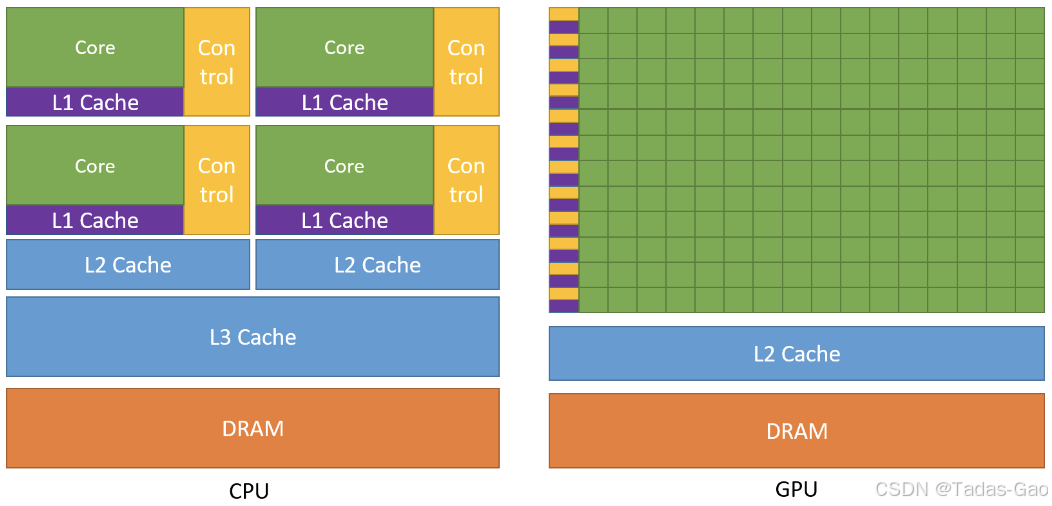
GPU 的架构设计⾮常独特,由成百上千个⼩型处理单元组成,每个处理单元能够独⽴并⾏执⾏指令。这种⾼度并⾏的处理能⼒使 GPU 能够同时处理海量数据,这也是其与多核 CPU 的相似之处。CPU 虽然也有多核设计,但每个核⼼的任务通常是串⾏执⾏的。⽽ GPU 的每个⼩型处理单元(通常称为“流处理器”或“CUDA 核⼼”)则可以相互并⾏执⾏不同的指令集,使得 GPU 能够在短时间内处理⼤量计算任务。
如果说CPU像一个精明强干的项目经理,那GPU就是一个拥有成百上千“螺丝钉工人”的大型流水线。

| CPU | GPU | |
| 核心数量 | 少(一般4~16个) | 多(上千个计算单元) |
| 主频 | 高 | 相对较低 |
| 并行能力 | 弱 | 强 |
| 适合任务 | 串行 | 并行 |
| 应用场景 | 通用计算、操作系统等 | 图形渲染、AI 计算、深度学习等 |
大模型为什么要用 GPU
GPU和CPU之间的主要区别在于设计思想的不同。CPU的设计初衷是为了实现在执⾏⼀系列操作时达到尽可能⾼的性能,其中每个操作称之为⼀个线程,同时可能只能实现其中数⼗个线程的并⾏化,GPU的设计初衷是为了实现在并⾏执⾏数千个线程时达到尽可能⾼的性能(通过分摊较慢的单线程程序以实现更⾼的吞吐量)。
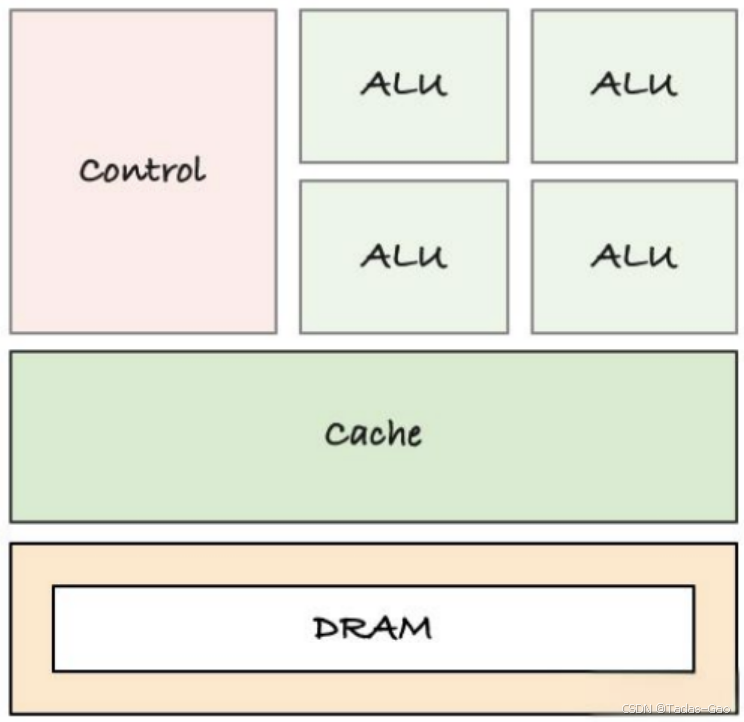
为了能够实现更⾼强度的并⾏计算,GPU将更多的晶体管⽤于数据计算⽽不是数据缓存或控制流(扩展阅读:模型到底要用多少GPU显存?)。
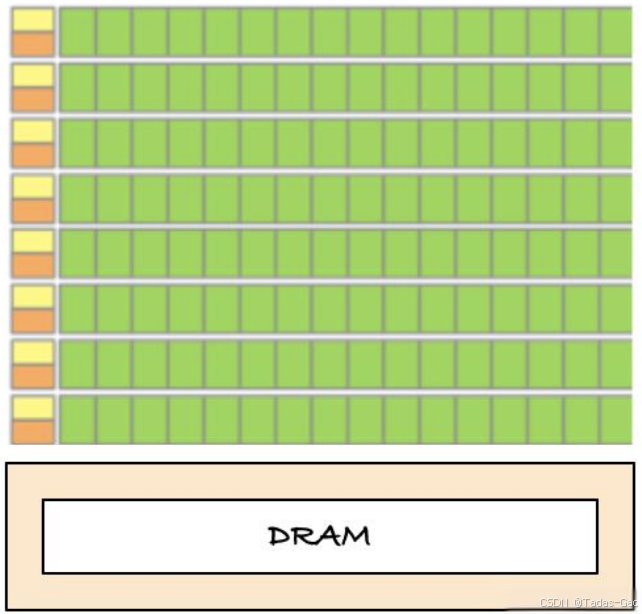
下图显示了CPU 与 GPU 的芯⽚资源分布示例。
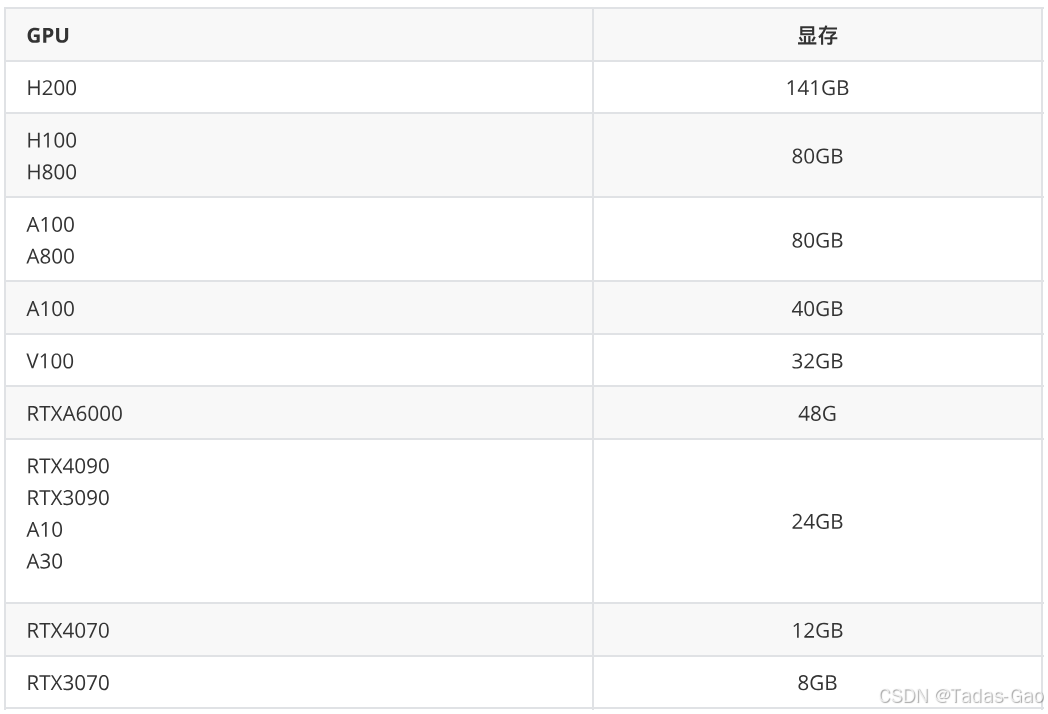
GPU 怎么选
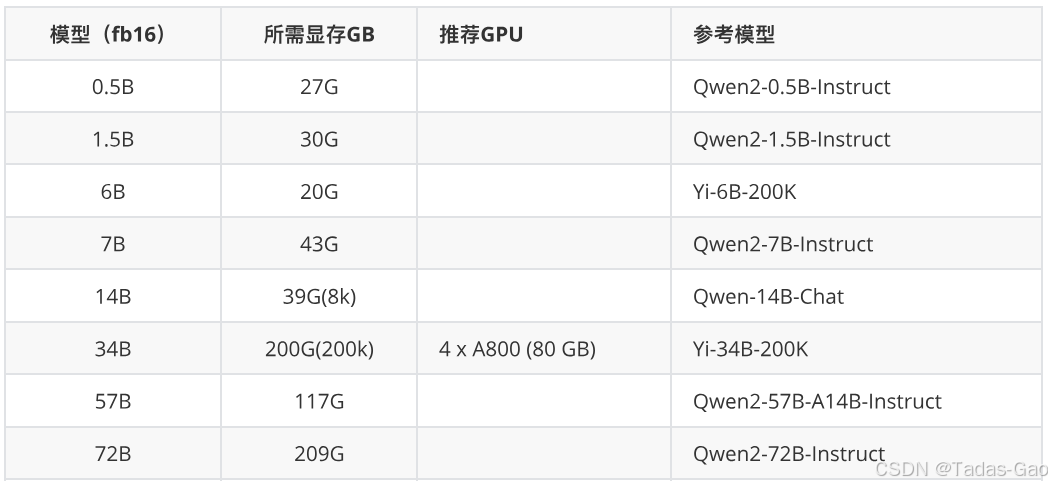
根据任务的规模和类型选择硬件:
-
应⽤场景:是⽤于深度学习训练、推理,还是科学计算、图形渲染?
-
模型规模:需要⽀持多⼤的模型(如⼏亿到⼏百亿参数)?
-
性能要求:对计算速度、吞吐量或延迟的要求是什么?
-
预算限制:硬件预算范围是多少?
-
软件兼容性:是否需要⽀持特定的框架(如TensorFlow、PyTorch)或CUDA版本?
如果任务计算密度更高(如 AI 训练、推理),GPU 优势会更明显。
一个简单的例子来对比下 CPU 和 GPU 的计算效率。
一张一亿像素的图片需要渲染,用 CPU 和 GPU 分别需要多长时间?
CPU 计算
若使用16核CPU(假设CPU频率5.0 GHz)+ Intel AVX-512(16个像素/指令),处理1亿像素的理论最低周期数为:完美并行化(无竞争、无调度开销)
假设每像素需读写 100 字节,内存时间:
实际时间受限于:
-
内存带宽(DDR4约51.2 GB/s)
-
指令调度效率
-
缓存命中率(L1/L2/L3缓存影响)
GPU 计算
如A100 GPU(假设1.41 GHz,显存带宽1555 GB/s)有6912个CUDA核心,将1亿像素划分为线程块(如每块256线程)
A100的每个处理器每周期完成1个调度(32线程)
-
A100 SM(Streaming Multiprocessor)数量:108个
-
每SM的调度器:4个
-
每周期每SM可执行:
-
默认假设 1个调度(32线程)/周期/SM
-
每个Warp覆盖 32像素。
-
假设每像素需读写 100 字节,显存时间:


















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











