



LLM 不只是单一模型,而是整个AI 生态链的核心。
今天,我们来看看RNN、Encoder技术最终累积导向的成果:LLM(Large Language Model)大型语言模型。
从RNN 到Transformer
这边稍微回顾一下深度学习模型架构:
-
RNN(Recurrent Neural Network)
- 特点:逐步处理序列资料
- 问题:长距离的文字关系比较难捕捉、训练时间比较长
-
Encoder–Decoder 架构
- 应用:翻译、摘要等序列转换任务
- 优点:分为Encoder(编码器)与Decoder(解码器)两个阶段
-
Transformer
- 能平行化运算(加快训练速度)
- 擅长捕捉长距离关系
- 核心:使用Self-Attention机制,同时考虑整句话的所有词。
- 优点:
- 搭配Positional Encoding,补足模型对「词序」的理解。
- Transformer 是现代LLM 的大大基石。
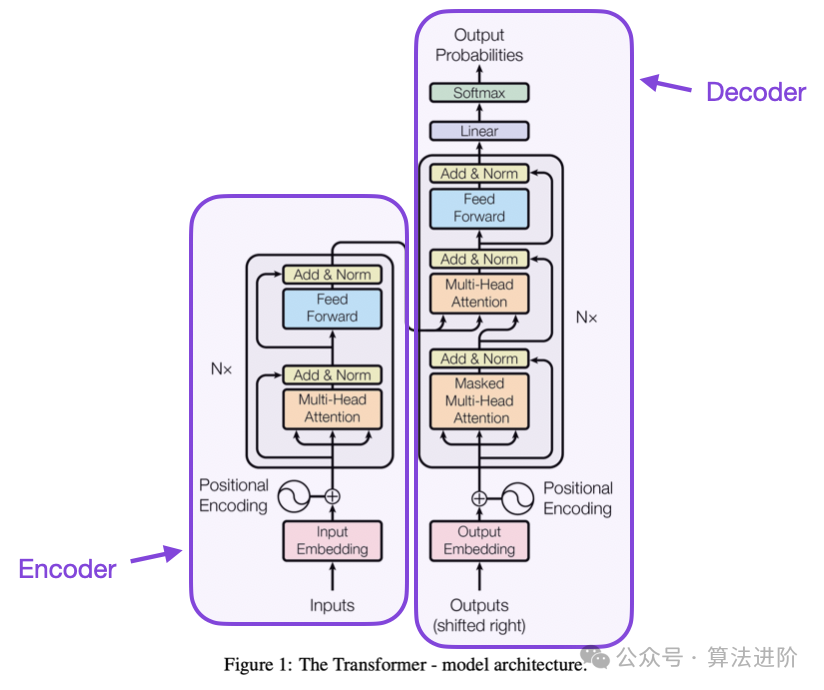
Transformer 架构概述
Transformer 采用「编码器(Encoder)」与「解码器(Decoder)」结构。例如将英文句子“This is an example” 翻译成德文“Das ist ein Beispiel”:
编码器(Encoder):将输入文字转换成对应的嵌入向量(Embedding)。
解码器(Decoder):根据已翻译部分(如“Das ist ein”),逐步生成下一个字(“Beispiel”)。
为什么要用Self-Attention?
在Transformer论文,作者说明了Self-Attention 的动机与计算优势,并与CNN 进行比较。其一大优点是:Self-Attention 具备可解释性(Interpretability)。不同的注意力头(Attention Head)倾向捕捉不同层次的语法或语意结构,这让模型不仅能学习上下文关系,也能展现语意层面的理解。
Transformer 与GPT 架构的差异
GPT 架构仅采用Transformer 的Decoder 部分,不包含Encoder。
模型会在每次迭代时产生一个新字,并将其作为下一次的输入。
Attention 机制是什么?
简单来说,Attention 机制是让模型在处理输入Token 嵌入时,考虑上下文关系的方式。以句子“Your journey starts with one step” 为例,「journey」的语意会根据上下文改变:
若搭配“travel”,是「实际旅程」;
若搭配“one step”,则是「人生旅程」。
模型透过Attention 来「关注」这些关联,进而判断词义。
Attention 的数学基础
Attention 的核心计算是Query与Key向量的内积(dot product),代表两者的相似程度。再经过Softmax 正规化,得到对每个Token 的「注意力分数(Attention Score)」。最后将各Token 的Value 向量按权重加总,形成Context 向量,代表该词在整句中的语境意义。
Scaled Dot-Product Attention(缩放点积注意力)
实际论文中的Attention 计算采用「缩放点积注意力」:

这里的frac{1}/{sqrt{d_k}} 是为了防止维度过高造成Softmax 梯度消失,使模型更稳定。
Multi-Head Attention(多头注意力)
Transformer 并非仅使用一组Attention,而是同时并行多组Scaled Dot-Product Attention。这让模型能从不同的语意角度关注资讯,进而提升准确度。
Masked Attention(遮罩注意力)
在Decoder 阶段,模型需要「自回归(Autoregressive)」地生成文字。因此,当模型预测下一个字时,只能关注当前与过去的Token,而不能偷看未来的字。 这透过在Attention 中加入遮罩(mask)实现。
LLM 是什么?
LLM,全名为Large Language Model(大型语言模型),是基于Transformer 架构、使用巨量文字资料训练而成的模型。
不过,它的核心任务仍然是:「预测下一个词」。
这项看似简单的任务,却演变成如今非常非常强大的语言模型能力🤯
LLM 的几个关键要素
- 巨量参数(Parameters)
- 模型规模从几百万个参数(RNN 时代)提升至数千亿个参数(GPT-5、Claude、Gemini 等)。
- 每个参数都代表模型对语言的一种「微小的理解」。
- 庞大训练资料(Data)
- 来源包括:维基百科、书籍、网页、对话、程式码等。
- 目标是让模型学会语言规则、语意关系、常识知识。
- 强大的运算资源(Compute)
- 利用GPU/TPU 进行数周甚至数月的训练。
LLM 的核心理念
虽然LLM 是「语言模型」,但它其实学到的不只是文字的规则。
在预测下一个词的过程中,模型同时学会了:
- 语法结构:知道句子怎么组成。
- 语意关联:理解不同词之间的语意距离。
- 世界知识:从大量文本中归纳出事实与常识。
- 推理能力:能在上下文中做出逻辑推断。
LLM 的强项与限制
- 理解能力:LLM 能够处理复杂的语意与上下文,但是有时候还是会误解指令,像是我之前在请LLM 帮我产出一段程式码的时候,它说的跟它做的东西就是不一样,甚至一直鬼打墙😤。我相信大家应该多多少少都有遇过类似的情形...
- 幻觉😵💫:LLM 虽然说有强大的能力,我们有想问的东西就会拿去给LLM 解答,但是有一点要注意的是LLM 可能会有Hallucination(幻觉)... 听起来很神秘吼,但其实这个幻觉就是在说LLM 可能会产出与事实不符的文字资讯。
- 为什么会有这样的情况发生呢? ➔ 因为LLM 基本上是从海量的资料在学习文字的规律,并根据学习到的东西,依据机率来去预测下个字,也就是说,它并不是在学「正确」的东西,而只是从被喂进去的东西当中再找出规律性而已
- 总而言之,很多人会以为LLM 提供的回答都是正确的,但是其实不尽然,因此这是要特别注意的地方哦~
- 非即时资料:一般来说,在训练模型的资料并不会是即时更新的,它都是有一定的时间限制,因此若不搭配网页搜寻的功能,很有可能得到的资讯就会不是最新的
LLM 的相关应用
LLM 不只是单一模型,而是整个AI 生态链的核心。
以下为环绕LLM 的一些应用与技术,包括:
- Chain-of-Thought(CoT):让模型「逐步推理」。
- RAG(Retrieval-Augmented Generation):让模型「查资料再回答」。
- Ollama:让使用者在本地执行开源模型,兼顾隐私与可控性
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









