




摘要:针对传统中文手写数字识别在多类别汉字数字(“零、一、二、三、四、五、六、七、八、九、十、百、千、万、亿”)上的识别精度与实用性不足问题,本文构建了一套面向 15 类中文数字的深度学习识别系统。首先,整理并标准化多来源手写样本,将数据统一为 64×64 的 RGB 图像格式,并按照训练集、验证集和测试集进行规范化划分,为后续模型训练与评估奠定了高质量数据基础。
作者:Bob(原创)
项目概述
为提升手写数学表达式录入的效率与易用性,本文设计并实现了一套基于深度学习的手写数学公式识别与计算系统。系统面向日常数学练习与简单公式输入场景,旨在通过自动识别手写数字和四则运算符,降低人工录入成本,提升人机交互体验。针对传统键盘录入复杂数学公式不便的问题,本文从图像处理、字符识别以及表达式解析三个方面进行综合设计与实现。
在方法层面,系统采用自构建的“mnist+”字符数据集,利用卷积神经网络(CNN)构建字符分类模型,并结合图像预处理与字符分割算法,实现对整张手写公式图像的自动拆分与识别。首先,通过灰度化、二值化、形态学开运算与轮廓分析,对输入图像进行字符级分割;随后,利用自定义 CNN 模型对单字符进行分类识别,并按从左到右顺序拼接生成可计算的数学表达式。为保证表达式计算过程的安全性与可靠性,系统引入基于正则校验的安全求值(safe eval)机制,仅允许数字、四则运算符及有限括号结构参与计算。在系统实现层面,本文基于 PyQt5 构建图形化用户界面,实现了公式图片上传、字符分割结果可视化展示、识别结果与计算结果显示、用户登录与权限管理以及识别日志记录等功能,并利用 SQLite 数据库对用户信息与检测记录进行持久化存储,同时提供训练损失曲线、准确率曲线与识别日志的可视化分析界面。
实验结果表明,所构建的字符识别模型在测试集上取得了 98% 以上的平均识别准确率,系统能够稳定、准确地识别常见数字及基本算符,并完成对应算式的自动计算,基本满足日常手写公式识别与计算的应用需求。该系统整体结构清晰、模块划分合理、易于扩展,可在此基础上进一步支持更复杂的数学符号体系、公式排版解析以及作业批改与智能教学等应用场景,为手写数学表达式的智能识别与人机交互提供了一种可行解决方案。
系统设计
本系统采用“离线训练 + 在线识别 + 可视化分析”一体化架构,基于 PyTorch 深度学习模型,通过 PyQt6 图形界面实现用户登录、中文手写数字识别以及检测与日志数据的统一管理与展示。
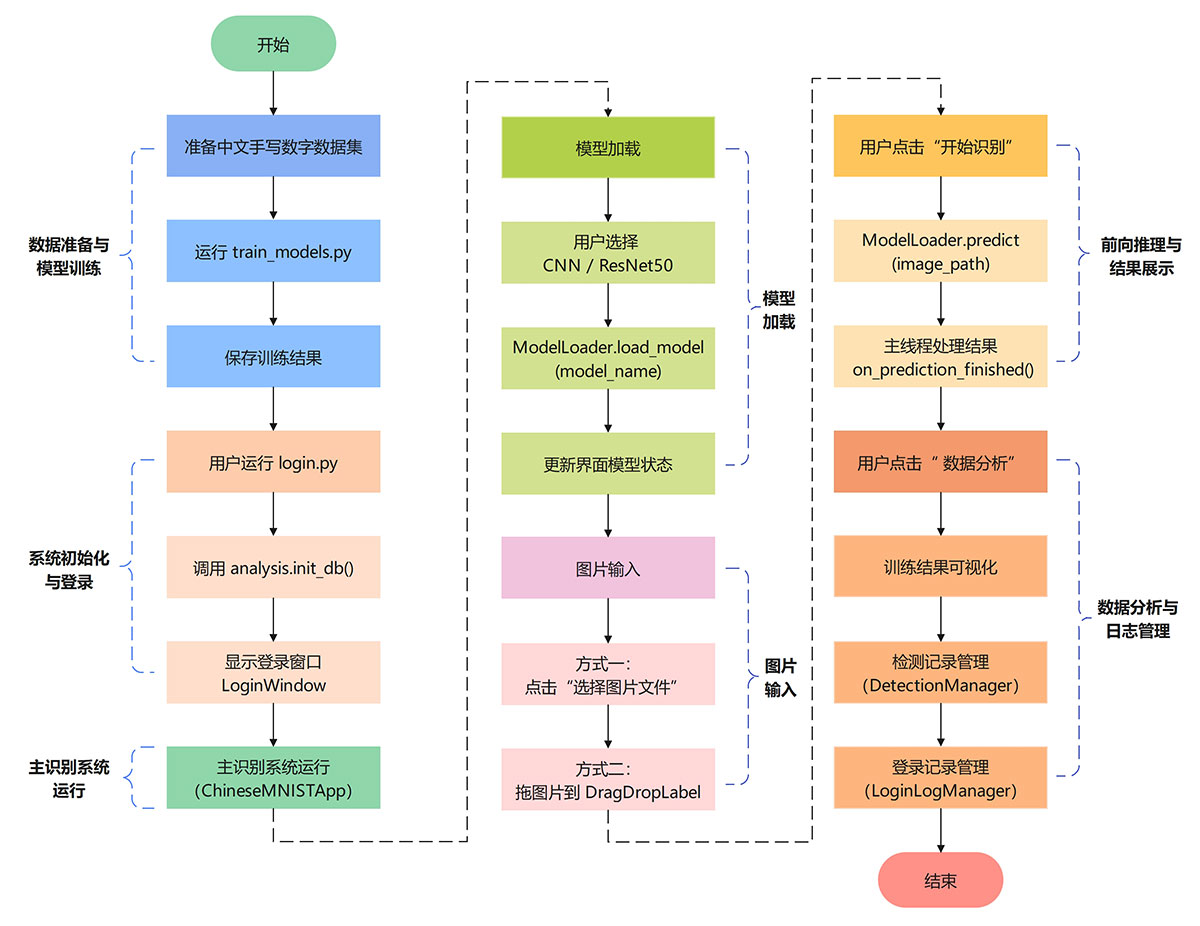
图1 系统整体流程图
硬件配置
该系统硬件配置如上,如果您的电脑配置低于下述规格,运行速度可能会与本系统的存在差异,请注意。

表1 惠普(HP)暗影精灵10台式整机配置(系统硬件配置)
软件环境
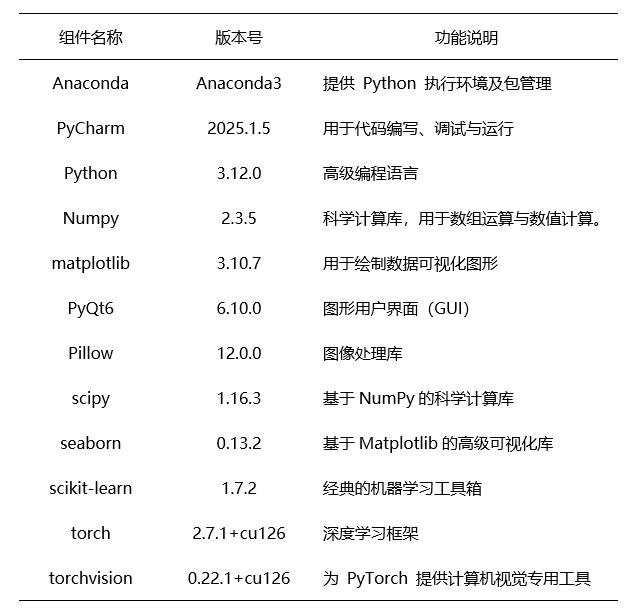
对本实验所需的各类软件及工具的基本信息进行了清晰汇总。
运行展示
运行login.py
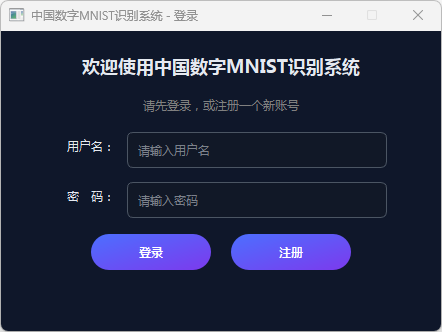
图2 注册登录界面
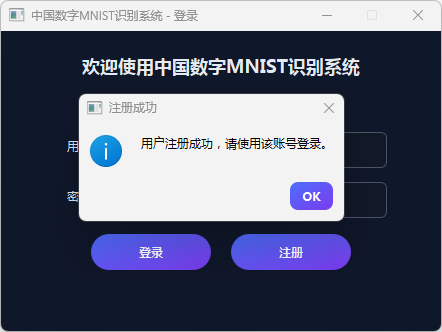
图3 注册成功
图4 系统主界面
CNN模型-手写数字识别
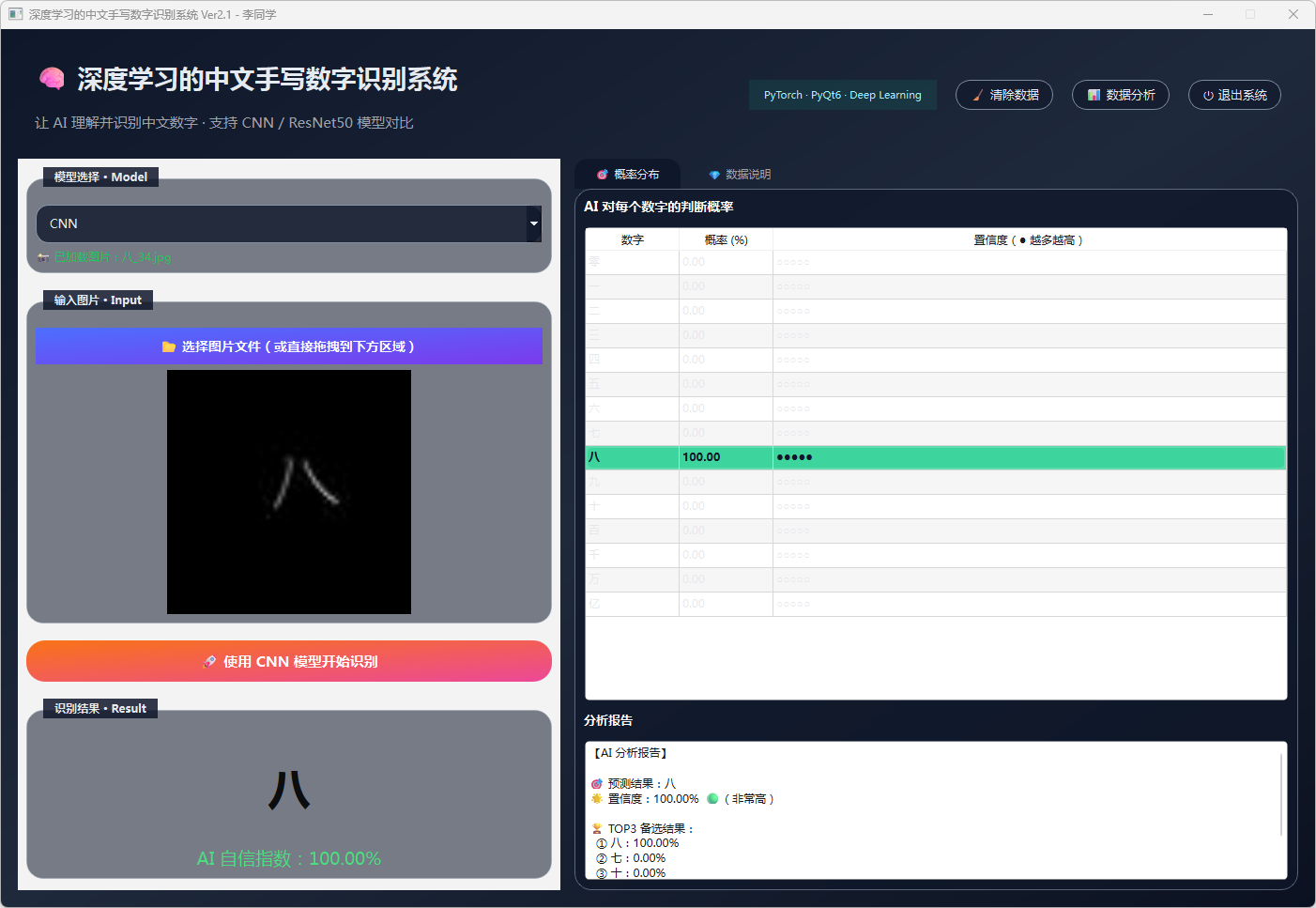
图5 手写数字-八
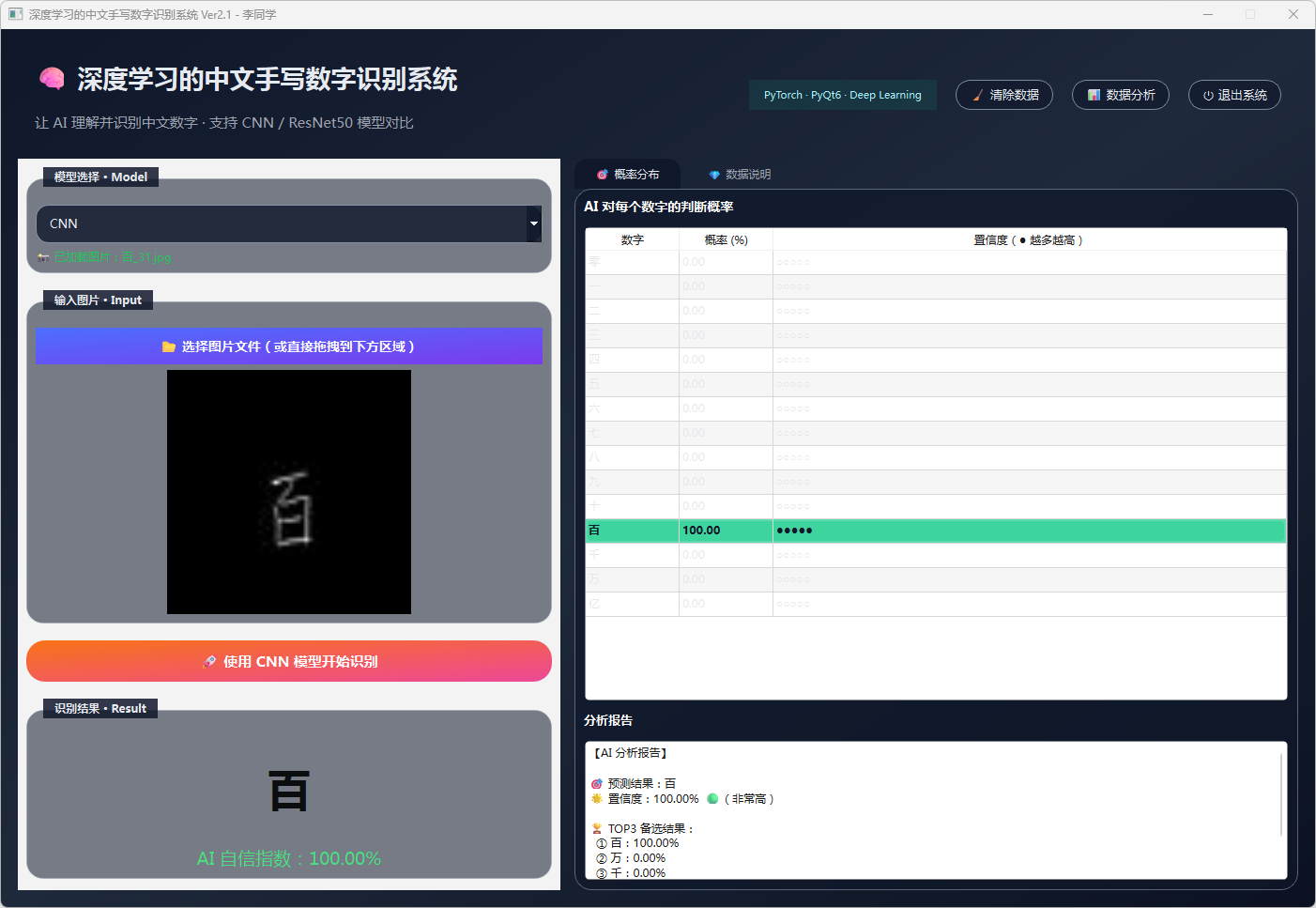
图6 手写数字-百
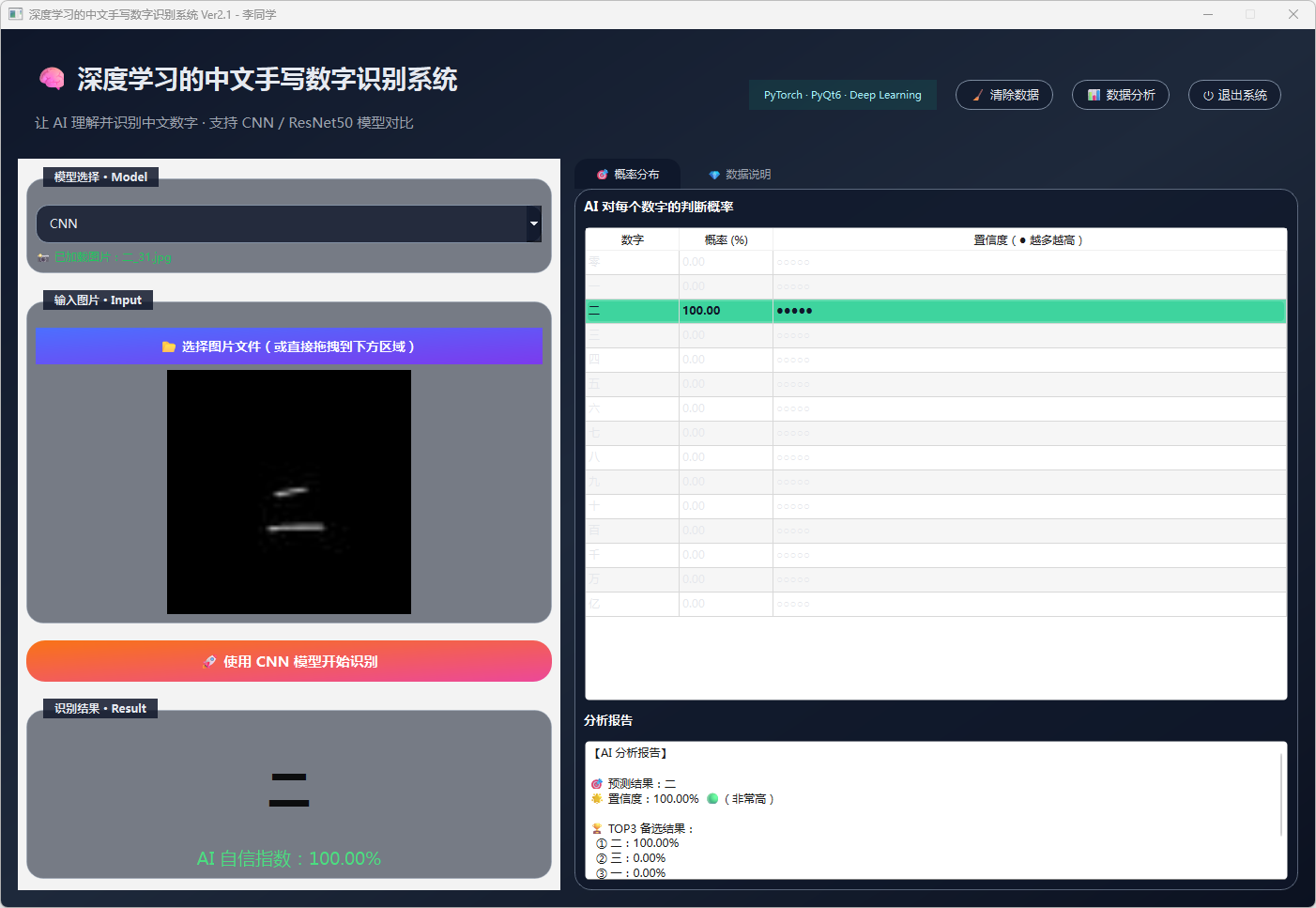
图7 手写数字-二
图8 手写数字-九
图9 手写数字-零
图10 手写数字-六
图11 手写数字-七
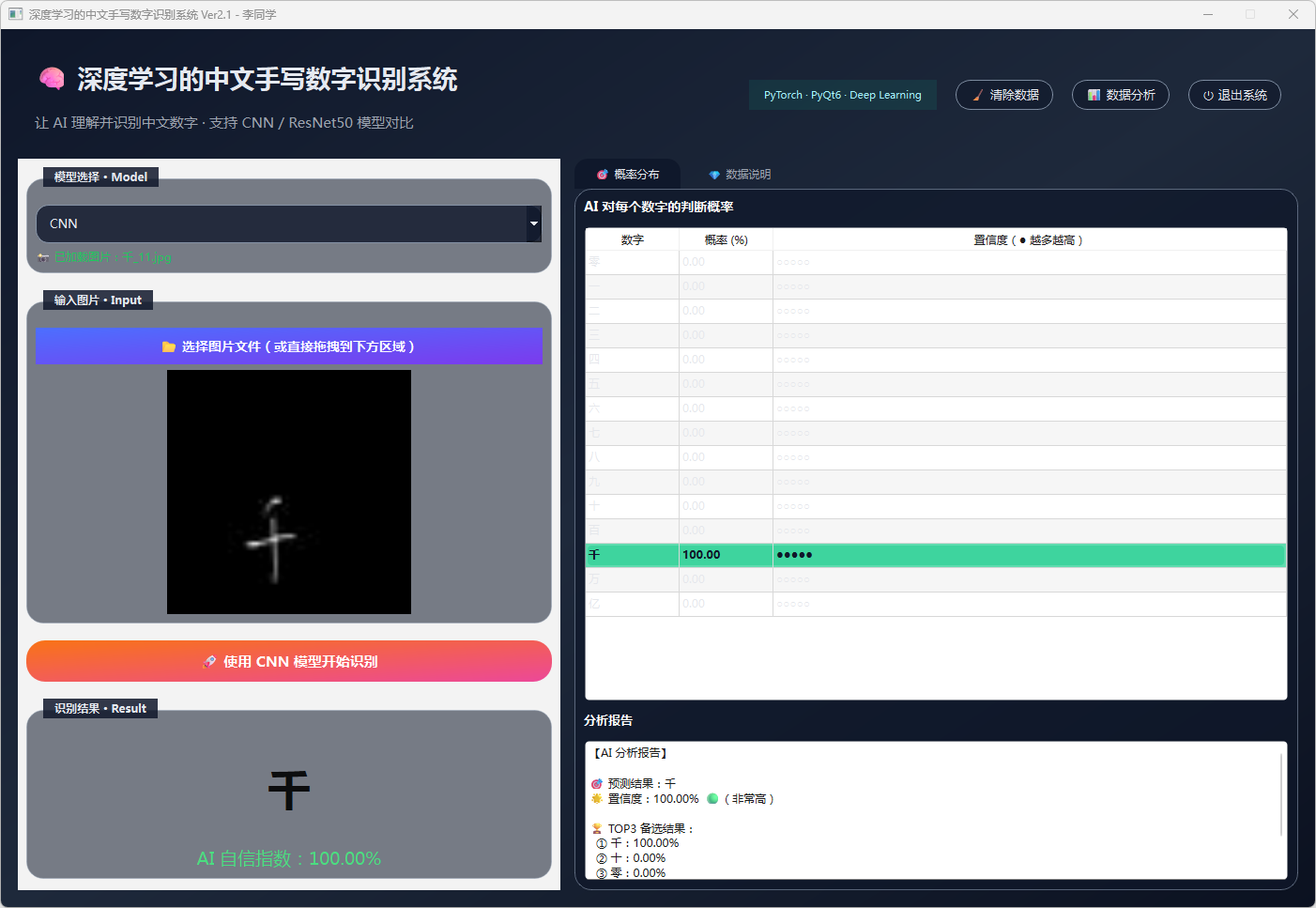
图12 手写数字-千
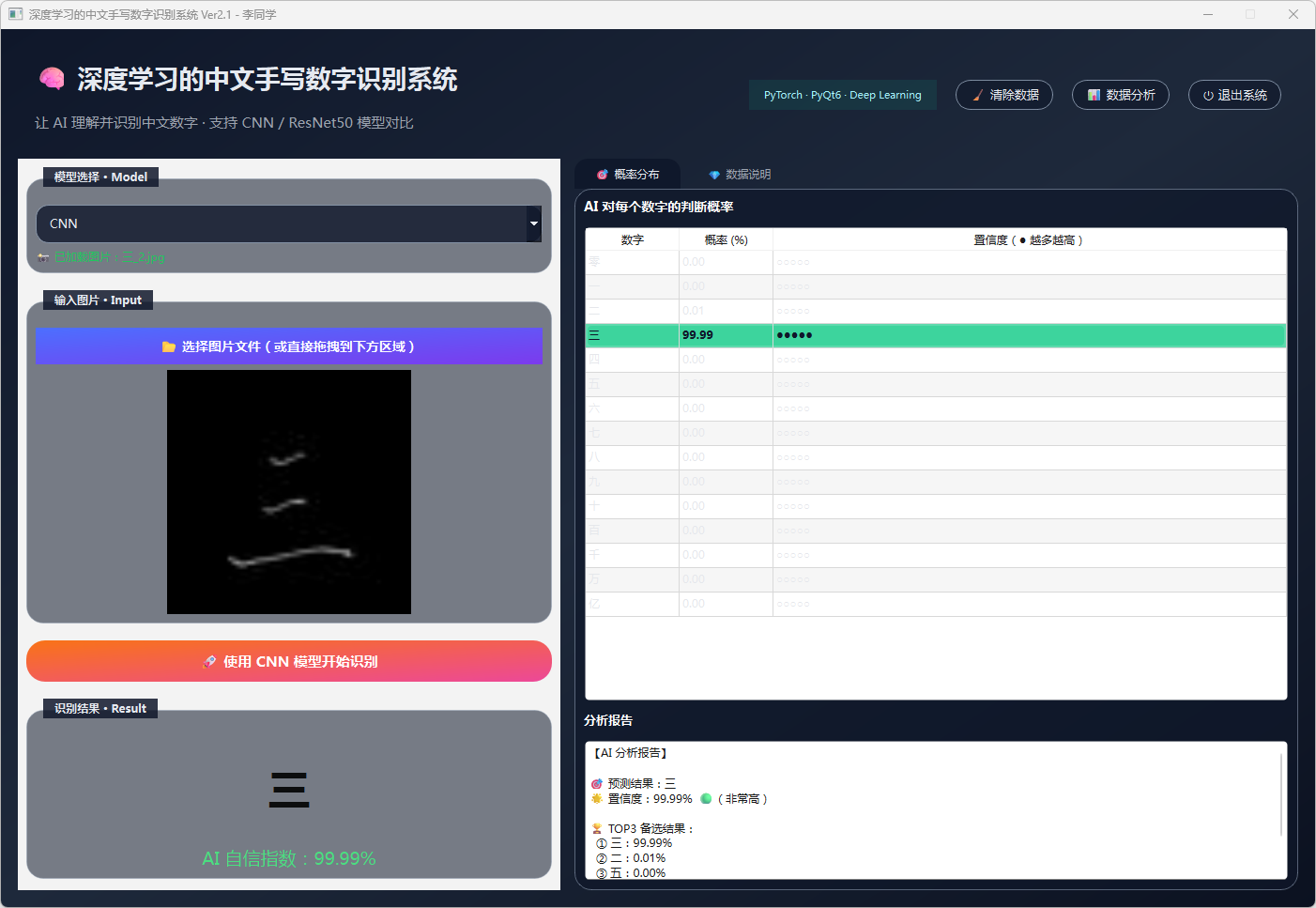
图13 手写数字-三
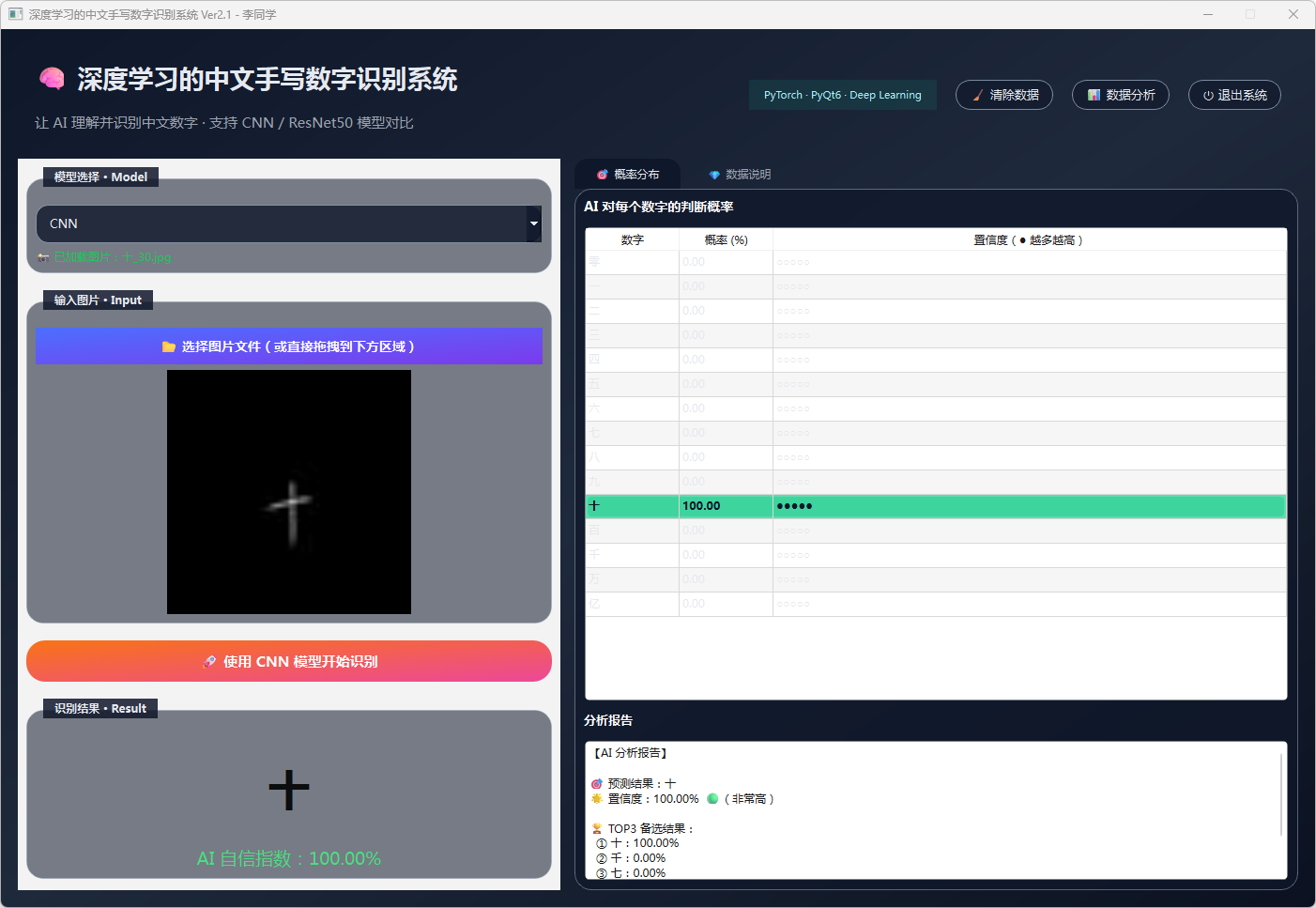
图14 手写数字-十
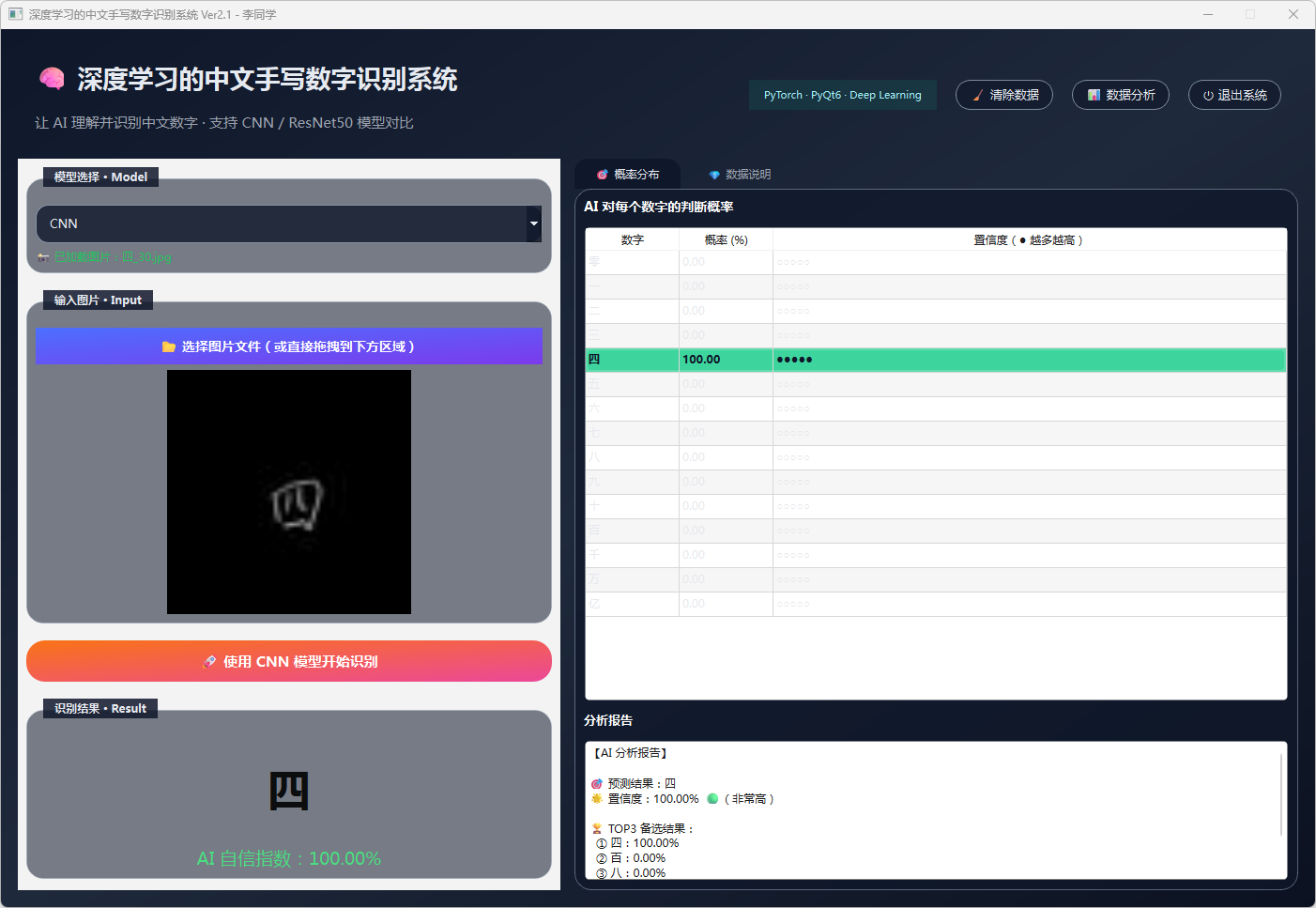
图15 手写数字-四
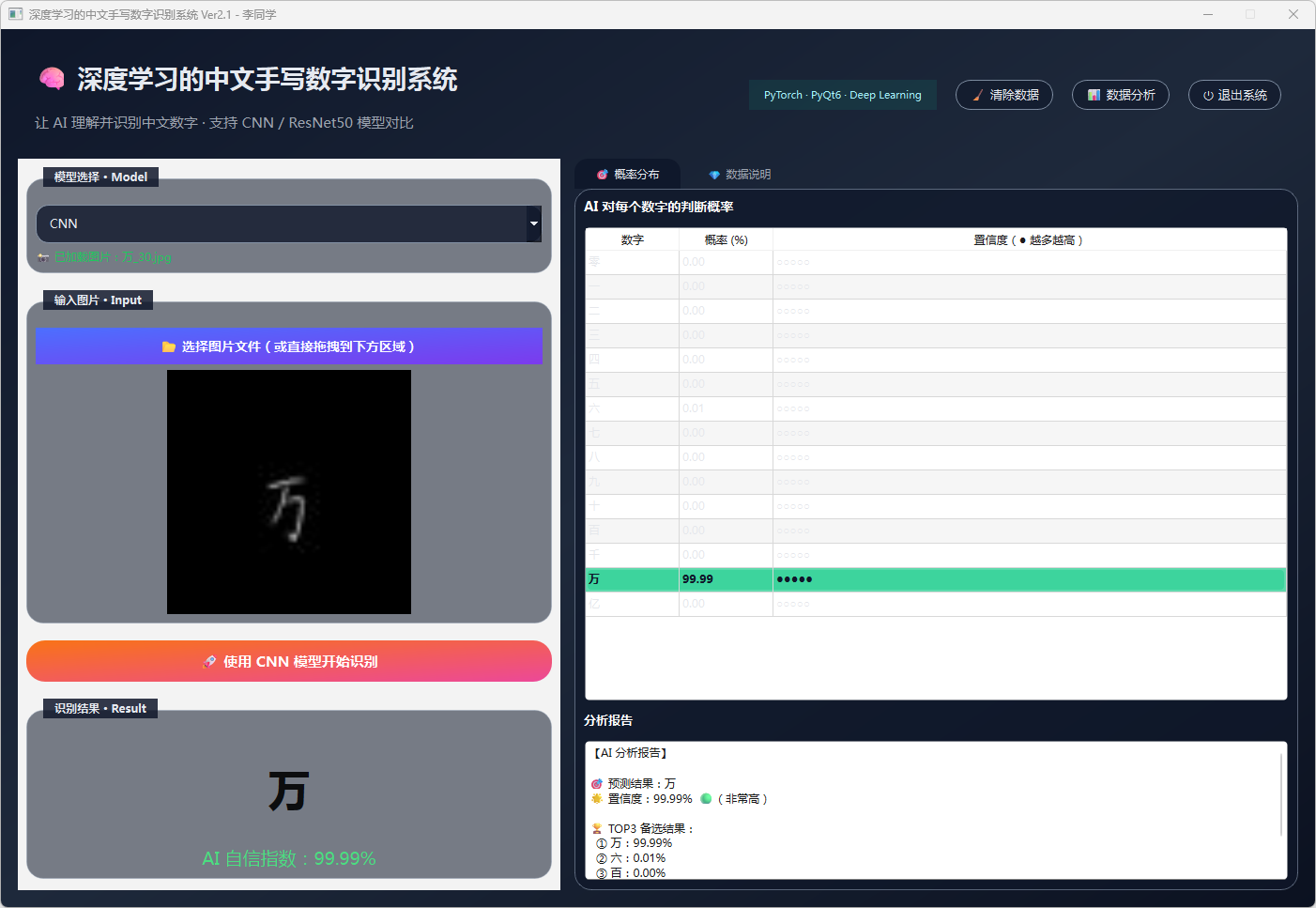
图16 手写数字-万
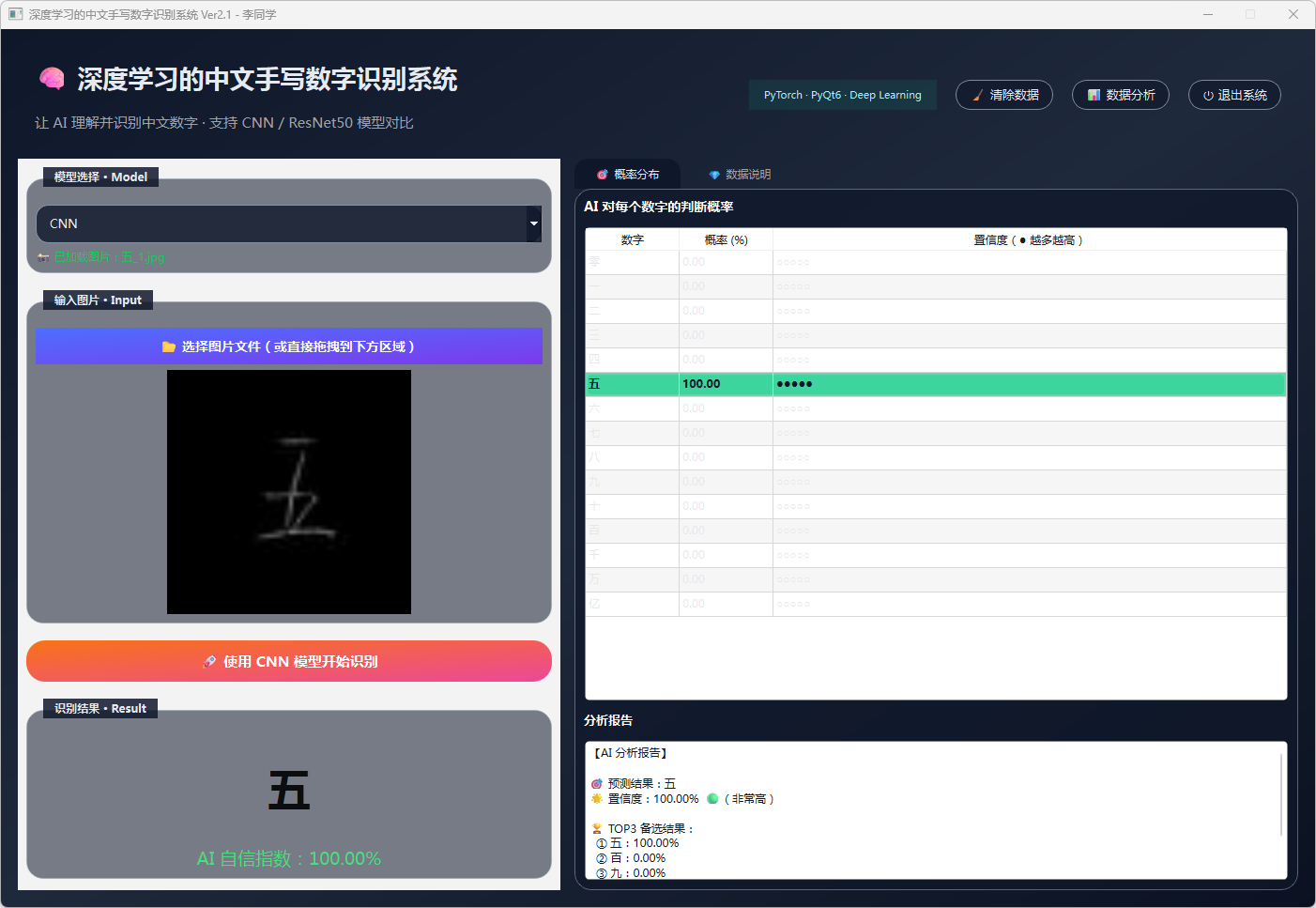
图17 手写数字-五
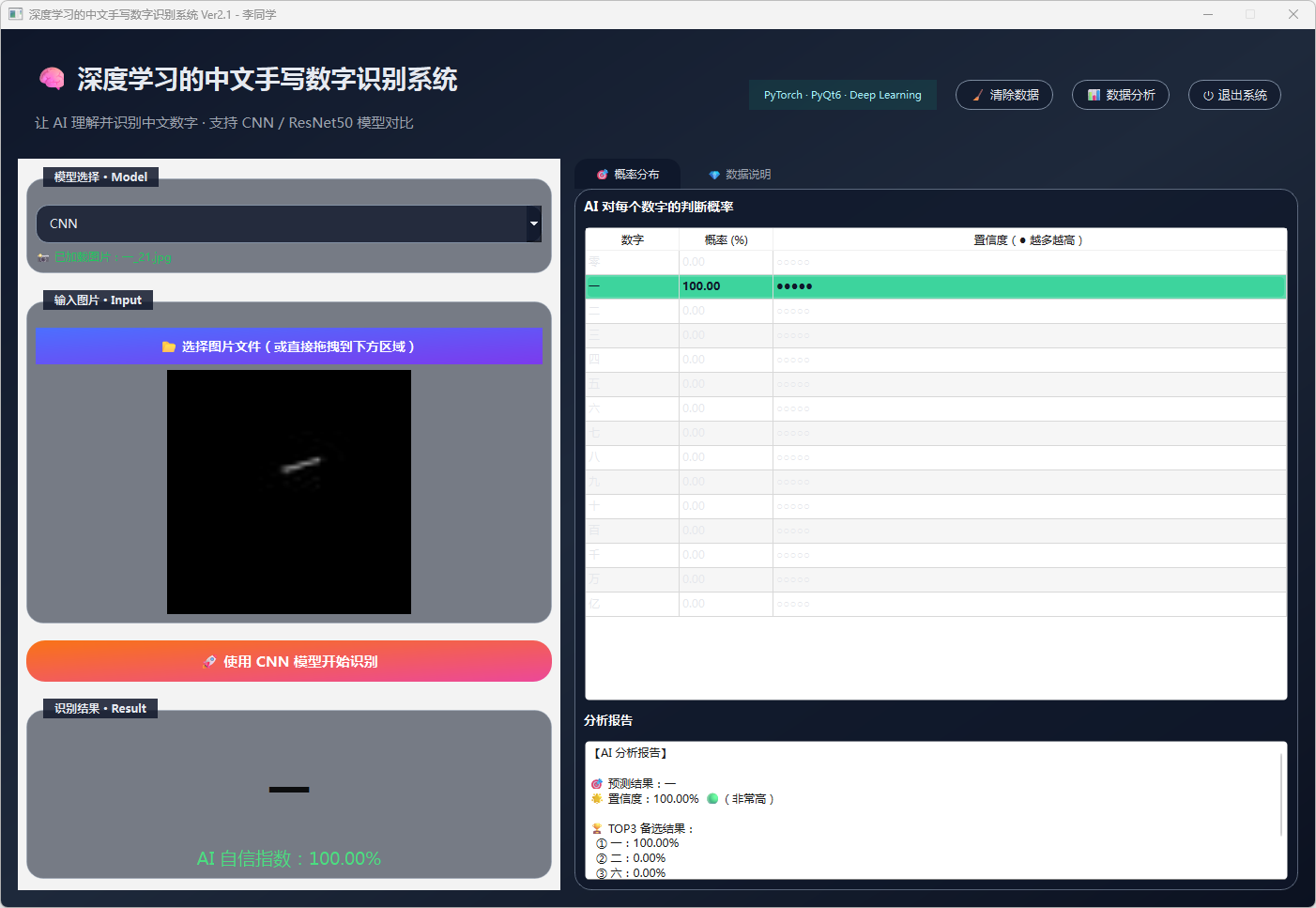
图18 手写数字-一
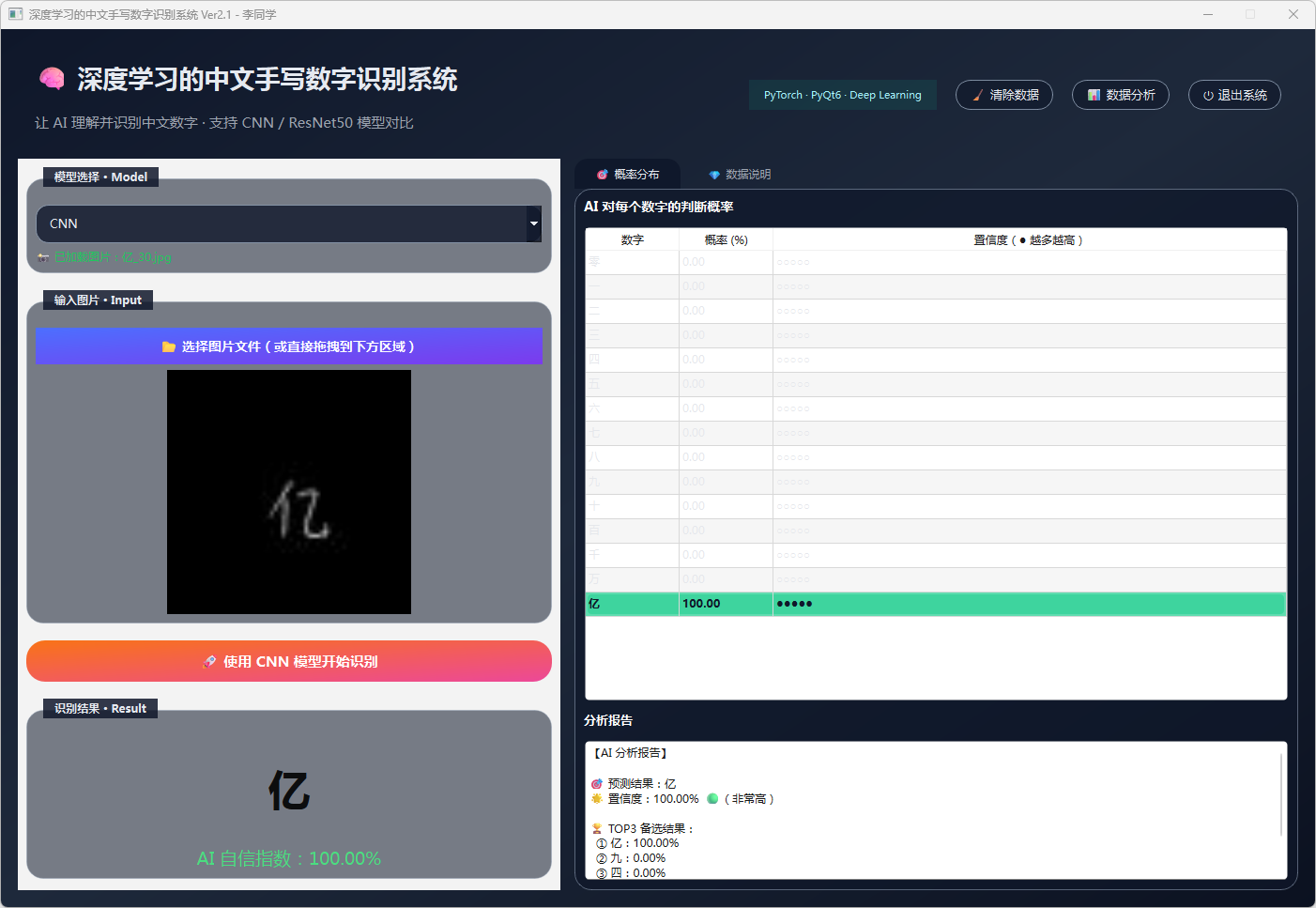
图19 手写数字-亿
ResNet50模型-手写数字识别
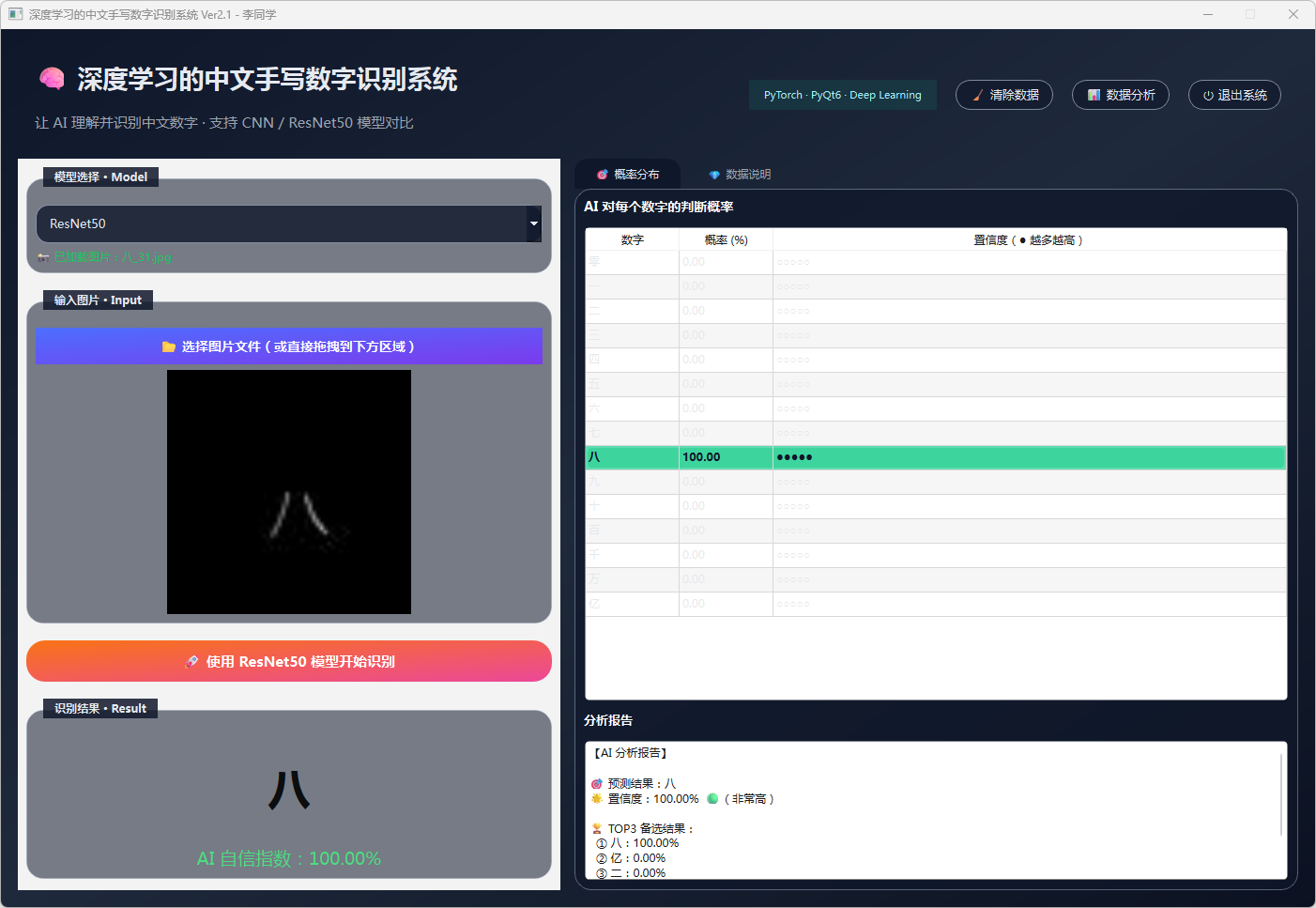
图20 手写数字-八
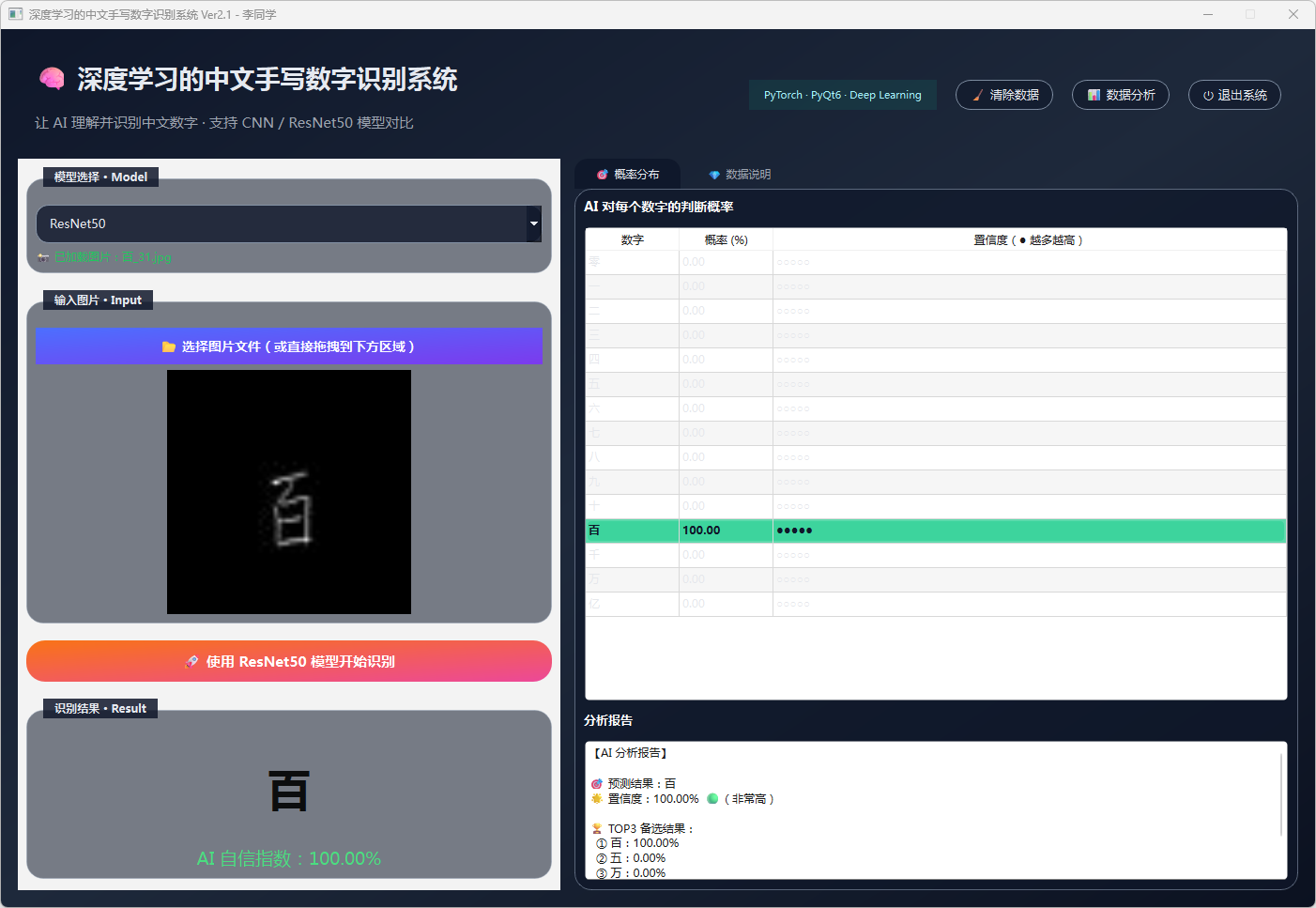
图21 手写数字-百
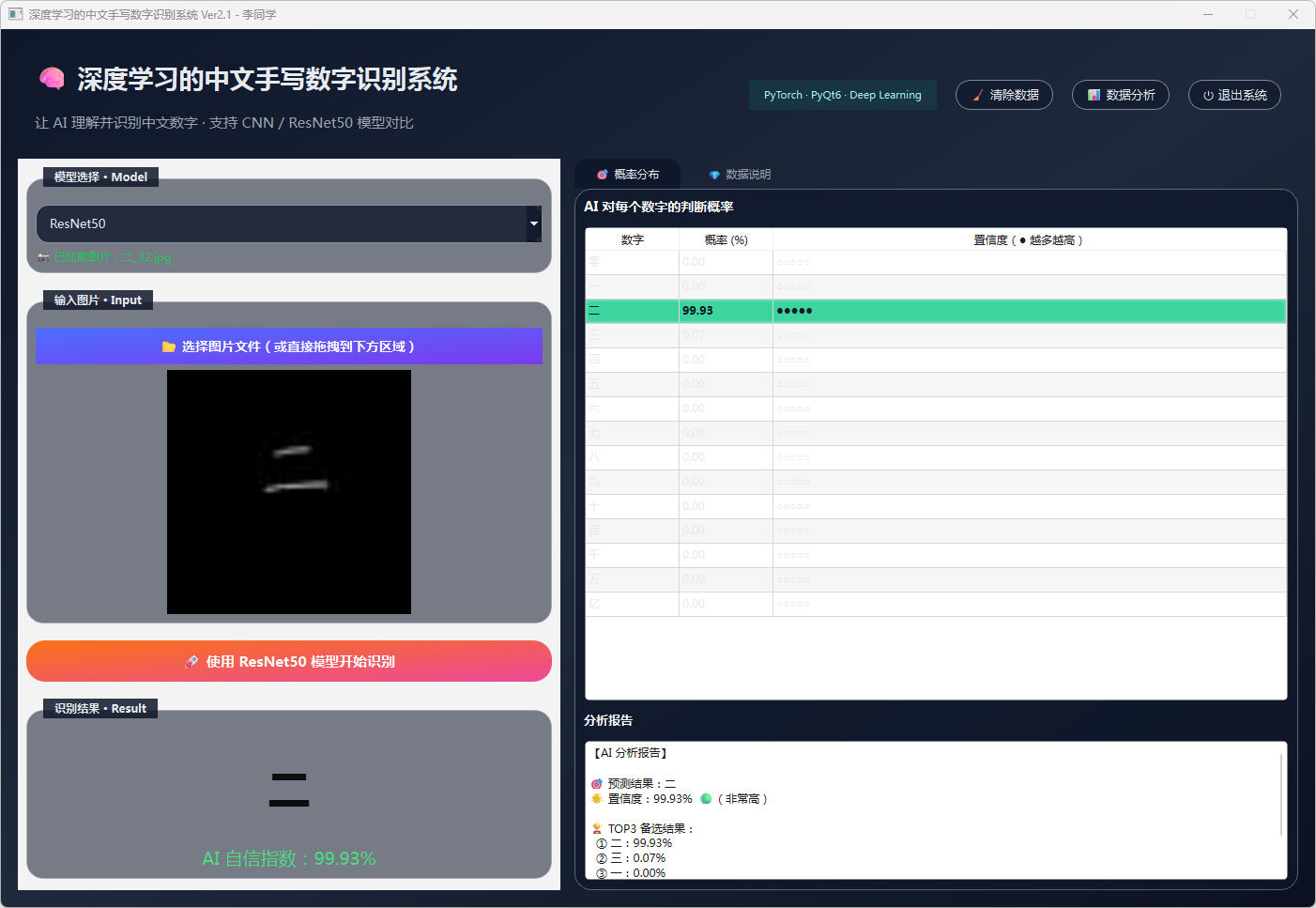
图22 手写数字-二
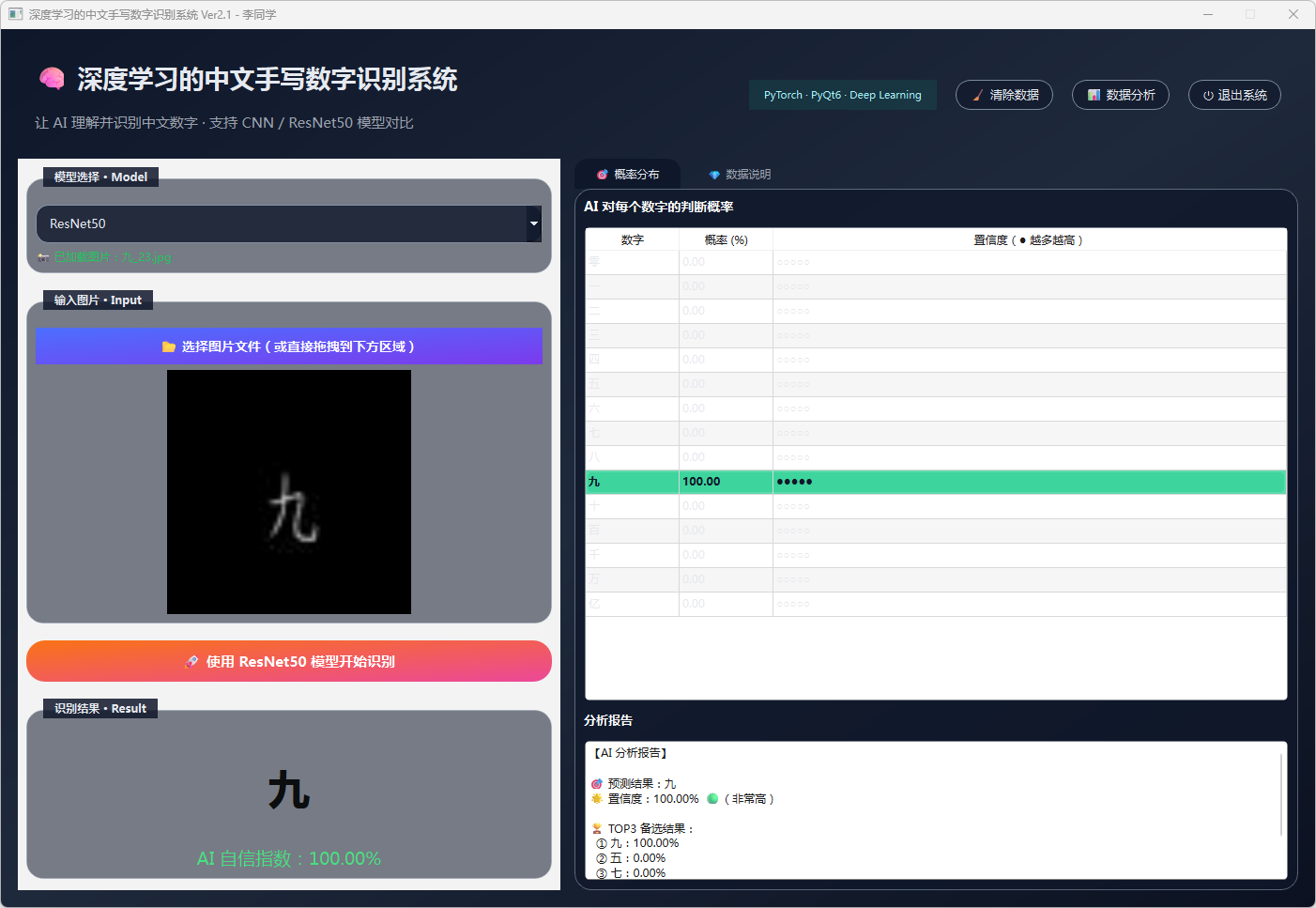
图23 手写数字-九
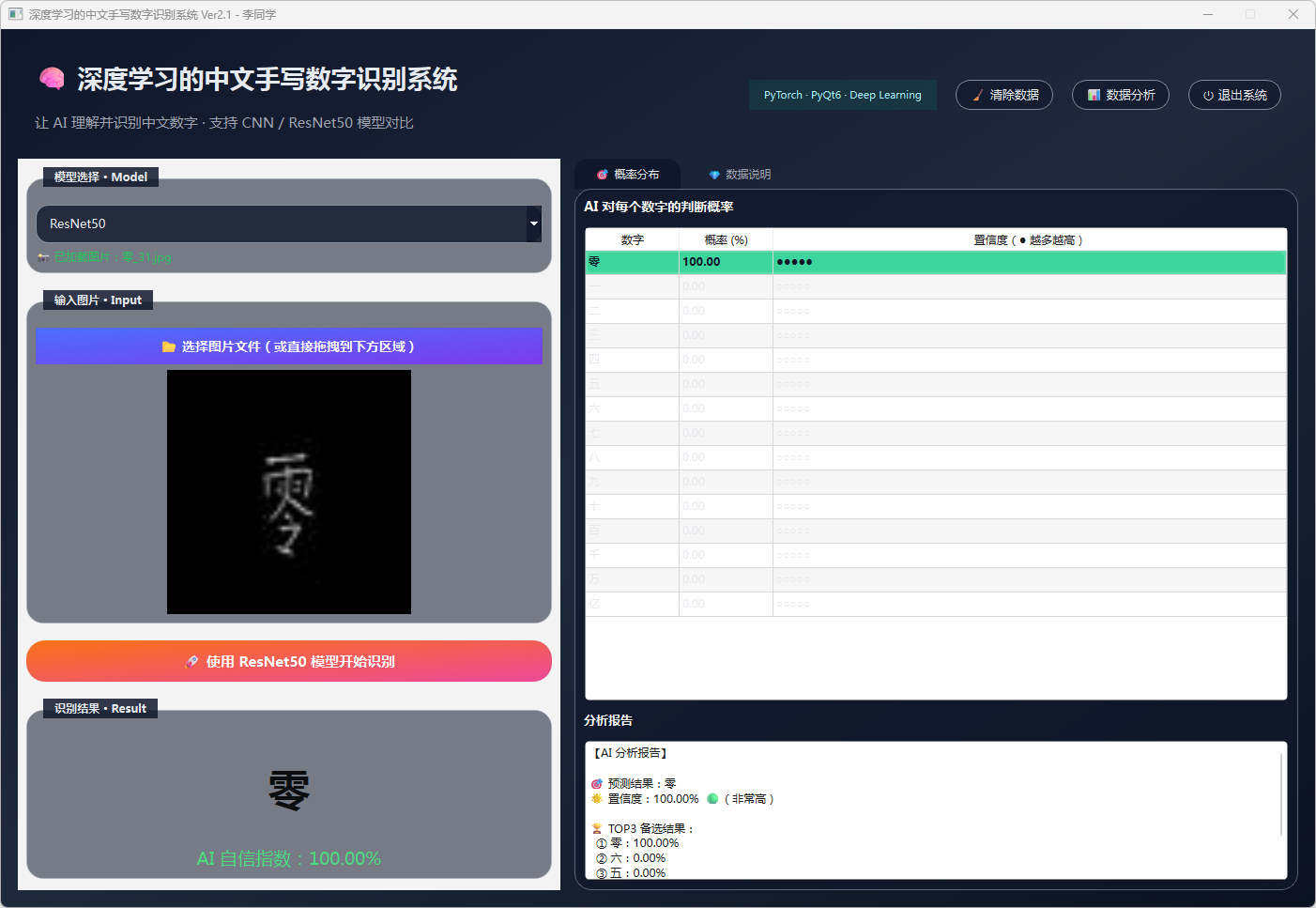
图24 手写数字-零
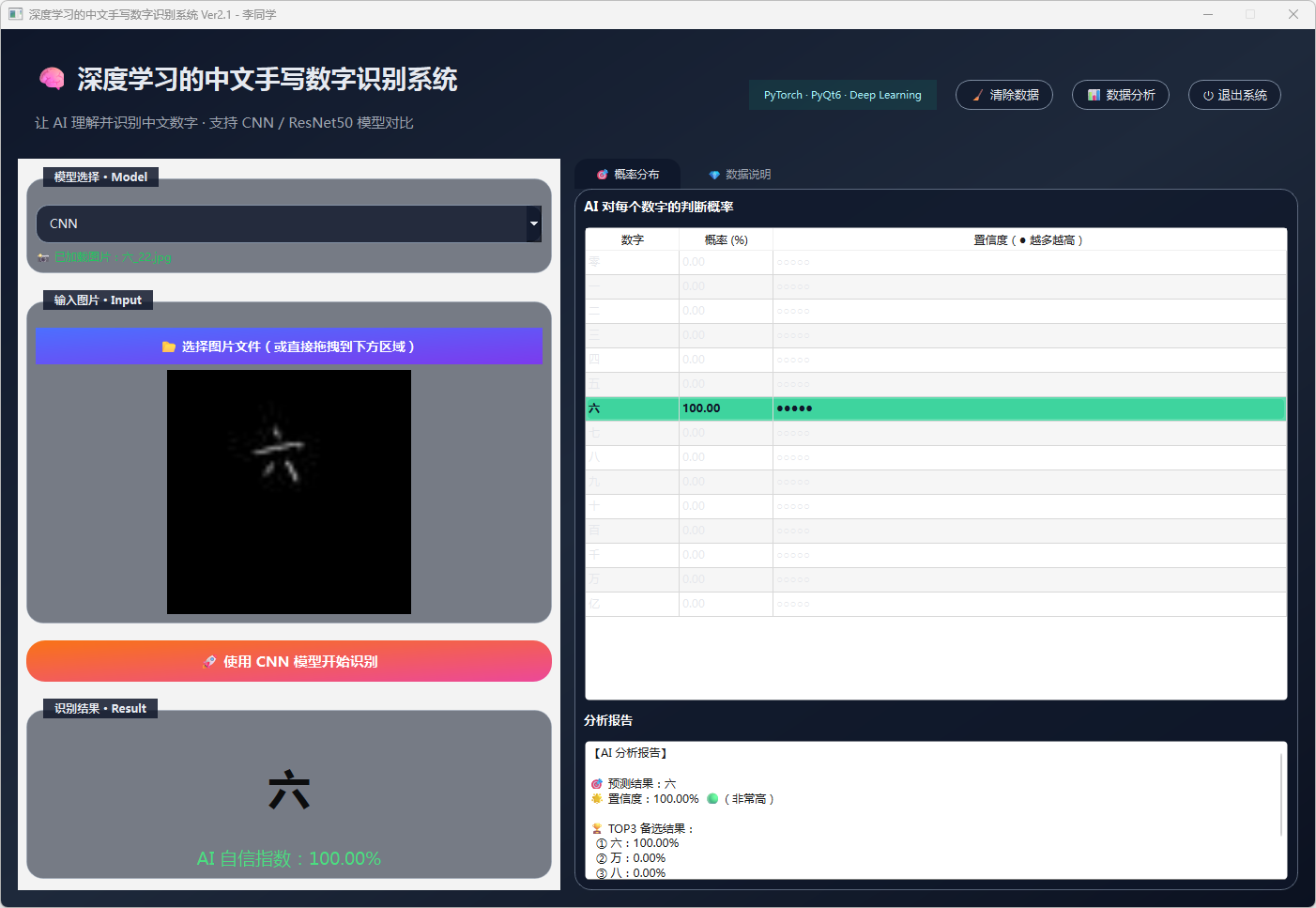
图25 手写数字-六
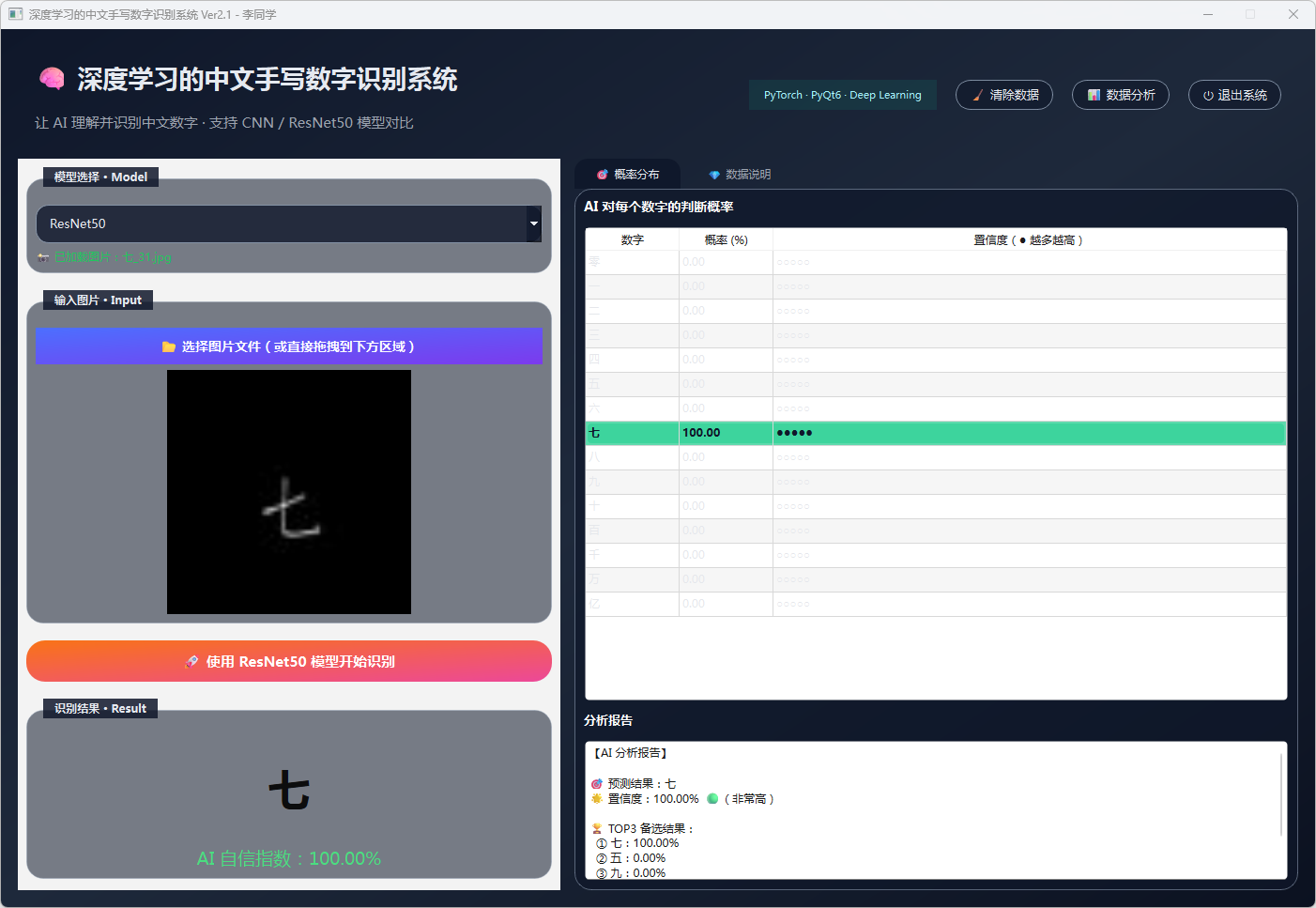
图26 手写数字-七
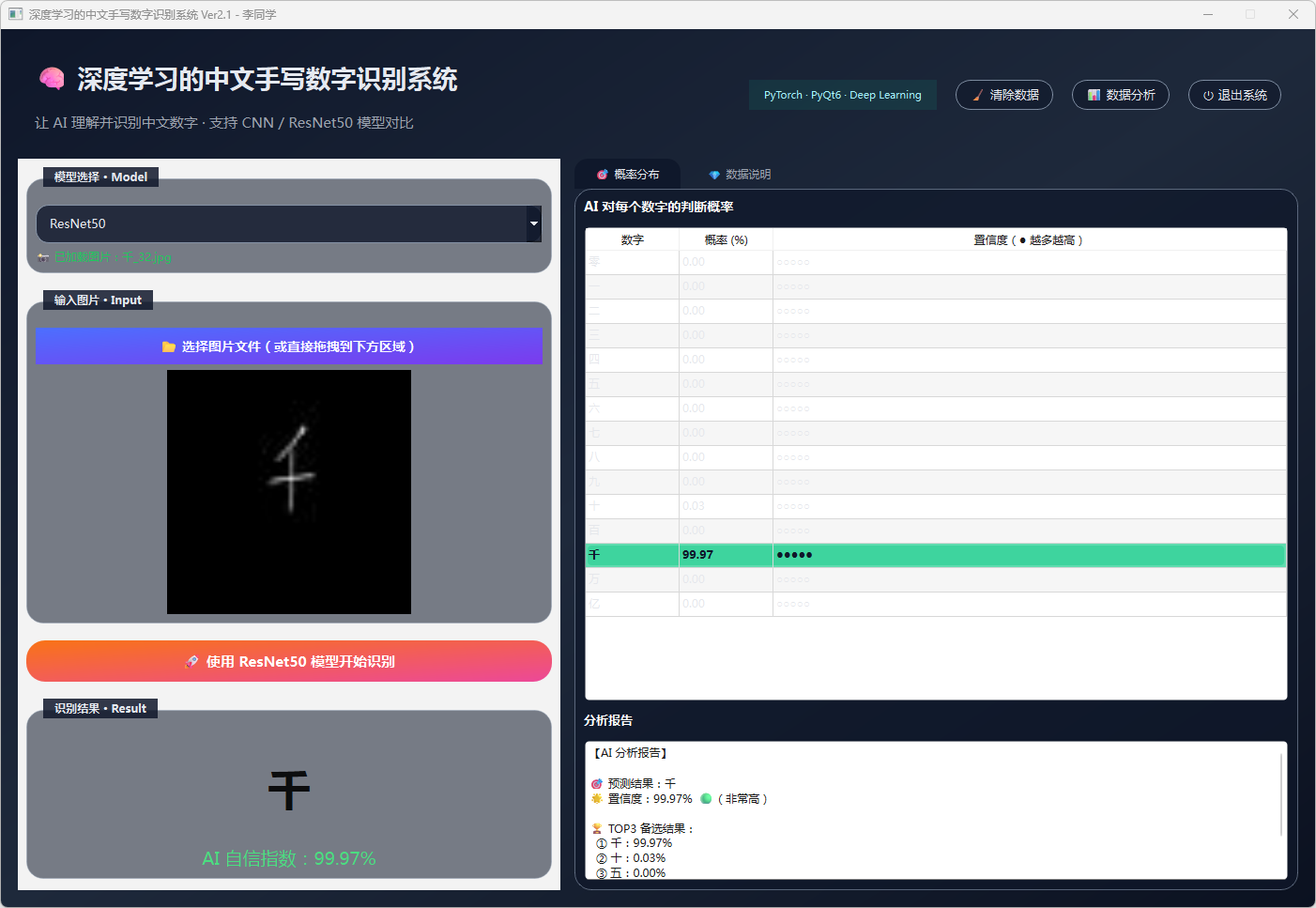
图27 手写数字-千
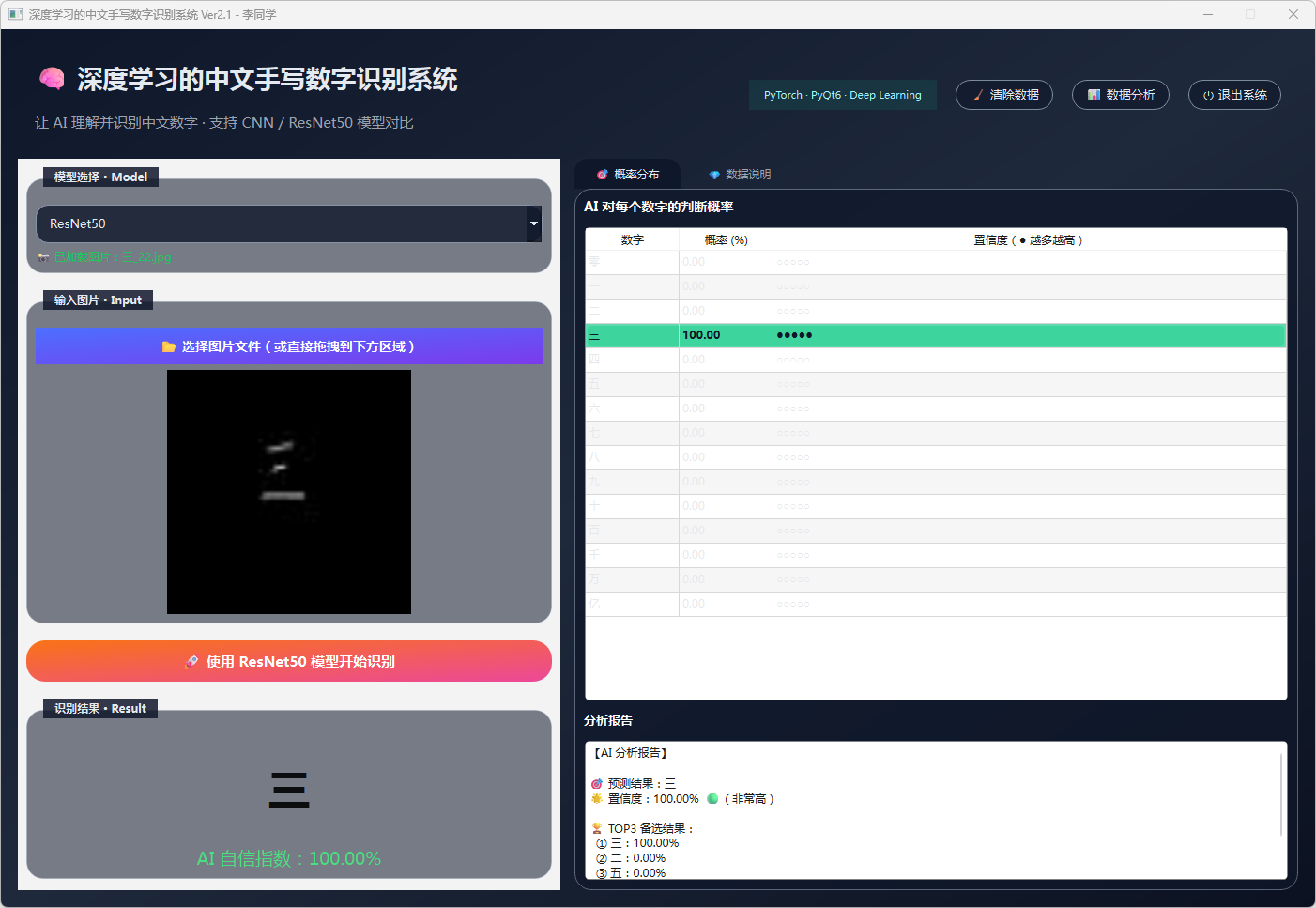
图28 手写数字-三
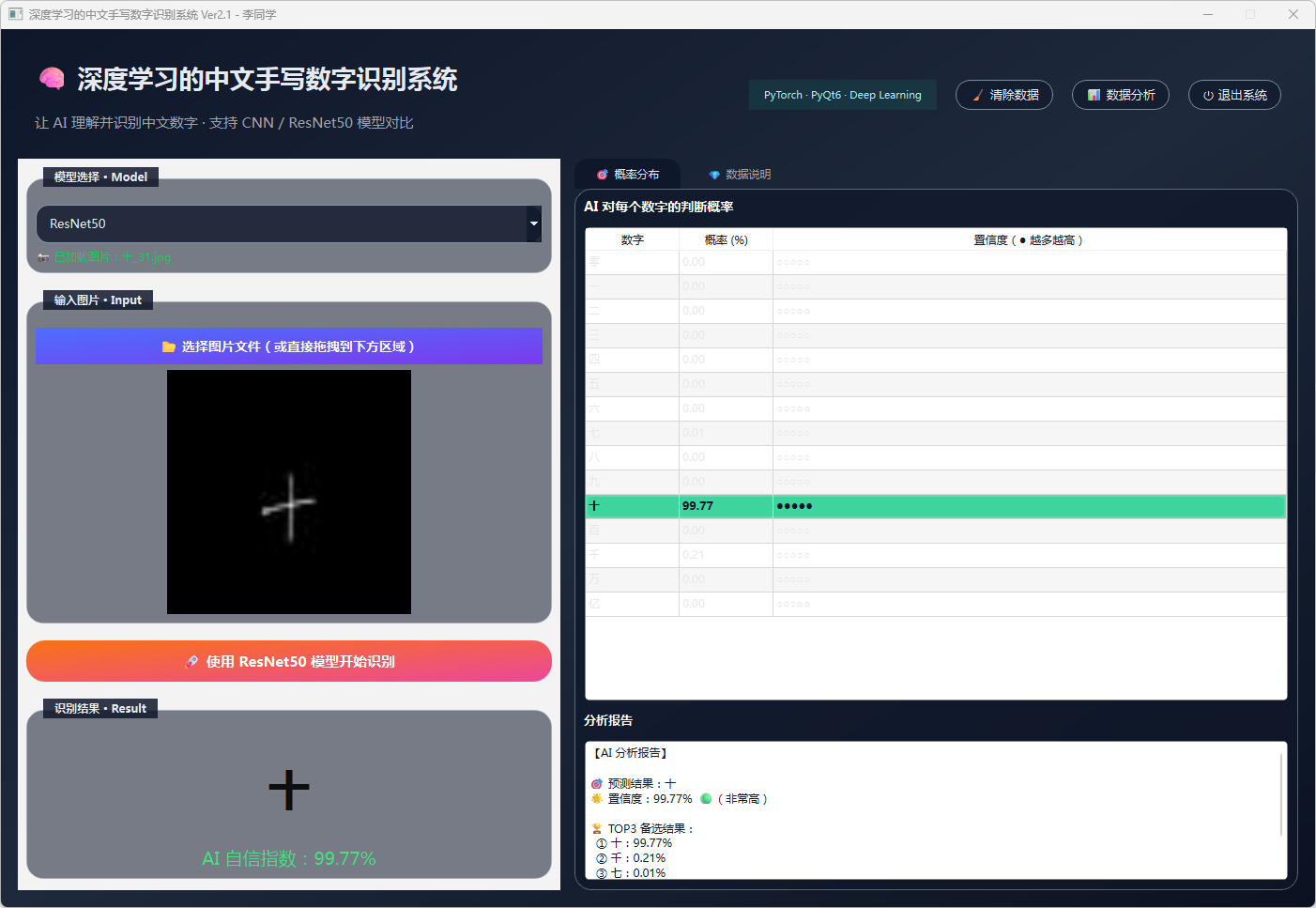
图29 手写数字-十
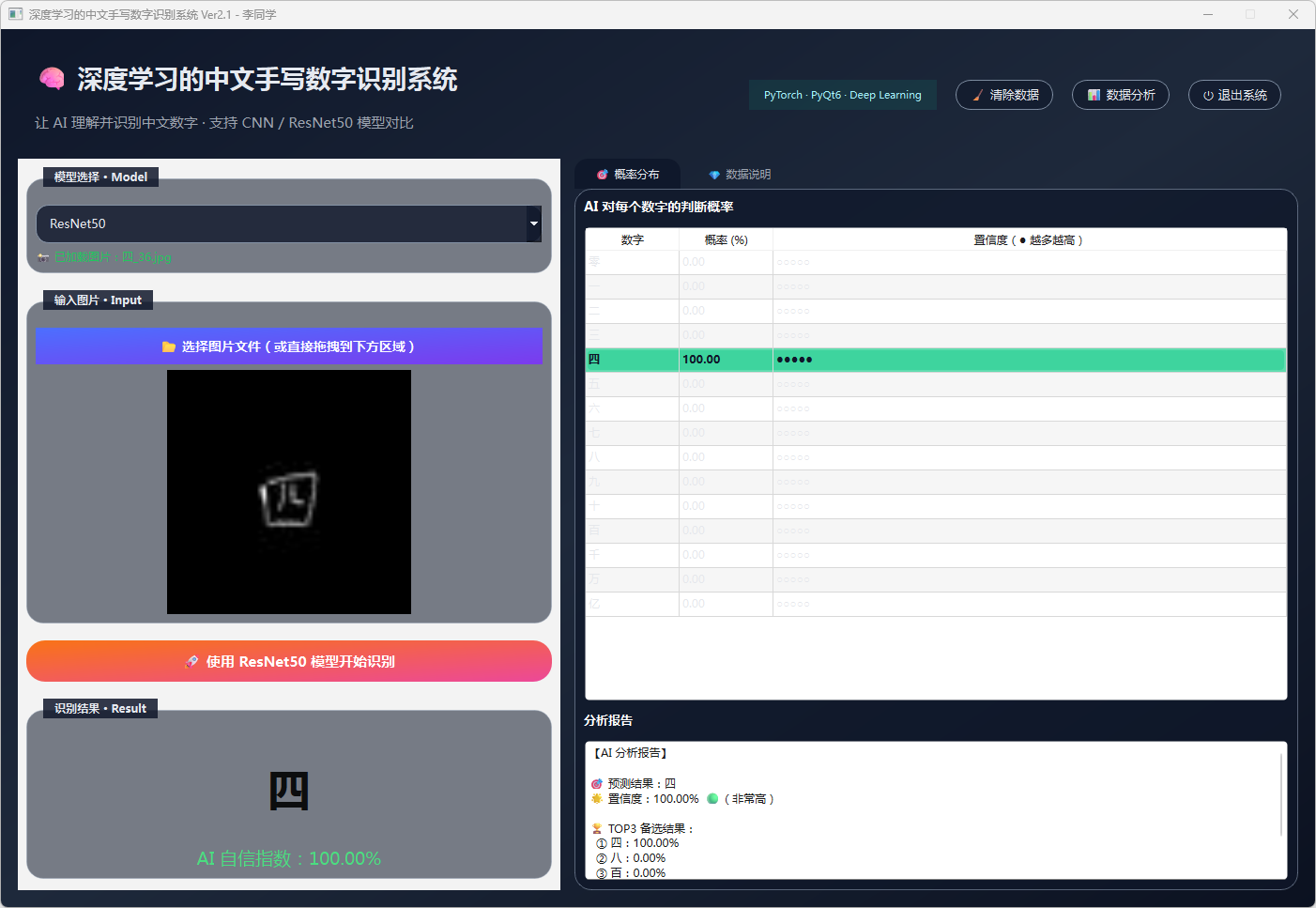
图30 手写数字-四
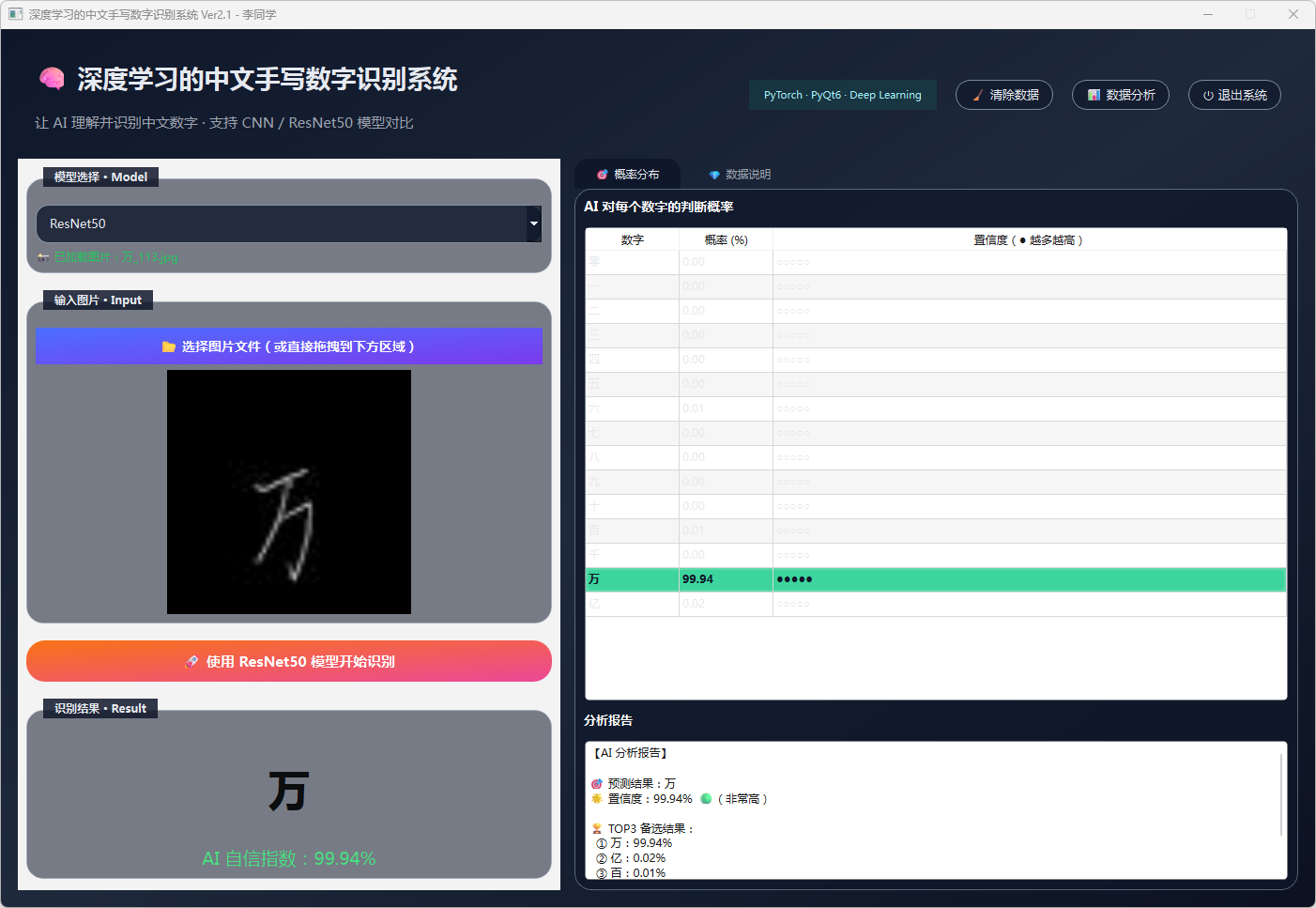
图31 手写数字-万
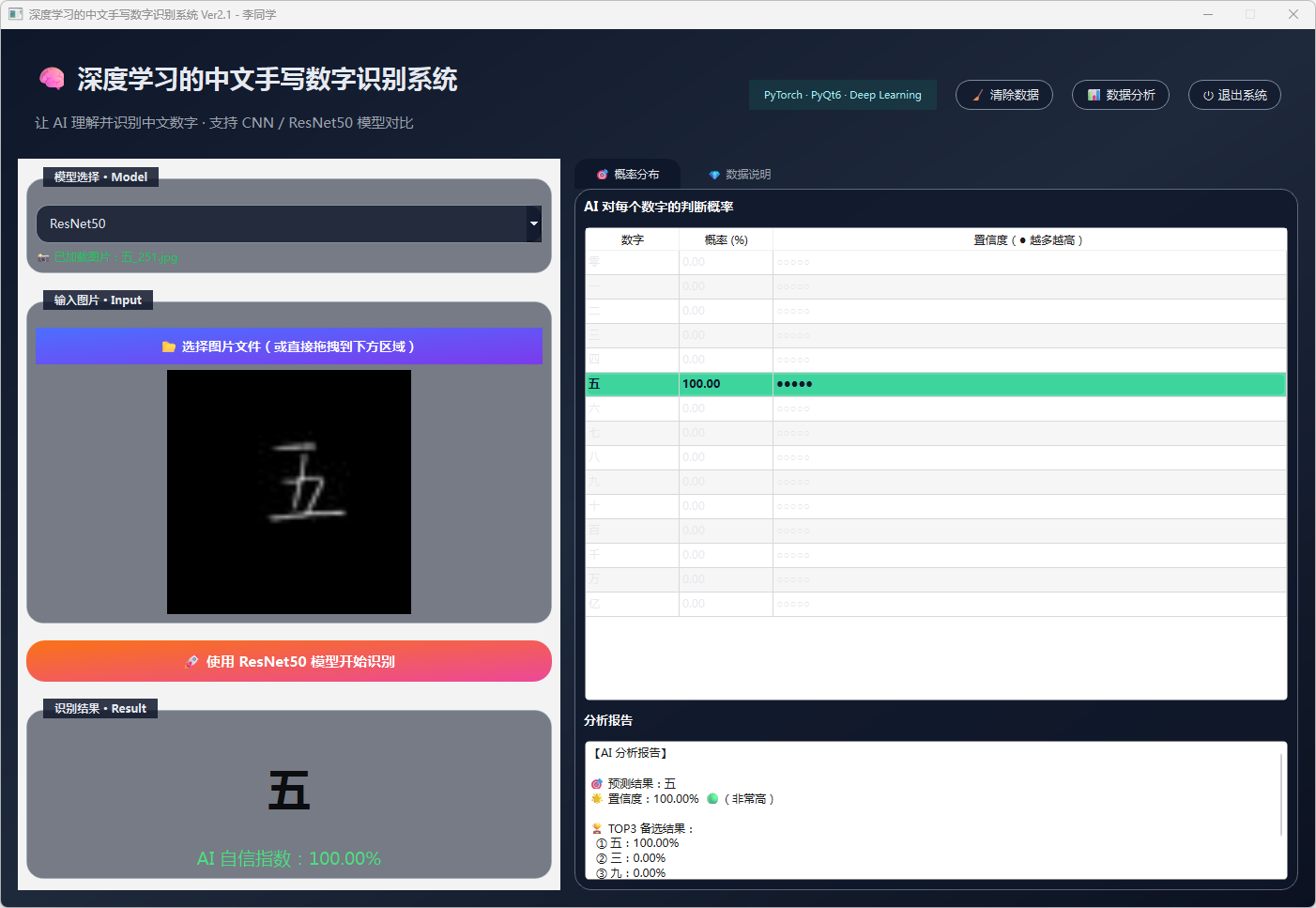
图32 手写数字-五
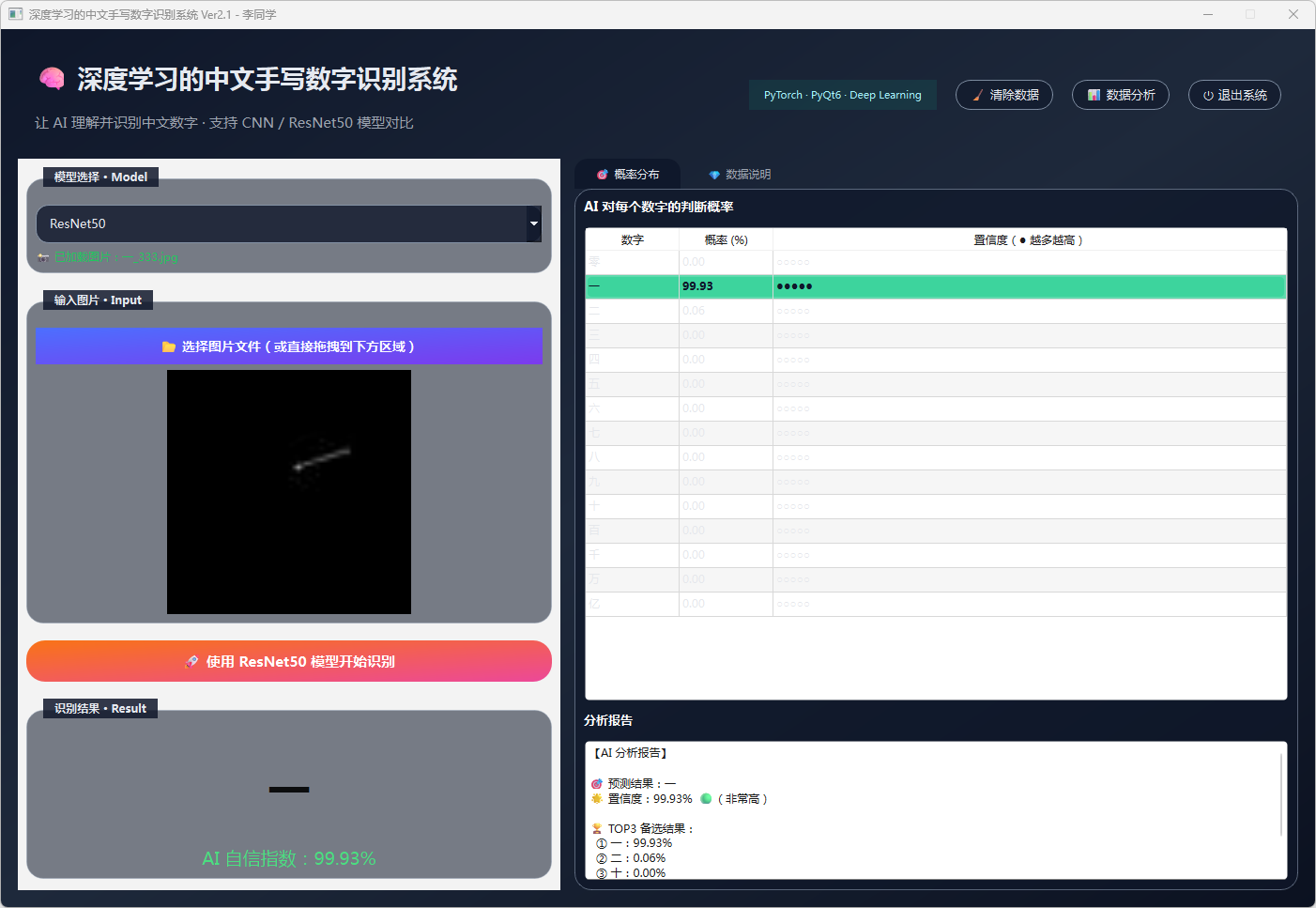
图33 手写数字-一
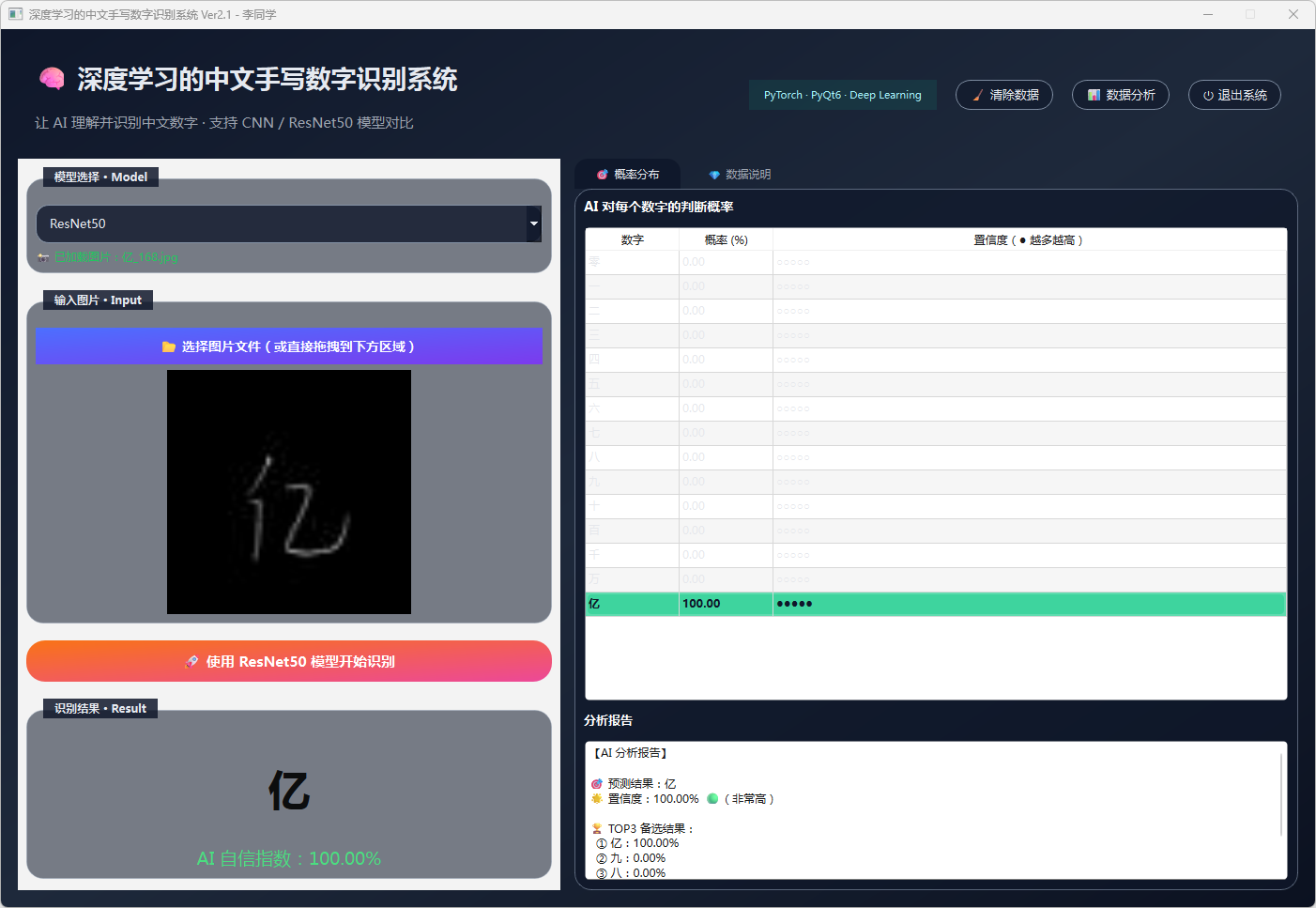
图34 手写数字-亿
Analysis:数据分析
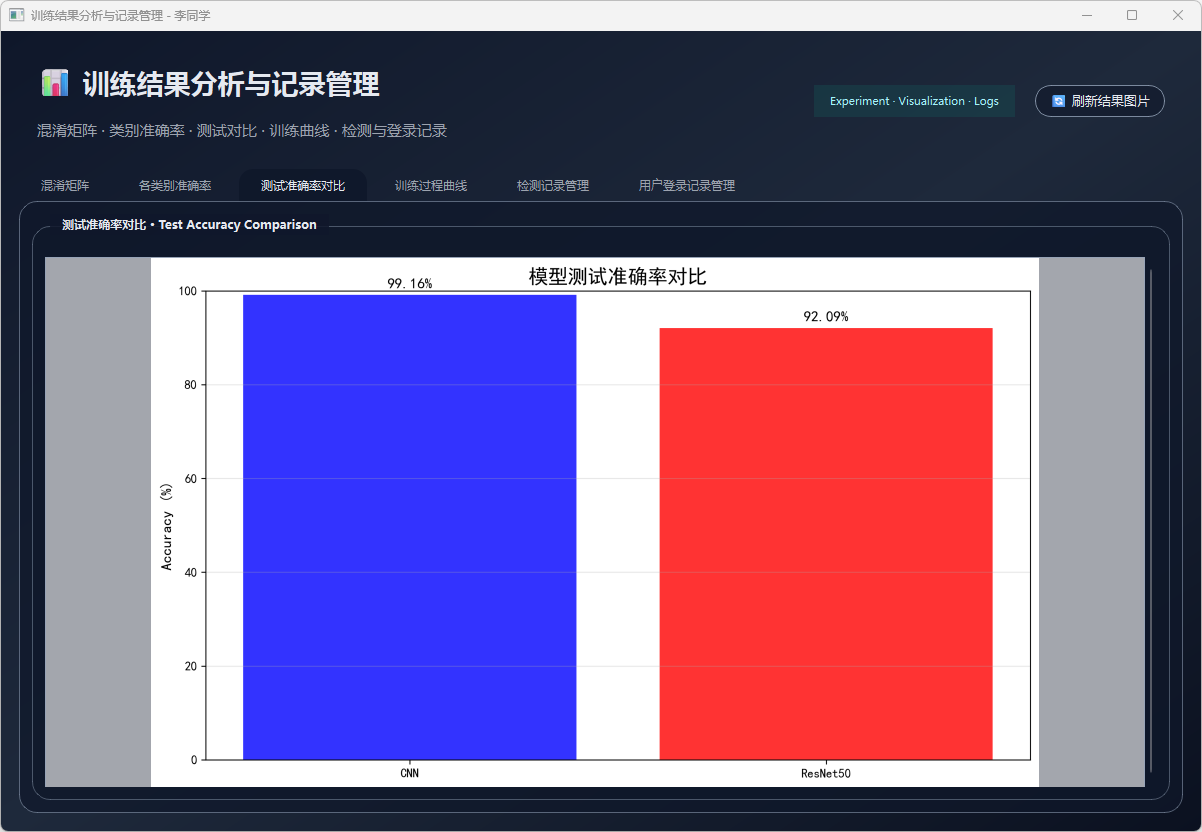
图35 测试准确率对比
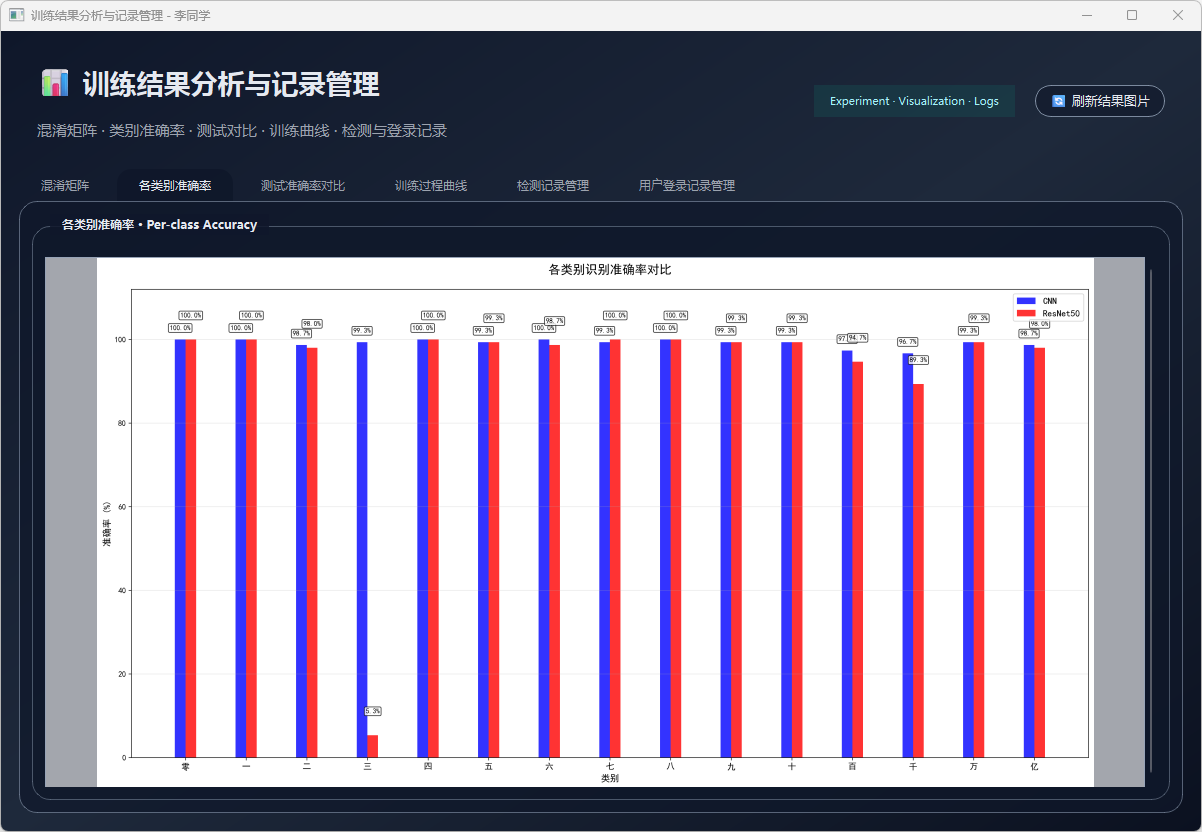
图36 各类别准确率
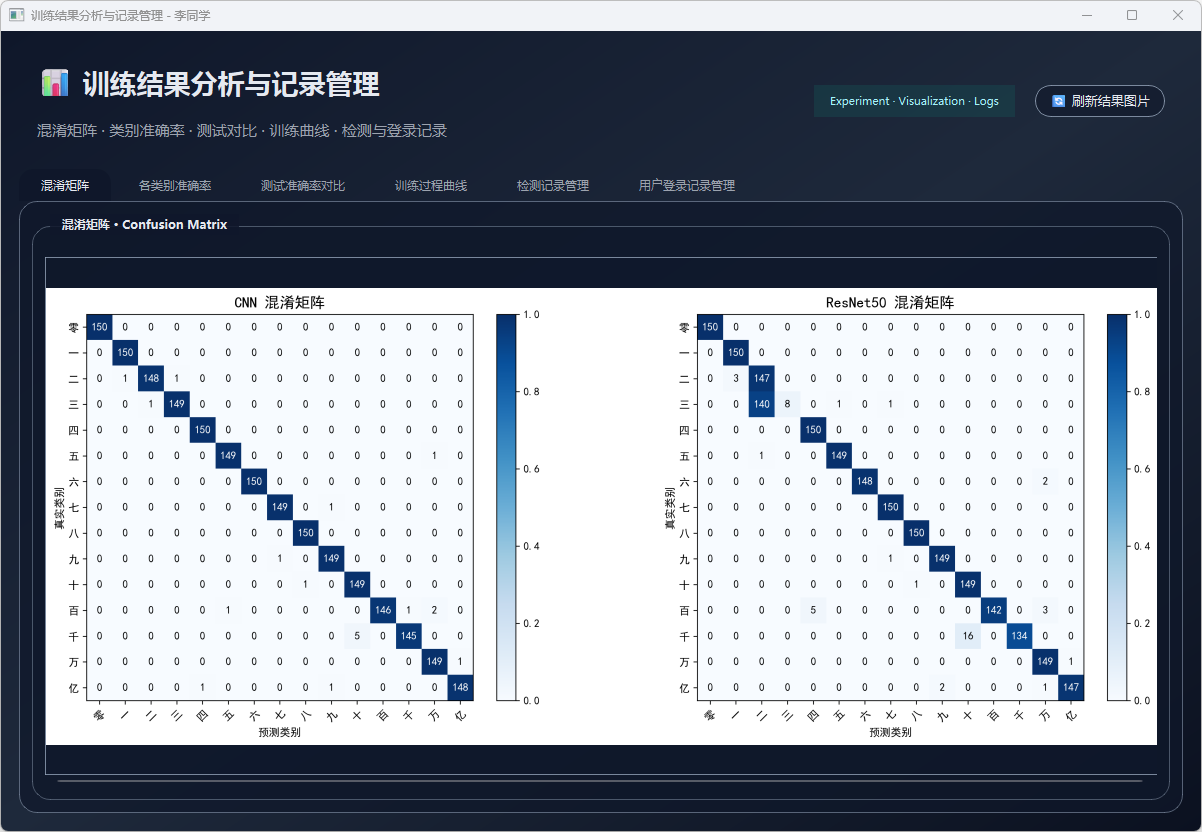
图37 混淆矩阵
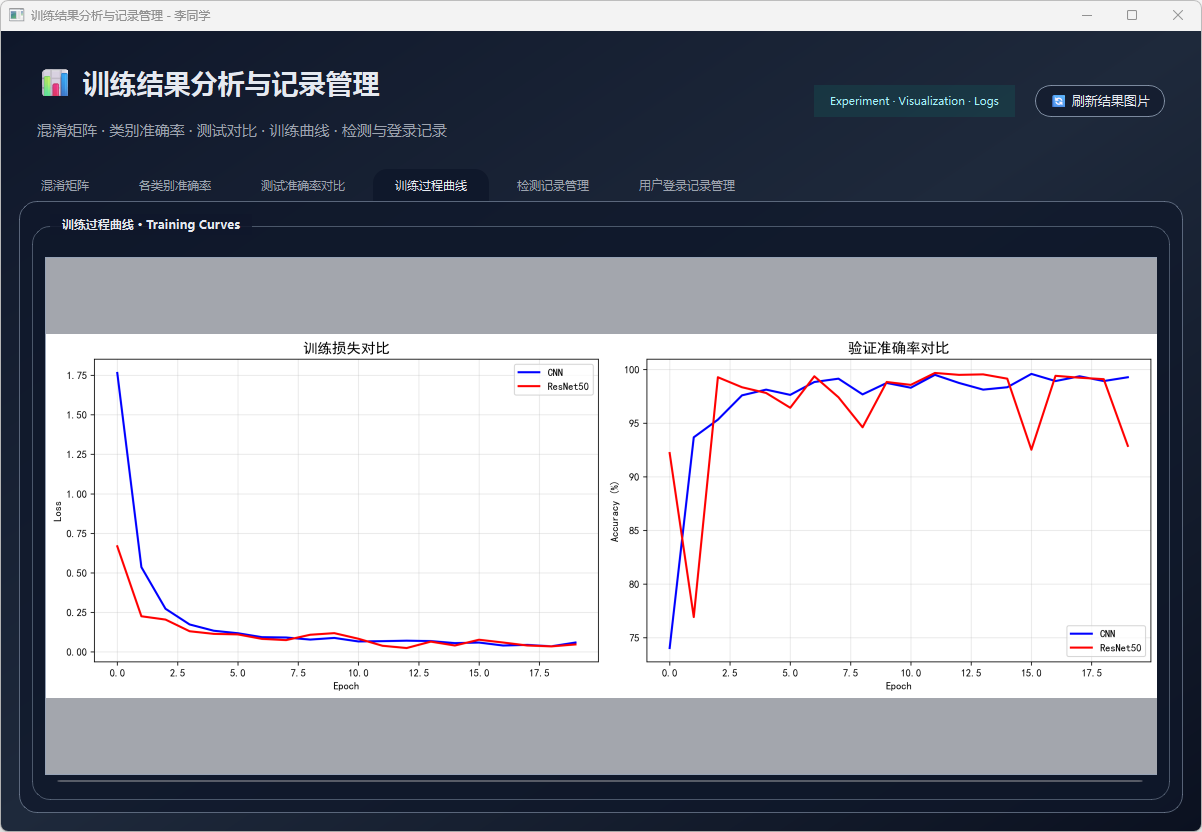
图38 训练过程曲线
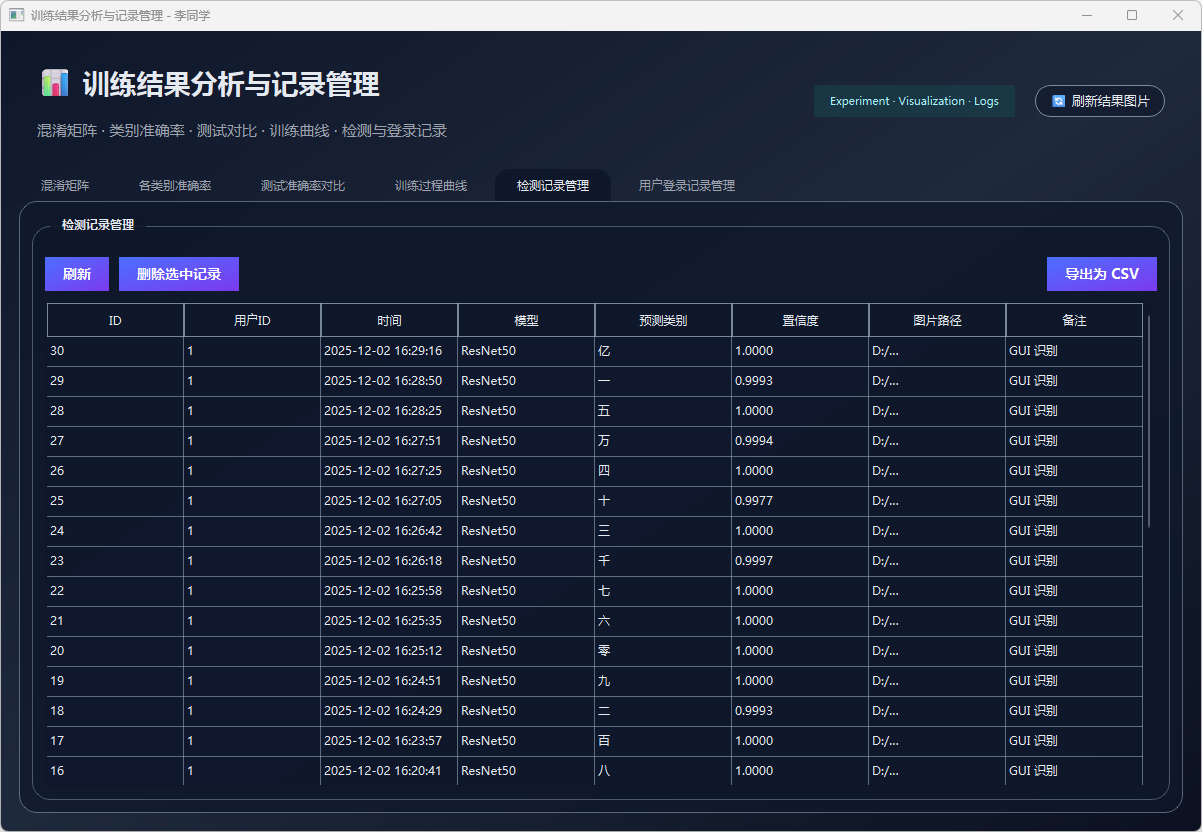
图39 检测记录管理
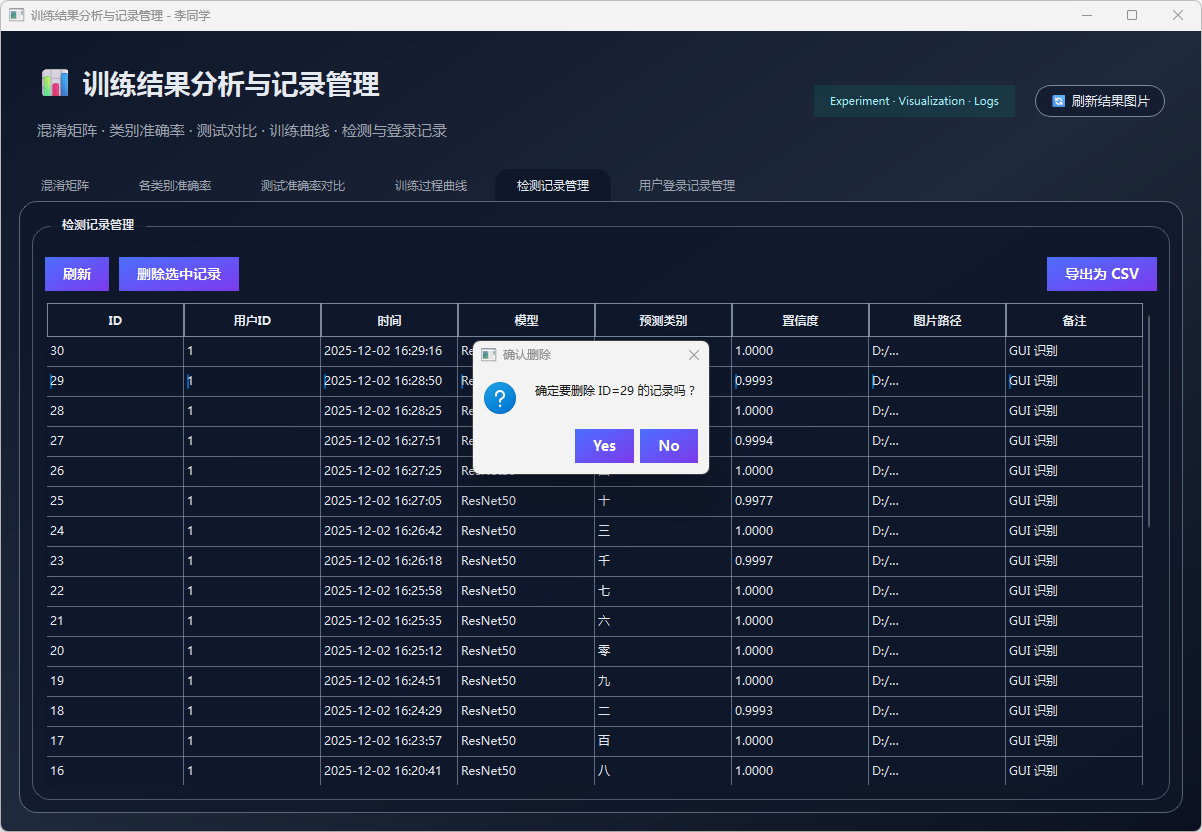
图40 检测记录删除
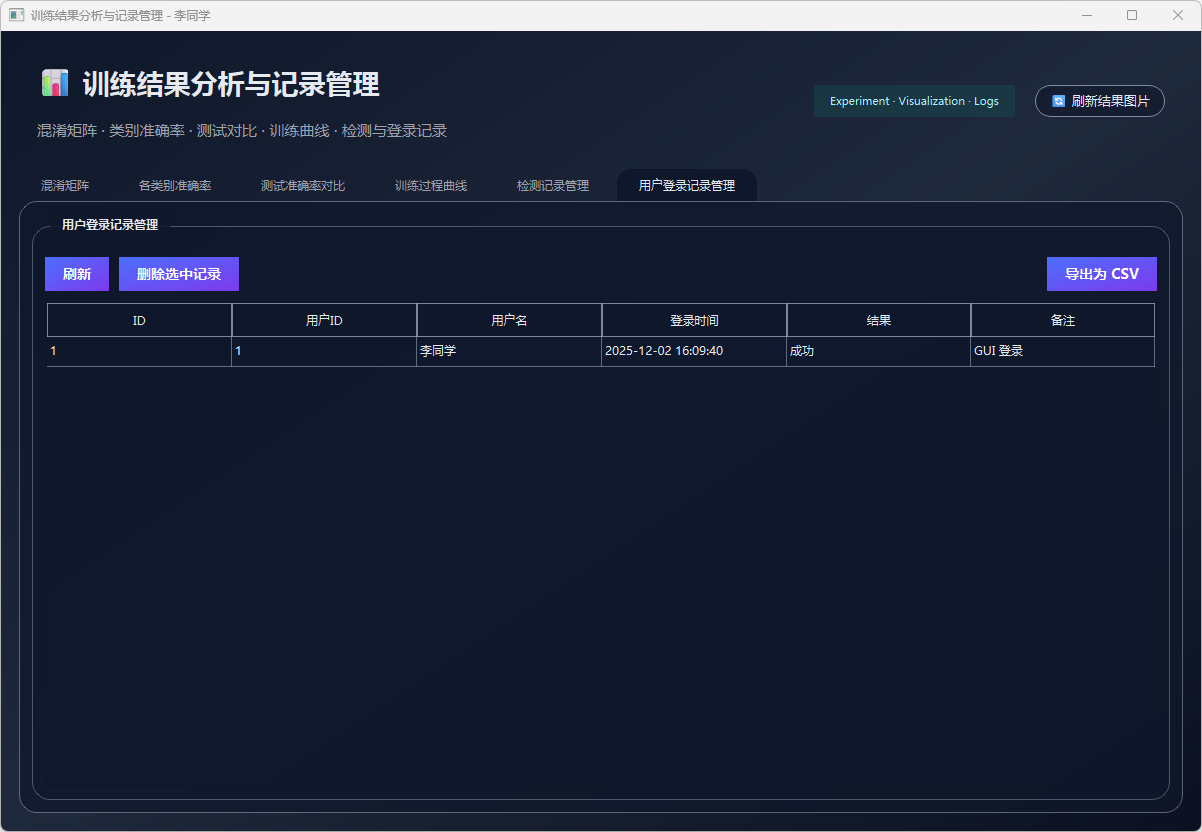
图41 用户登录记录管理
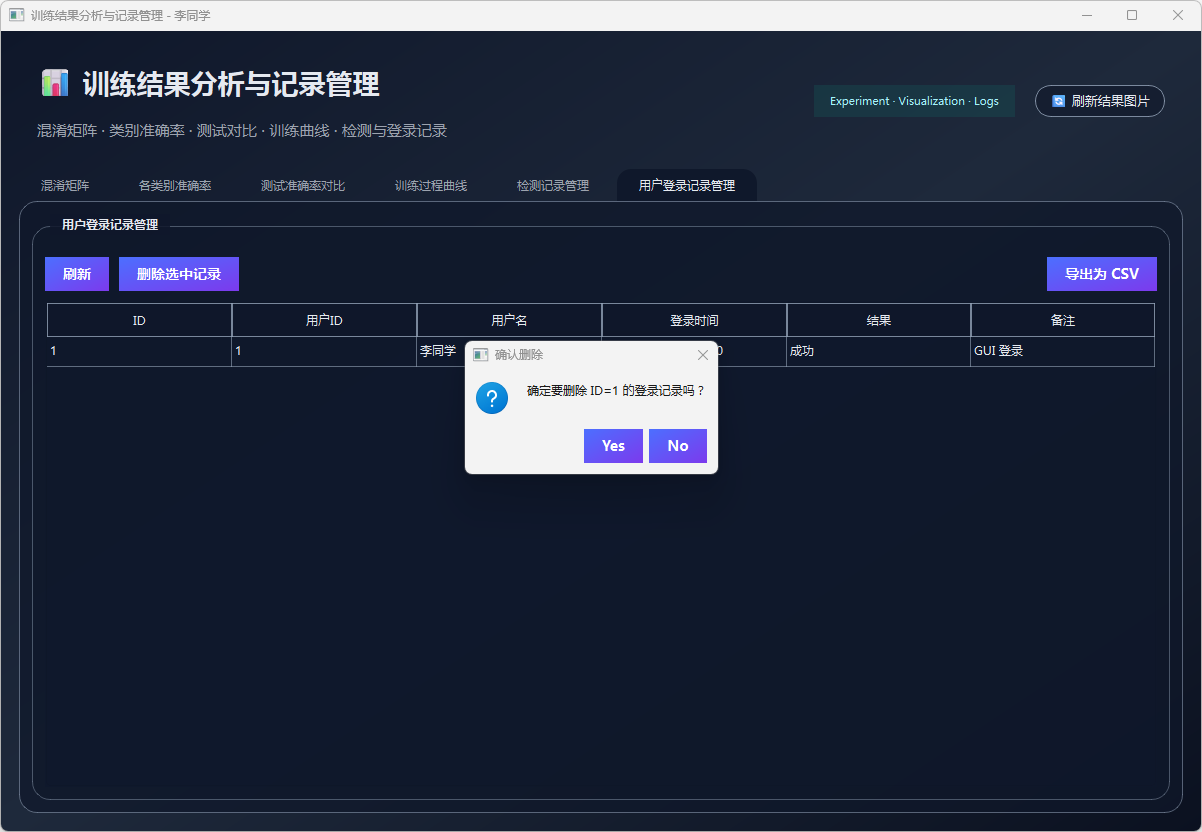
图42 用户登录记录删除
清除数据和退出系统:
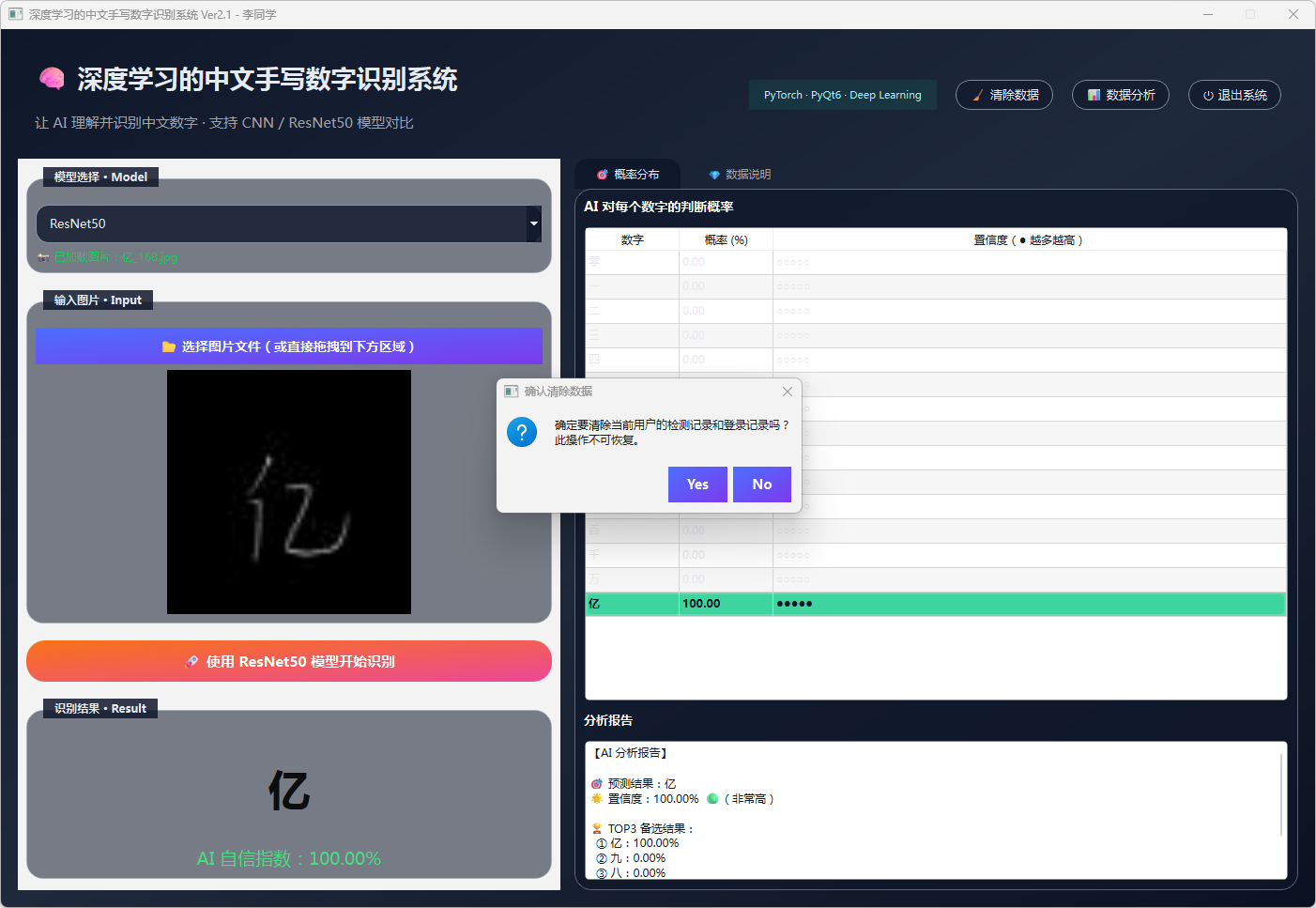
图43 清除数据
图44 退出系统
train_models.py
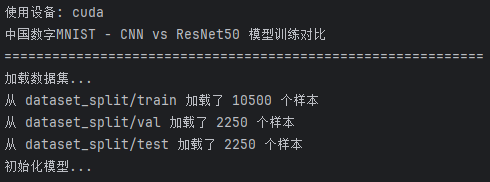
图45 模型训练脚本运行界面及数据集加载统计
图46 训练后自动生成分析图表与报告的日志界面
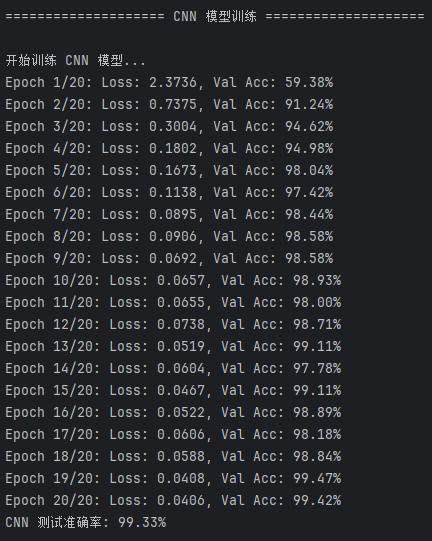
图47 CNN 模型的训练损失与验证准确率收敛过程及测试结果
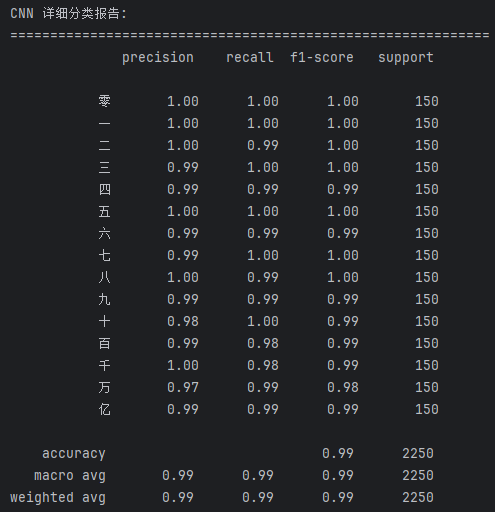
图48 CNN 模型在测试集上的详细分类报告
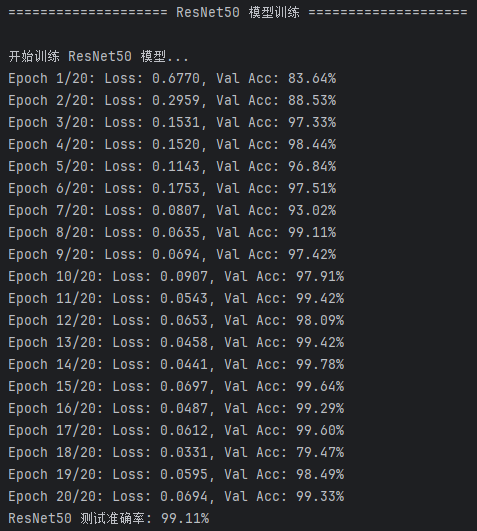
图49 ResNet50 模型的训练损失与验证准确率收敛过程及测试结果
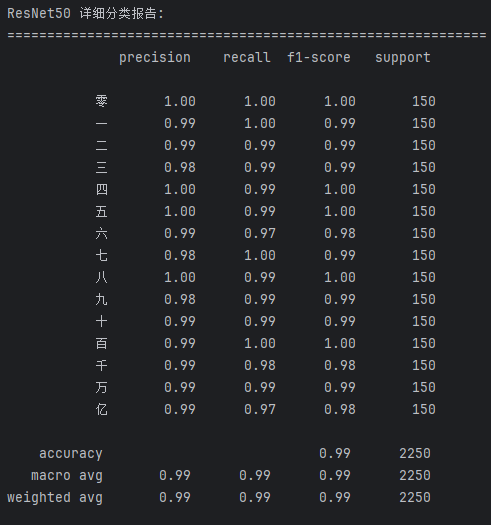
图50 ResNet50 模型在测试集上的详细分类报告
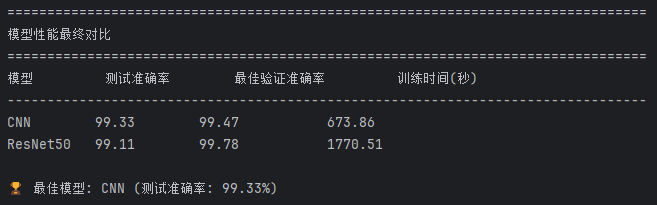
图51 CNN 与 ResNet50 模型在测试准确率与训练时间上的对比

图52 训练结束后自动生成的模型文件与分析图表列表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









