




符号主义 AI(1950 - 1980):基于规则和逻辑推理,依赖人工编写的知识库
符号主义 AI(Symbolic AI)是人工智能发展早期的重要范式,其核心思想是将人类认知抽象为符号操作和逻辑推理。
基于手工设计的规则系统;少量规则集;无法从数据中自动学习;基于专家知识和规则的系统设计
理论基础形成(1950s-1960s)
符号主义的理论基础源于数学逻辑和计算理论。艾伦·图灵提出的通用计算机概念为符号操作提供了理论基础。1956年达特茅斯会议上,约翰·麦卡锡等人明确提出了"人工智能"概念,早期研究集中在:
- 逻辑推理系统:如纽厄尔和西蒙的逻辑理论家(Logic Theorist),首次实现自动证明数学定理。
- 知识表示:采用谓词逻辑(如FOPL)形式化知识。
当时的科学家认为,世界的一切都可用函数来表示(精确表达这个世界):functions describe the world
但事实证明,人类还是太菜了:猫狗识别、翻译等人类很容易做到的事情,机器学习很难学会,找不到一个精确的函数来解决这个问题。
至此,科学家发现,这个世界并不是线性的。因此,开始放弃符号主义,靠着连蒙带猜,诞生了连接主义(差不多就行了,不需要那么精确):手写数字识别
科学家发现,还挺强大,在手写数字识别等案例中表现良好。此时,大家开始重视,并转入神经网络技术(线性变换 + 激活函数 -> 非线性变换)。科学家发现,这个世界其实很复杂,很多东西并不能用简单的线性函数来表示,需要找到非线性的表达。
对于数据,假设符合线性关系,怎么找到最合适的
和
?就是通过损失函数来判断。
专家系统黄金期(1970s-1980s)
知识工程成为主流,专家系统通过规则库模拟人类专家决策:
- MYCIN(1976):医疗诊断系统,使用500条产生式规则,准确率超人类专家。
- DENDRAL(1965-1980):化学分子结构分析系统,展示了领域知识的重要性。
- 开发工具:如CLIPS规则引擎,采用Rete算法加速模式匹配。
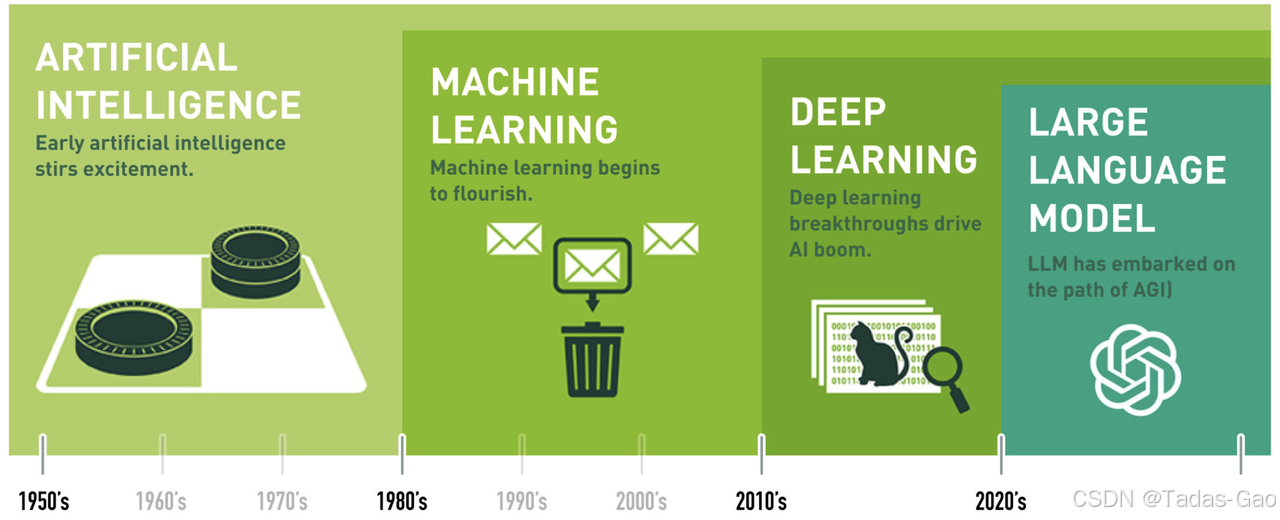
统计机器学习(1980 - 2010):数据驱动,基于概率统计优化模型参数
SVM、决策树、随机森林、贝叶斯网络;百万级标注数据;依赖特征工程(需人工提取特征);统计机器学习算法
方法论突破(1980s-1990s)
符号主义与其他范式融合,出现重要方法论:
- 语义网络和框架理论:更结构化的知识表示方法
- 本体论工程:如Cyc项目尝试构建常识知识库
- 多智能体系统:基于符号推理的分布式协作
深度学习(2010 - 2020):端到端学习,自动提取特征,依赖大规模数据和GPU计算
深度神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN);十亿级标注数据;深度神经网络
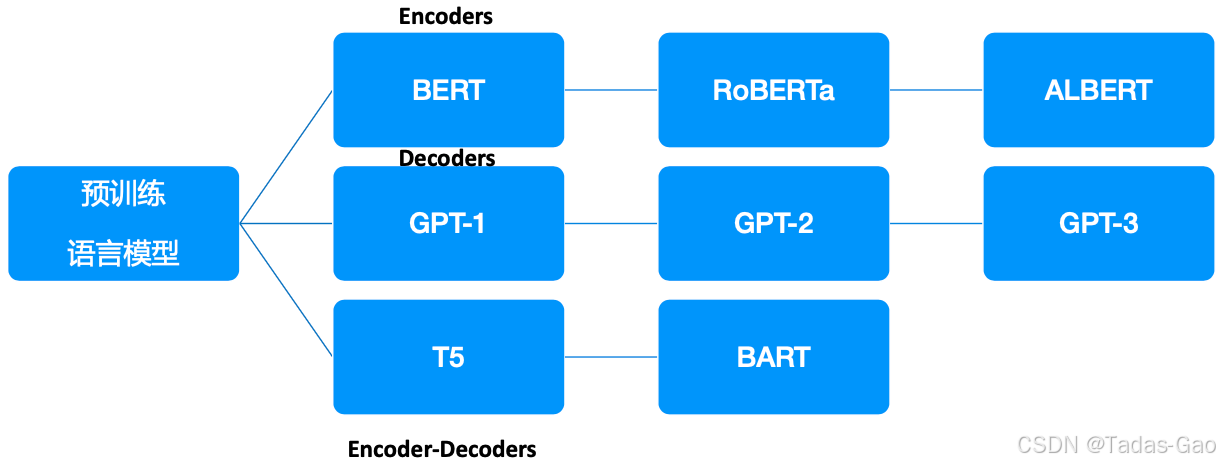
预训练(2018 - 2020)
Transformer、GPT、BERT;数千亿未标注数据;预训练、全量微调
大语言模型(2020 - 至今):超大规模预训练 + 自监督学习 + 多模态融合
GPT-3.5、GPT-4等;更大规模用户数据;提示词微调、指令微调、强化学习优化(RLHF)
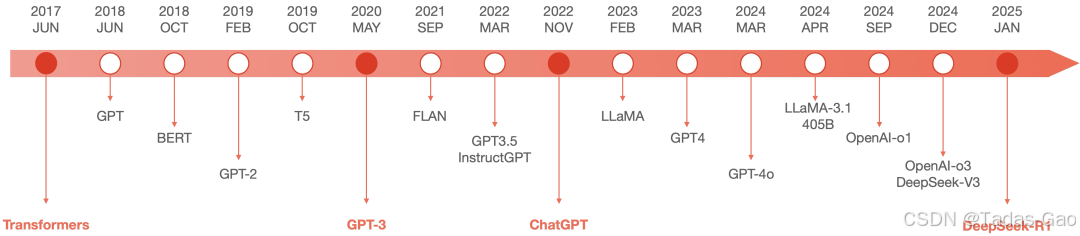
大模型进入加速发展和演进时期。
-
Transformer:理论架构创新
-
GPT-3:预训练时代:大力出奇迹
-
BERT、GPT
-
自监督算法:解决海量数据标注问题
-
涌现能力
-
-
ChatGPT:人工智能的iPhone时刻
-
以自然语言为接口,将专业知识平民化,使个体创造力得到指数级释放
-
-
DeepSeek-R1:多模态
-
LLaMA系列
-
GPT-4v:视觉语言(跨模态)
-
GPT-4o:全模态前沿( 交互能力)
-
OpenAI-o1/o3:推理能力的一大飞跃
-
| 代际 | 核心技术 | 典型模型 | 关键突破 |
| 第一代(符号AI) | 规则引擎、专家系统 | DENDRAL、Prolog | 逻辑推理 |
| 第二代(统计ML) | SVM、决策树 | 随机森林、贝叶斯网络 | 数据驱动 |
| 第三代(深度学习) | CNN、RNN、Transformer | ResNet、AlphaGo | 自动特征学习 |
| 第四代(大模型) | LLM、MoE、多模态 | GPT-4、Llama 4 | 零样本学习、推理优化 |
未来可能进入第五代(具身智能/世界模型),进一步结合机器人、多模态交互和自主决策。具身智能可能是第四代向第五代的过渡技术,因为当前具身智能仍依赖大模型作为“大脑”,尚未完全实现自主适应与进化。未来真正的第五代AI可能结合具身智能、脑机接口、世界模型等,实现更接近人类的全场景自主智能。
此处稍微扩展一下通用人工智能(AGI Artificial General Intelligence)。
AGI指具备人类水平的多领域认知能力、自主学习和推理能力的AI,不属于当前任何一代,而是未来目标。其关键特征包括:
-
自主性:无需人类干预即可设定和完成目标。
-
适应性:应对未知场景的能力。
-
多模态理解:跨视觉、语言、行动等统一认知。
当前大模型(如ChatGPT)虽能处理多任务,但本质仍是统计模式匹配,缺乏真正的理解与推理,属于第四代技术,而非AGI。如果将大模型视为第四代,AGI则属于更远的“第五代”或超越现有分代框架的逻辑。目前尚无被广泛认可的AGI实现案例,技术路线尚不明确(可能需类脑计算、具身智能等新的范式)。
-
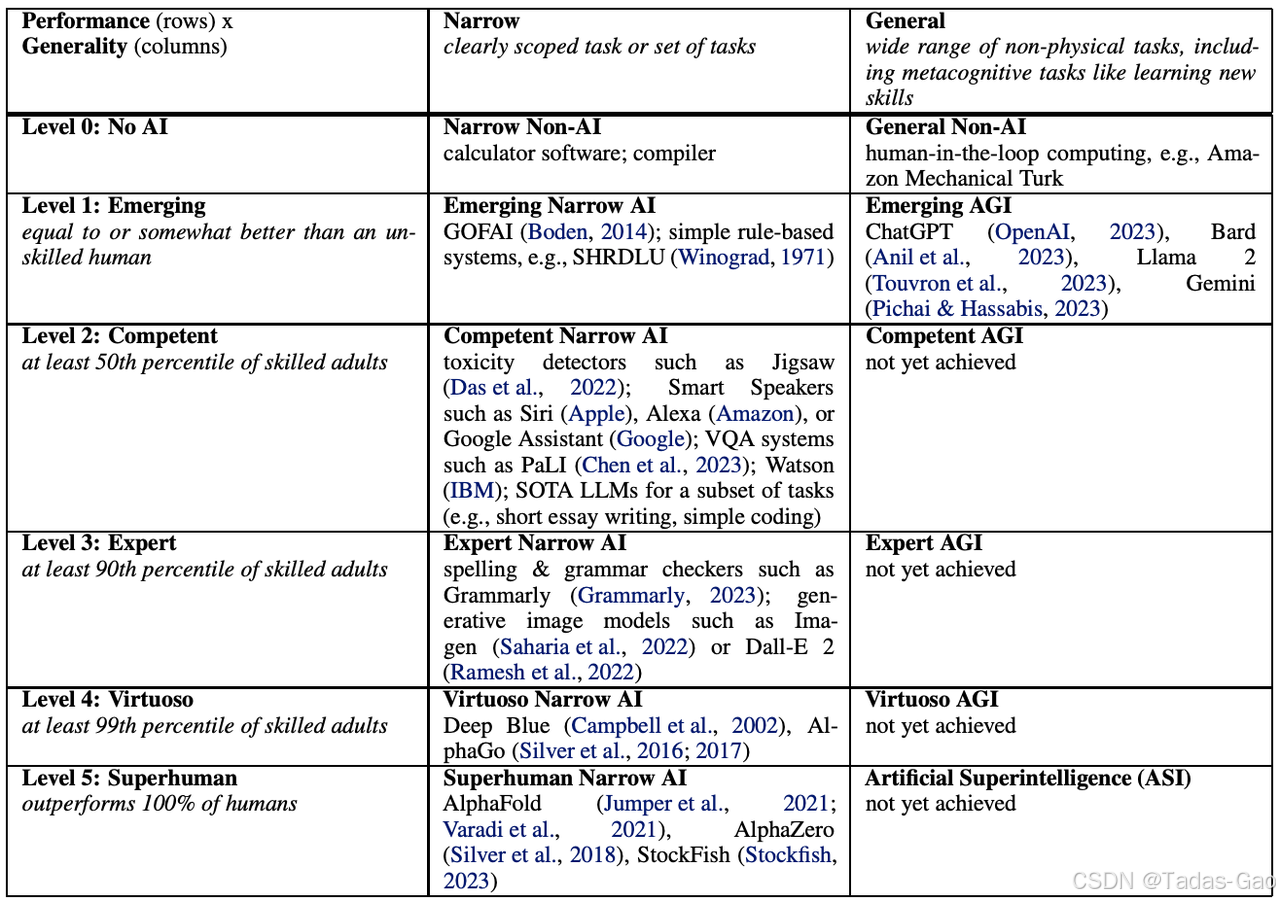
No AI(无AI):如Amazon Mechanical Turk,这一级别实际上没有AI的存在。
-
Emerging(涌现):这一级别的AI与不熟练的人类相当或更好,如ChatGPT、Bard、Llama 2,它们开始展示出一定的常识推理能力。
-
Competent(有能力):达到50%的人类水平,广泛任务上还没实现。这一级别的AI需要在更广泛任务集上提高性能才能达到。
-
Expert(专家):到达90%的人类水平,广泛任务上还没实现。Imagen、Dall-E 2在特定任务上已经实现这一级别。
-
Virtuoso(大师):达到99%的人类水平,在广泛任务上还没实现。Deep Blue、AlphaGo在特定任务上已经实现这一级别。
-
ASI(Artificial Superintelligence,人工超智能):超越100%的人类水平,完成广泛的任务。这是AGI的最高等级,代表了超人类的智能。
目前 AGI 整体还处于 Level 1 的水平,真正的AGI(Level 3及以上)仍需数年(乐观派预计10 年,悲观派预计需数十年)甚至更长时间(还需解决很多问题,比如伦理与法律问题、算力能源问题、技术瓶颈等)。
首席AGI科学家Shane Legg:2028年,人类有50%的概率开发出第一个AGI雏形。
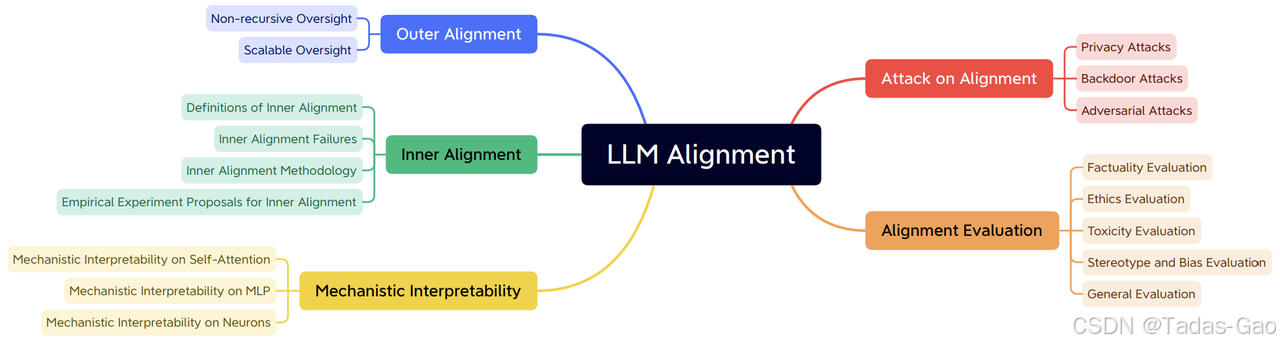
提到 AI 的风险问题,再稍微扩展一下大语言模型的对齐技术。
大语言模型对齐(Large Language Model Alignment)是利用大规模预训练语言模型来理解它们内部的语义表示和计算过程的研究领域。主要目的是避免大语言模型可见的或可预见的风险,比如固有存在的幻觉问题、生成不符合人类期望的文本、容易被用来执行恶意行为等。
从必要性上来看,大语言模型对齐可以避免黑盒效应,提高模型的可解释性和可控性,指导模型优化,确保AI 技术的发展不会对社会产生负面影响。
目前的大语言模型对齐研究主要分为三个领域:外部对齐、内部对齐、可解释性。




















 3467
3467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











