



A线程读取busy变量,B线程更新busy变量,当A检测到busy变化后执行特定操作,这样可行吗?既然通过volatile修饰后可以确保每次都从内存中读取busy,那么应该可以这样使用吧。
学C语言时有一个奇怪的关键字volatile,这到底有什么用呢?
volatile与编译器
首先来看这样一段代码:
int busy = 1;
void wait() {
while(busy) {
;
}
}
编译一下,注意,这里使用O2优化:
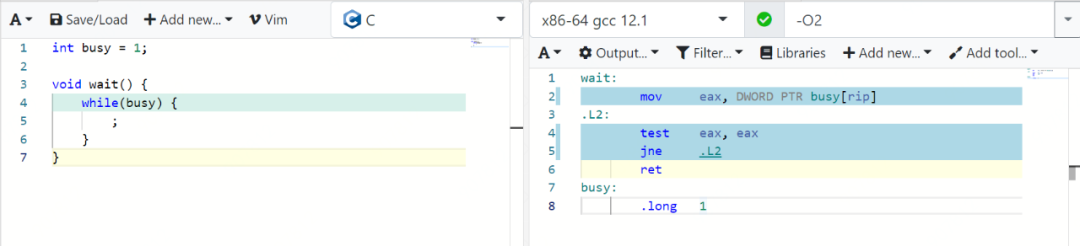
让我们仔细看看生成的这段汇编:
wait:
mov eax, DWORD PTR busy[rip]
.L2:
test eax, eax
jne .L2
ret
busy:
.long 1
其中L2这一段即为while循环,这段指令是经过编译器优化的,可以看到,决定能否跳出循环是通过检查寄存器eax来完成的,而没有检查变量busy所在内存的真实内容。
注意,对于这段代码来说这里的优化是正确的,但问题是如果还有其它代码修改了变量busy,那么这里的优化会导致其它代码对变量busy的修改根本就不能生效,就像这样:
int busy = 1;
// 该函数在A线程中执行
void wait() {
while(busy) {
;
}
}
// 该函数在B线程中执行
void signal() {
busy = 0;
}
如果wait函数中while循环对应的机器指令仅仅从寄存器中读取数据那么即使B线程的signal函数修改了busy变量也不能让wait函数从循环中跳出来。
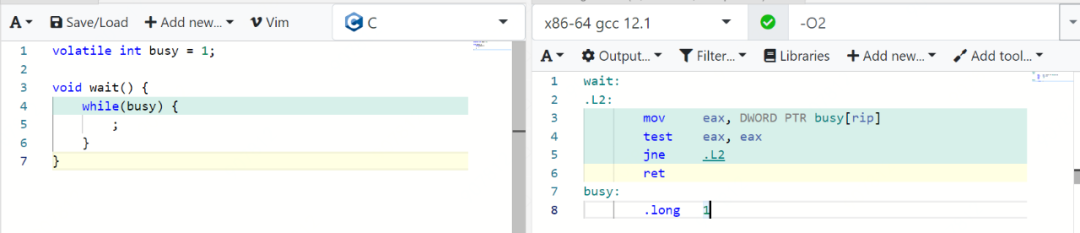
如果你对busy变量使用volatile修饰,生成的指令就变成这样了:
wait:
.L2:
mov eax, DWORD PTR busy[rip]
test eax, eax
jne .L2
ret
busy:
.long 1
注意看此时L2这一段,每次都从busy变量所在的内存中读取数据并存放在eax,然后再去判断,这样就能确保每次都能读取到busy变量的最新值。
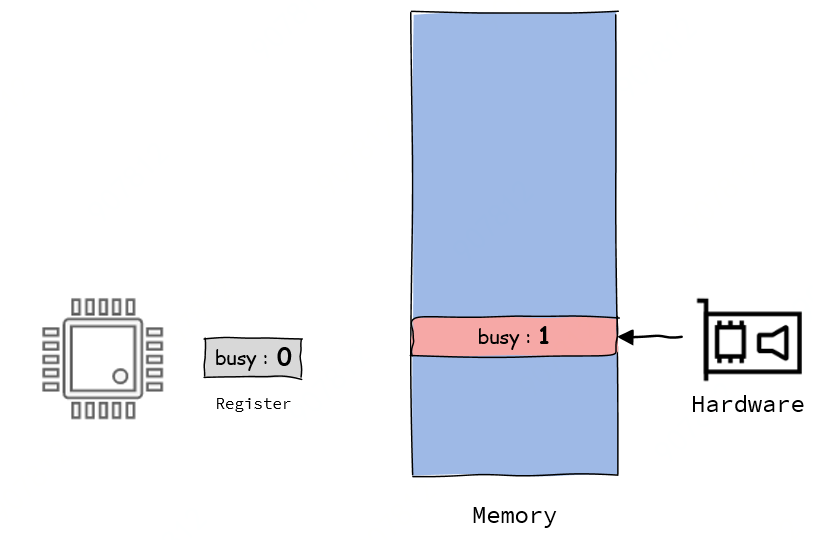
实际上你可以把寄存器eax当做busy所在内存的cache,当cache(寄存器)和内存中的数据一致时不会有任何问题,但当cache与内存中的数据不一致时(也就是内存已被更新但cache保存的还是旧数据),程序的运行往往出乎预料。
除了多线程的例子,还有一类就是signal handler以及硬件修改该变量(用C语言与硬件交互式时经常遇到),如果编译器生成文章开头那样的指令那么等待线程将检测不到signal handler或者硬件对变量的修改。
因此在这里我们需要告诉编译器:“不要耍小聪明,不要只从寄存器中读数据,这个变量可能在其它地方已经被修改了,使用时从内存中获取最新数据”。
现在是时候简单总结一下了,volatile仅仅阻止编译器试图去优化对变量的读取操作。
volatile与多线程
一定要注意volatile仅仅确保变量的可见性,但和变量的原子访问没有半毛钱关系,这是两个完全不同的任务。
假设有一个非常复杂的结构体struct foo:
struct data {
int a;
int b;
int c;
...
};
volatile struct data foo;
void thread1() {
foo.a = 1;
foo.b = 2;
foo.c = 3;
...
}
void thread2() {
int a = foo.a;
int b = foo.b;
int c = foo.c;
...
}
你仅仅用volatile去修饰变量foo只是确保了当该变量被thread1修改后我们能在thread2中读取到最新值,但是这解决不了多线程并发读写需要原子访问foo的问题。
确保变量原子性访问一般都采用锁,当使用锁时,锁本身就包含了volatile提供能力,即,确保变量的可见性,因此当使用锁时没有必要使用volatile。
volatile与memory order
有的同学可能会想如果我想用volatile修饰的变量没有那么复杂,仅仅是一个int,就像这样:
volatileint busy = 0;
A线程读取busy变量,B线程更新busy变量,当A检测到busy变化后执行特定操作,这样可行吗?既然通过volatile修饰后可以确保每次都从内存中读取busy,那么应该可以这样使用吧。
然而,计算机在概念上可能相对简单些,但在工程实践中是复杂的。
我们知道由于CPU与内存之间的速度差异非常大,CPU与内存之间有一层cache,CPU其实并没有直接读取内存,cache的存在会让问题复杂起来,限于篇幅与本文主题这里不再展开。
为优化内存读写,CPU可能会对内存读写操作进行指令重排,reordering,带来的后果就是:假设在线程1中先后执行第N行代码与第N+1行代码,但在线程2看来却是第N+1行代码先生效,假设X的初始值为0,Y的初始值为1:
线程1 线程2
X = 10 if (!busy)
busy = 0; Y = X;
当线程2检测到busy为0后读取X的值,此时读取到的X值可能为0。
为解决这一问题,我们需要的不是volatile,volatile解决不了reordering问题,我们需要的是内存屏障,memory barrier。
内存屏障是一类机器指令,该指令对处理器在该屏障指令之前与之后的内存操作进行了限制,确保不会出现重排问题。
而内存屏障带来的效果依然能够涵盖volatile提供的功能,因此也不需要volatile。
可以看到,在多线程环境下我们几乎总是不会使用volatile关键字。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









