




很多初级架构师往往会陷入一个误区,认为“数据必须每时每刻都完全一致”,并试图用复杂的技术手段去追求这种“完美”。然而,这不仅成本极高,而且在很多场景下,这根本就是“不可能完成的任务”。
引言:分布式世界的“不可能三角”
上一篇《架构设计的核心解法与权衡艺术(三):高可用设计的核心思想 —— 冗余与故障转移》的文章中,我们探讨了如何通过“冗余”与“故障转移”这两大基石,来构建一个“永远在线”的高可用系统。我们学会了如何为系统设计“备份”和“Plan B”,以应对各种突如其来的故障。然而,当我们把一个单体系统拆分成多个微服务,并将它们部署在由成百上千台机器组成的分布式集群中时,一个比“宕机”更隐蔽、更棘手的幽灵便随之而来——数据不一致。
请想象这样一个场景:
- 用户在订单服务中支付成功,账户余额已被扣除。
- 但由于一次网络抖动,下游的履约服务却迟迟没有收到“已支付”的通知,导致仓库迟迟不发货。
- 用户看到的是:“钱扣了,货不动”。客服接到的是用户的愤怒投诉。而工程师面对的,是两边系统状态不一致的“烂摊子”。
在单体应用中,我们有数据库ACID这把“尚方宝剑”,可以轻松保证“要么都成功,要么都失败”。但在分布式世界里,数据被分散在不同的服务、不同的数据库中,一次业务操作需要跨越网络进行多次调用,ACID这把“宝剑”瞬间变得“鞭长莫及”。
如何确保在这样一个充满不确定性的分布式环境中,数据在不同部分之间依然能够保持正确和同步?这就是数据一致性要解决的核心问题。
很多初级架构师往往会陷入一个误区,认为“数据必须每时每刻都完全一致”,并试图用复杂的技术手段去追求这种“完美”。然而,这不仅成本极高,而且在很多场景下,根据著名的CAP理论,这根本就是“不可能完成的任务”。
本文我们将深入这个分布式系统的核心“无人区”。我们将从CAP和BASE两大理论基石出发,为大家提供一个清晰的、可落地的数据一致性决策框架。我们的核心目标,是让大家深刻理解:一致性不是只有“0”(完全不一致)和“1”(完全强一致)两个选项,而是一个需要精妙权衡的光谱。 作为架构师,我们的职责,正是要成为一名“业务翻译官”,精准地理解业务对一致性的容忍度,并以此为标尺,选择成本最优、最适合的架构方案。
一、 理论基石:理解世界的规则 —— CAP与BASE
在讨论任何解决方案之前,我们必须先理解这个分布式世界的基本物理规则。CAP和BASE理论,就是我们必须遵守的“两大定律”。
1. CAP理论:不可逾越的“三选二”
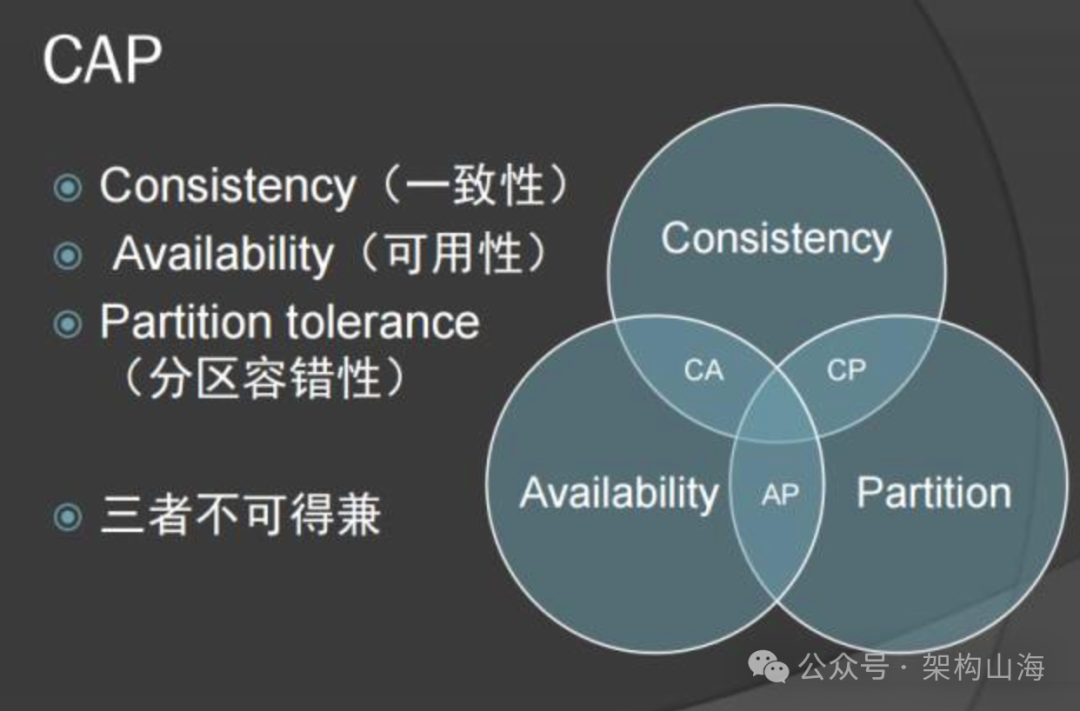
2000年,Eric Brewer教授提出了著名的CAP理论,这是一个令人沮丧的理论,但它如同分布式领域的“能量守恒定律”,深刻地揭示了任何一个分布式系统都无法回避的铁律。
CAP理论指出,一个分布式系统,在以下三个核心指标中,最多只能同时满足两项:
-
一致性 (Consistency):这里的“C”指的是强一致性。它要求任何一个读操作,都必须能读到在此之前已完成的、最新的写操作结果。换句话说,一旦写入成功,所有后续的读取,看到的都必须是这个新数据。
-
可用性 (Availability):系统必须永远处于可响应的状态。每一次请求,无论成功或失败,都必须在有限的时间内返回结果,不能出现“无响应”或“超时”的情况。
-
分区容错性 (Partition Tolerance):分布式系统由多个通过网络连接的节点组成。网络是不可靠的,节点间的通信随时可能中断(即产生“网络分区”)。分区容错性,要求系统在遭遇任何网络分区的情况下,依然能够继续对外提供服务。
关键的权衡:在一个现代的、跨越多台服务器的分布式系统中,网络分区(P)是一个必然会发生的、无法回避的客观事实。我们必须设计能够容忍它的系统。因此,CAP理论的真正抉择,是在“当网络分区发生时,我们选择牺牲C还是牺牲A?”
-
选择CP (放弃A):当网络分区发生时(例如,主从数据库之间的网络断了),为了保证数据的一致性(主从数据必须一致),系统会拒绝服务(例如,主库拒绝所有写操作),直到网络恢复。这就牺牲了可用性。
-
选择AP (放弃C):当网络分区发生时,为了保证系统依然可用(例如,用户还能继续下单),系统会允许在不同的分区继续操作(例如,两个区的用户都能下单),但这可能会导致数据的不一致(例如,库存数据在两个区不一致)。系统承诺会在网络恢复后,再通过某种方式修复数据,使其最终达到一致。
2. BASE理论:为可用性而生的设计哲学
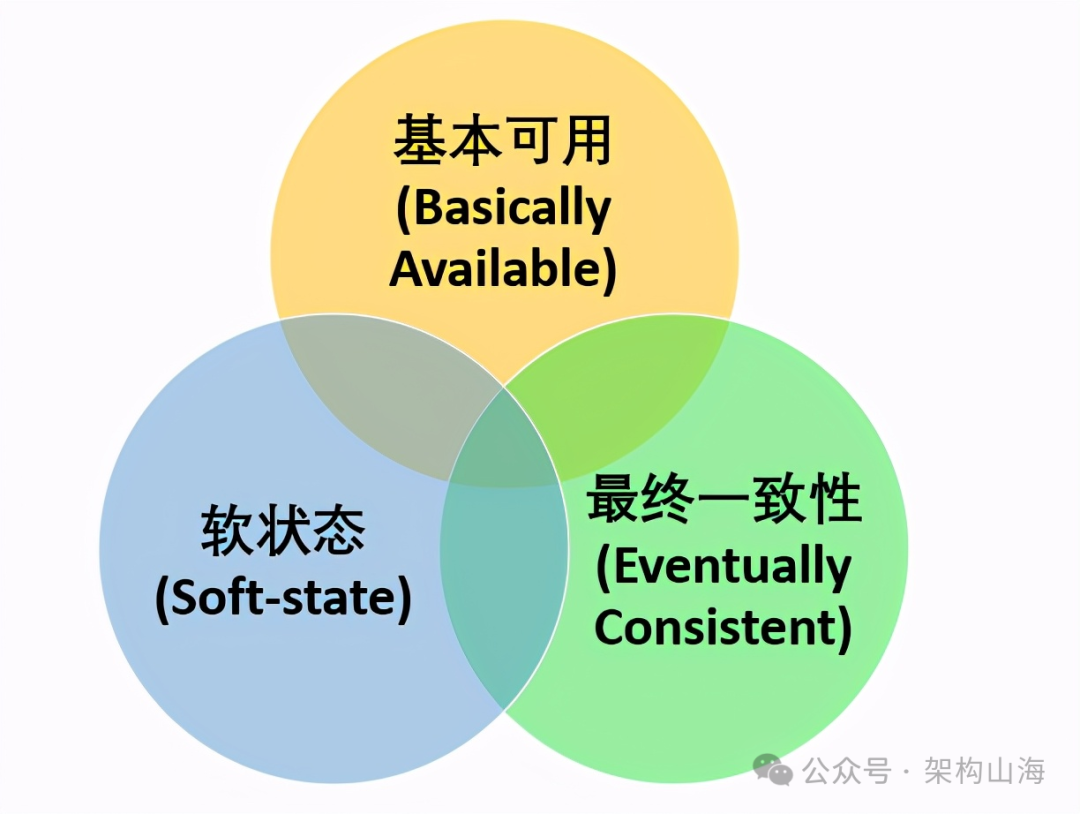
如果说CAP理论提出了一个“两难”的抉择,那么BASE理论,就是沿着“AP”这条道路,演化出的一整套优雅、实用的设计哲学。它被广泛应用于当今绝大多数大型互联网系统中。
BASE是三个词的缩写:
-
基本可用 (Basically Available):系统承诺“基本”上是可用的。它允许在发生故障时,损失部分功能(如降级),或损失部分数据质量(如返回非最新的数据),但绝不“宕机”。
-
软状态 (Soft State):系统的状态,可以存在一个“中间状态”或“临时不一致”的状态。这个状态会随着时间的推移,自己演化和变化,而无需外部干预。
-
最终一致性 (Eventually Consistent):这是BASE理论的核心。系统不保证任何时刻数据都是强一致的,但承诺“最终”会达到一致的状态。如果在一个时间段后,没有新的更新操作,那么系统中的所有副本,最终都会返回相同的值。
一言以蔽之,BASE理论的核心思想是:我们用牺牲“强一致性”为代价,来换取系统的“高可用性”和“可扩展性”。 这是一种务实的、面向失败设计的工程智慧。
二、 决策模型:一致性光谱与方案工具箱
理解了理论,我们现在需要一个实用的决策模型。我们可以将一致性想象成一个光谱:
-
光谱左端:强一致性。数据绝对正确,但性能、可用性和复杂性成本极高。
-
光谱右端:最终一致性。系统高度可用、可扩展,但需要容忍数据的短暂不一致。
架构师的工作,就是为每一个业务场景,在这个光谱上找到一个最合适的“落点”。
1. 光谱左端:强一致性的“核武器”——分布式事务
在某些极端场景下,我们别无选择,必须保证跨多个服务的操作,具备ACID一样的原子性。这就是分布式事务。
-
何时需要? 核心原则是:当数据的不一致会导致直接的、不可逆的经济损失或核心业务逻辑错误时。 最典型的就是涉及“钱”和“库存”的场景。
-
解决方案1:两阶段提交 (2PC/XA)
-
原理:引入一个“协调者”的角色,将事务分为“准备(Prepare)”和“提交(Commit)”两个阶段。协调者先问所有参与者“你们准备好了吗?”,只有所有人都回答“好了”,协调者才会下令“一起提交!”;只要有一个人说“没准备好”,就下令“全体回滚!”。
-
代价:
-
同步阻塞:在整个事务期间,所有参与者的资源都会被锁定,性能极差。
-
数据不一致风险:在第二阶段,如果协调者宕机,部分参与者可能处于状态未知的“悬挂”状态。
-
协调者单点:协调者自身的可用性成为瓶颈。
-
- 结论:因其巨大的性能开销和复杂性,2PC在现代高性能互联网架构中,已基本被弃用。了解它,是为了知道我们应该“避免”什么。
-
2. 光谱右端:最终一致性的“瑞士军刀”
对于绝大多数业务场景,最终一致性都是更明智、更具性价比的选择。我们有丰富的“工具”来实现它。
-
解决方案1:TCC (Try-Confirm-Cancel)
-
原理:这是一种“补偿型”的事务模式。将一个业务操作,拆分成三个独立的、幂等的接口:
-
Try:检查并预留业务资源。例如,冻结用户100元钱,预扣商品库存。
-
Cancel:如果任何一个参与者的Try失败了,则调用所有已成功执行Try的服务的Cancel接口,释放预留的资源。例如,解冻那100元钱,恢复预扣的库存。
-
Confirm:如果所有参与者的Try都成功了,则调用所有人的Confirm接口,真正执行业务。例如,将冻结的100元划转,将预扣的库存真正减掉。
-
优点:能够实现接近强一致的业务正确性,回滚逻辑清晰。
-
缺点:对业务代码的侵入性极强,需要为每个服务都实现TCC三套接口,开发成本很高。
-
-
解决方案2:Saga模式
-
原理:将一个长业务流程,拆分成一系列的本地事务,并串联起来。每个本地事务完成自己的数据库操作后,会发布一个事件,来触发下一个本地事务。如果中间某个环节失败,Saga会启动一个“补偿事务”链,按相反的顺序,依次撤销之前已完成的操作。
-
优点:
-
无长期锁定,性能好,吞吐量高。
-
服务间松耦合,符合事件驱动的思想。
-
-
缺点:
-
没有隔离性:在事务A完成,但事务B还未完成的“中间状态”,其他请求可能会看到不一致的数据。
-
补偿逻辑复杂:设计和实现可靠的补偿事务,本身就极具挑战。
-
-
-
解决方案3:本地消息表 / 事务性发件箱 (Transactional Outbox)
-
原理:这是最常用、也最优雅的一种实现方式。它解决了“如何原子性地完成数据库操作,并发送一个消息?”这个核心问题。
-
在同一个本地事务中,既执行业务数据的增删改,又向同一数据库中的一张“发件箱(Outbox)”表里,插入一条消息记录。
-
投递成功后,将该消息记录从“发件箱”表中删除或标记为“已发送”。
-
一个独立的、可靠的消息中继服务,会持续地轮询这张“发件箱”表,将里面的消息,安全地投递到真正的消息队列(如RocketMQ)中。
-
业务事务提交成功,“发件箱”表里的消息也必然成功写入。
-
优点:完美地保证了“只要业务成功,消息就一定能发出去”。实现相对简单,对业务代码侵入小,性能好。
-
缺点:消息的发送存在一定的延迟(取决于轮询频率)。
-
三、 架构师的决策框架

面对如此多的理论和方案,我们如何做出正确的选择?以下是一个四步决策框架:
第一步:分析业务场景,量化“不一致”的代价
这是最关键的一步。你需要和产品、业务方一起,回答这个灵魂问题:“如果数据在X秒/分钟/小时内不一致,会发生什么?最坏的结果是什么?”
-
是不可逆的经济损失吗? (例如,钱算错了,库存卖超了)
-
是糟糕的用户体验吗? (例如,用户等级没及时更新,看不到尊贵标识)
-
是内部数据报表的延迟吗? (例如,运营人员看到的销售数据不是最新的)
通过这个问题的答案,我们可以将业务场景,划分到不同的“一致性容忍度”等级。
第二步:默认选择“最终一致性”
这是现代分布式架构设计的黄金法则。永远优先考虑使用最终一致性方案。因为它能为你的系统,带来最好的可用性、可扩展性和性能。你要假设,你的默认武器,就是Saga或本地消息表。
第三步:用充分的理由,来捍卫“强一致性”
只有当第一步的分析结果,明确地告诉你“短暂的不一致将导致灾难性后果”时,你才应该、也才必须去考虑强一致性方案。此时,你必须像一个律师一样,准备好充分的证据,向团队和管理者解释,为什么我们愿意为了这个场景,付出极高的性能、可用性和复杂性代价。
第四步:选择最“恰当”的实现模式
-
如果必须强一致:首先思考,能否通过调整服务边界,将多个操作合并到一个服务的本地事务中? 这是最高明、成本最低的“伪”分布式事务方案。如果不行,再万不得已地考虑TCC(如果业务逻辑允许预留和补偿)。
-
如果选择最终一致:
-
如果你只是想在本地事务成功后,可靠地通知下游系统,本地消息表是你的首选。
-
如果你正在处理一个步骤清晰、流程较长的业务,并且每个步骤都需要明确的补偿逻辑,Saga模式更适合。
-
四、 案例对比:库存与用户等级

让我们用这个框架,来分析两个经典的电商场景。
场景A:“支付成功后,扣减商品库存”
-
分析代价:如果因为不一致,导致库存少扣,造成超卖(卖出了超过库存量的商品),后果是:需要向用户道歉、赔偿,公司声誉和经济双重受损。这是不可接受的。
-
默认选项:最终一致性?不行,无法接受“先发货,再发现是超卖”的局面。
-
捍卫强一致:理由充分。库存的准确性,是电商交易的生命线。我们必须为此付出代价。
-
选择方案:
-
最优解(架构调整):在设计服务边界时,就将“订单”和“库存”的核心变更操作,放在同一个服务(如交易中心)中,使用同一个数据库。这样,创建订单和扣减库存,就可以放在一个本地ACID事务里完成,完美避开了分布式事务。
-
次优解(技术方案):如果因为客观原因,库存是独立服务,那么在“下单”这个关键操作上,订单服务对库存服务的调用,可以使用TCC模式。下单时,先
Try预扣库存,支付成功后Confirm真正扣减。这个是大型电商的普遍做法。
场景B:“用户下单付款后,根据消费金额更新其会员等级”
-
分析代价:如果用户在下单后等级没能立即从“白银”更新到“黄金”,最坏的结果是,用户在接下来的几秒钟内,无法享受到“黄金会员”的包邮服务或折扣。这个体验不好,但不是灾难,且事后可以补偿(例如,补差价、送优惠券)。
-
默认选项:最终一致性。完全可以接受。
-
捍卫强一致:没有理由。为这个场景上TCC或2PC,是典型的高射炮打蚊子。
-
选择方案:本地消息表+补偿是完美的选择。
-
订单服务在支付成功的本地事务中,向自己的“发件箱”表插入一条
OrderPaid事件(包含用户ID和消费金额)。 -
消息中继将此事件发送到RocketMQ。
-
会员服务订阅此事件,消费消息,从容地计算并更新用户等级。整个过程,与核心交易链路完全解耦,可靠且高效。
其实,当年在天猫超市做某个权益活动的时候,由于猫超是要调用淘宝的用户服务(UIC),但是UIC的数据可能会有更新失败导致猫超数据不一致,这个时候就需要有个定时补偿任务来检查。当时猫超的元稹大佬给的建议要用定时任务做检查然后做补偿,我还很不理解,觉得淘宝怎么可能会不可靠,但还是执行了,后来发现真的出现了数据不一致,还好有补偿,不然就会有各种线上问题出现。这就是典型的面向失败的设计,在此也纪念一下元稹大佬。
结语:一致性,是架构师对业务的深刻洞察
今天,我们穿越了分布式世界里最复杂、也最迷人的一片“深水区”。我们明白了,数据一致性不是一个纯粹的技术问题,它本质上是一个业务决策问题。
作为架构师,我们不能再简单地将世界分为“对”与“错”,而要学会用“光谱”的思维,去度量“利”与“弊”。我们手中的TCC、Saga、本地消息表,就像是不同精度、不同成本的工具,而驱动我们选择哪一把工具的,永远是我们对业务场景、对用户体验、对商业价值的深刻洞察。
请记住,追求100%的强一致性,就像试图在现实世界中建造一座绝对刚性的摩天大楼,它不仅造价昂贵,也最容易在风暴中折断。而一个拥抱最终一致性、充满弹性的系统,才更像一棵懂得随风摇曳的竹子,柔韧而充满生命力。在你的下一次架构设计中,请勇敢地拥抱这种“柔韧”,因为它将为你的系统,带来更广阔的生存空间。

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









