




作为架构师,我们的职责,不仅仅是设计出“能跑”的系统,更是要设计出“能被理解、能被掌控”的系统。
引言
至此,我们已经学习了如何构建高并发、高可用、可扩展且安全的系统。我们的系统已经被设计得足够坚固、灵活且安全。但是,想象一下,你现在是一位经验丰富的飞行员,正准备驾驶一架由我们亲手打造的、最先进的波音747客机。当你坐进驾驶舱后却发现,整个驾驶舱里,空空如也——没有高度计,没有速度表,没有引擎温度计,甚至连一个警告灯都没有。你唯一能知道的,就是飞机还在飞,或者,已经掉了下去。
请问,你敢驾驶这样一架飞机吗?
这听起来像一个笑话,但这正是很多中小企业的开发团队在日常运维一个复杂分布式系统时的真实写照。一个没有良好可观测性(Observability)的系统,就是一架没有仪表的飞机,一个“黑盒”。当问题发生时:
-
用户抱怨:“你们的网站太慢了!” —— 你不知道是哪里慢,为什么慢。
-
告警响起:“订单创建成功率下降!” —— 你不知道是哪个环节出了问题,影响了多少用户。
-
业务问你:“昨晚的故障到底是什么原因?” —— 你只能和团队一起,大海捞针般地翻阅着散落在上百台服务器上的、格式混乱的日志,祈祷能找到一丝线索。
这种被动的、靠“猜”来定位问题的状态,不仅极大地消耗着研发团队的精力,更直接影响着业务的稳定性和用户的信任。
作为《架构设计的核心解法与权衡艺术》系列的最后一篇文章,本文的核心任务就是要彻底终结这种“黑盒”困境。我们将学习一套系统性的可观测性设计方法,帮助大家成为一名能为飞机装上全套“精密仪表”的架构师。我们将深入讲解可观测性的三大支柱:日志(Logging)、指标(Metrics)和链路追踪(Tracing)。我们将学习如何在架构设计阶段,就将可观测性作为与生俱来的“一等公民”来规划,从而构建出一个内部状态完全透明、可追踪、可分析的“白盒”系统,极大地提升我们诊断故障、分析性能、分析链路的效率和能力。
一、 重新定义问题:监控 vs. 可观测性
在深入三大支柱之前,我们必须先厘清一个重要的概念:监控与可观测性的区别。
-
监控只是“提问”:它是一种被动的行为。我们预先定义好我们关心的问题(例如,“CPU使用率是多少?”、“QPS有多高?”),然后通过仪表盘来持续观察这些问题的答案。监控告诉我们系统是否在正常工作。
-
可观测性主要是“回答”:它包含了监控,但更重要的是还能够对系统问题进行定位和分析。一个具备可观测性的系统,允许我们在事后,提出任意的、事先未曾预料到的问题,并能从系统暴露出的数据中,找到答案。
在简单的单体应用时代,监控或许就已足够。但在今天我们面对的、由成百上千个微服务组成的复杂分布式系统中,故障的模式千奇百怪、层出不穷。我们不可能预知所有可能的问题。因此,仅仅依赖预设的监控是远远不够的。我们必须在架构层面,构建起强大的可观测性,赋予我们探索未知、诊断疑难杂症的能力。
二、 可观测性的三大支柱
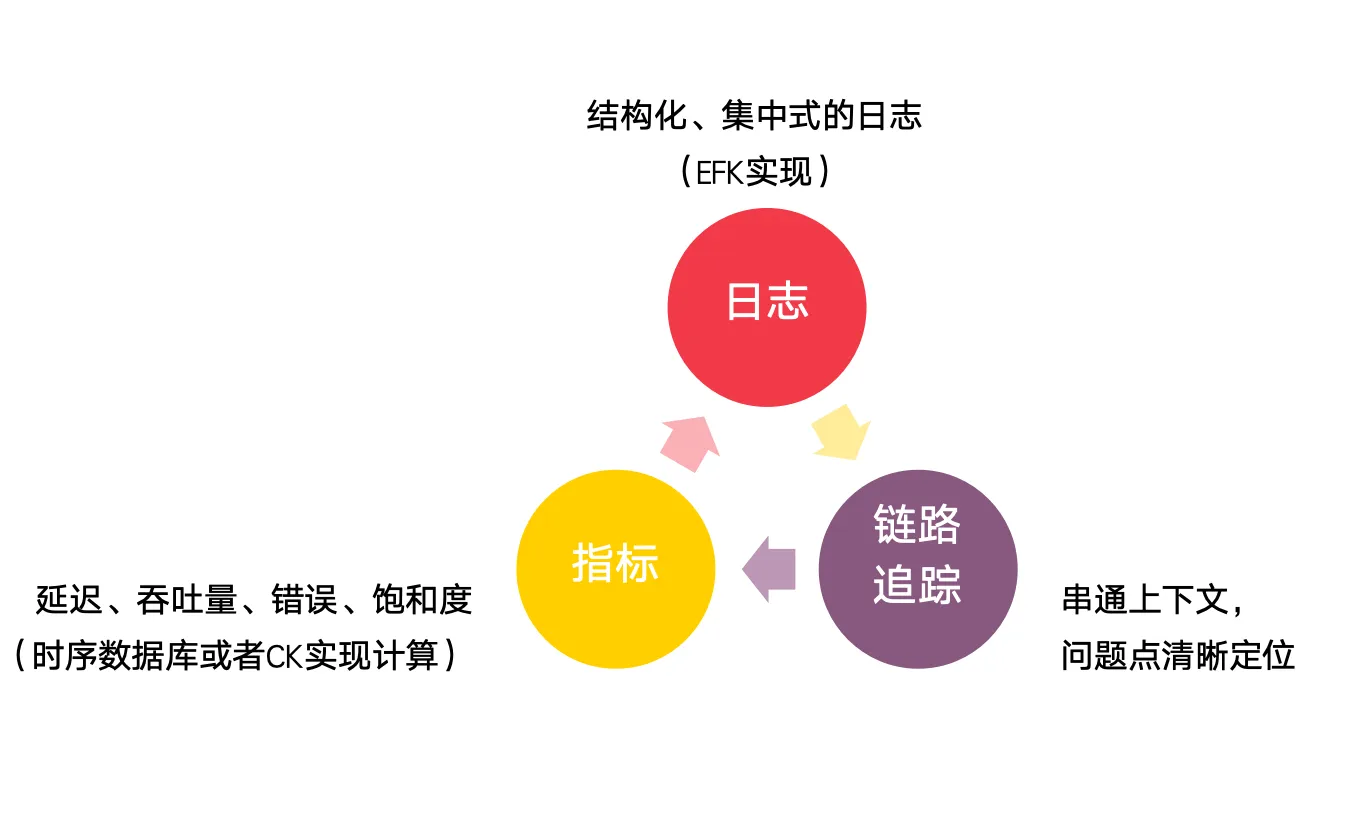
可观测性并非一个单一的技术,而是由三个相互关联、互为补充的数据源共同构建起来的。它们分别是日志、指标和链路追踪。
观测性并非一个单一的技术,而是由三个相互关联、互为补充的数据源共同构建起来的。它们分别是日志、指标和链路追踪。
1. 支柱一:日志(Logging)—— 事件的“黑匣子”
-
它是什么? 日志是离散的、带有时间戳的、描述了某个特定事件的文本记录。它是系统运行过程中,最详细、最原始的“第一手资料”。
-
架构师的关注点:
-
必须是“结构化日志”:
-
反例(非结构化):
2024-09-11 10:30:05 ERROR User 123 failed to create order 456 due to inventory lock timeout. -
正例(结构化,JSON格式):
-
-
{
"timestamp": "2024-09-11T10:30:05.123Z",
"level": "ERROR",
"message": "Failed to create order",
"service": "order-service",
"user_id": "123",
"order_id": "456",
"error_code": "E5001",
"reason": "inventory lock timeout",
"stack_trace": "..."
}
非结构化日志对机器极不友好,难以进行有效的检索和聚合分析。作为架构师,必须在系统实现中,强制要求所有应用输出结构化的日志,这是一种非常重要的技术规范。
-
必须是“集中式日志”:
在微服务架构中,一个请求可能会流经数十个服务,每个服务又有多台实例。日志散落在各处,根本无法排查问题。因此,架构师必须规划和推动一个集中式的日志解决方案(如使用ELK Stack、Loki、Splunk等),将所有服务的日志,实时地汇集到一个统一的、可供检索和分析的平台。
-
日志内容“三要三不要”:
-
要包含丰富的上下文:如
user_id,order_id等业务ID,以及后续会讲到的trace_id。 -
要在错误日志中包含完整的堆栈信息。
-
要包含明确的日志级别:
DEBUG,INFO,WARN,ERROR,用于区分信息的重要性。 -
不要打印无意义的“天书”日志,每一条日志都应有其明确的意图。
-
不要过度打印
DEBUG日志到生产环境,以免造成性能问题和存储浪费。 -
不要记录任何敏感信息:如密码、身份证、银行卡号等。这是安全红线。
-
2. 支柱二:指标(Metrics)—— 系统的“驾驶舱仪表盘”
-
它是什么? 指标是在一段时间内,可聚合的、数值型的测量数据。它告诉我们系统的宏观运行状态和趋势。
-
架构师的思考点:
-
定义“黄金指标”:Google的SRE团队总结的“四大黄金指标”是衡量一个服务健康度的普适标准,作为架构师,需要确保每个核心服务,都暴露了这些标准化的黄金指标:
-
延迟:服务处理请求所需的时间。需要关注平均值,更要关注P95/P99等长尾延迟。
-
饱和度:衡量系统资源(CPU、内存、磁盘、网络)有多“满”,以及距离容量上限还有多远。
-
错误:请求失败的速率,如HTTP 5xx错误的占比。
-
吞吐量:衡量系统负载的指标,如每秒请求数(QPS/RPS)。
-
-
区分“业务指标”与“系统指标”:除了技术层面的系统指标,我们更需要从业务视角,定义和监控业务指标。例如,“每分钟下单量”、“支付成功率”、“用户注册数”等。将业务指标与系统指标放在同一个仪表盘上,可以帮助我们快速关联技术问题与业务影响。
-
推动“标准化”与“自动化”:架构师需要选定一个统一的指标监控技术栈(如Prometheus + Grafana),并推动建立一套标准化的指标命名和标签规范。例如,所有HTTP接口的延迟指标,都应命名为http_server_requests_seconds,并带有service, endpoint, method, status_code等标准标签。这使得跨团队的聚合分析和仪表盘制作成为可能。
-
3. 支柱三:链路追踪(Tracing)—— 请求的“GPS导航轨迹”
-
它是什么? 链路追踪记录了单个请求,从开始到结束,在分布式系统中流经所有服务的完整路径和耗时。
-
架构师的思考点:
-
理解核心概念:
-
Trace:代表一个完整的请求链路,由一个全局唯一的
Trace ID标识。 -
Span:代表链路中的一个工作单元或一次调用(如一次RPC、一次数据库查询),由一个
Span ID标识。一个Trace由多个Span组成的父子或并列关系的树状结构。
-
-
确保“上下文传播”:链路追踪能够工作的核心,在于Trace Context(如Trace ID, Span ID)能够在服务的每一次调用中,被完整地传递下去。这通常通过HTTP Header(如W3C Trace Context标准定义的traceparent头)来实现。作为架构师,必须确保公司的API网关、RPC框架、消息队列等基础组件,都原生支持或被改造为支持链路上下文的自动传播。这是链路追踪能否落地的技术基石。
-
实现“三位一体”的关联:链路追踪的威力,在与日志和指标打通后,才能发挥到极致。架构师需要推动:
-
在所有结构化日志中,自动注入当前的Trace ID和Span ID。
-
在指标的标签中,可以关联到Trace信息。
-
-
2023年我负责所在公司的大促性能保障,虽然最终大促的稳定性得到了极大的保障,但是在这个过程中,我发现研发团队并没有一套可观测系统,性能指标不清楚、trace串不起来,出现问题后一群人跑来跑去、吼来吼去。
作为首席架构师,这是责无旁贷的。于是大促结束后就开始筹备建设可观测的「Thea」平台,将各个业务域的指标监控起来,到次年的618备战前夕,我们再也不是凭感觉“盲打”。后续又不断增加了告警等功能,逐步完善可观测性。
三、 案例实战:一次“神秘”的下单失败
让我们通过一个真实的案例,来看看这三大支柱是如何协同作战,将一个“黑盒”问题,变成一次清晰、高效的“白盒”排查。
故障现象:某天下午,客服开始收到用户反馈,点击“提交订单”按钮后,页面会转圈很久,最后提示“下单失败,请稍后重试”。
反例. “黑盒”模式下的混乱排查:
1. 接到反馈,前端、订单服务、支付服务、库存服务的工程师被拉到一个紧急会议群。
2. 前端说:“我看了浏览器抓包,就是调用/api/orders接口超时了,后端的问题。”
3. 订单服务负责人说:“我看了我们服务的日志,有很多WARN,但没有明显的ERROR,CPU和内存也都正常。”
4. 支付服务和库存服务负责人也表示,自己的服务看起来一切正常。
5. 大家陷入僵局,开始漫无目的地在各自的服务器上手动grep日志,希望能找到蛛丝马迹。半小时过去了,问题依旧毫无头绪,影响范围在持续扩大……
正例. “白盒”模式下的精准定位:
1. 第一步(发现问题 - 指标):负责订单服务的工程师收到了订单超时的告警通知,然后打开Grafana上的核心业务仪表盘。他立刻看到:
-
orders_creation_qps(下单QPS)指标,出现明显下跌。 -
http_server_requests_seconds_p99{endpoint="/api/orders"}(下单接口P99延迟)指标,从平时的200ms,飙升到了30s。 -
http_server_requests_total{status_code="5xx"}(下单接口错误率)指标,从0%上升到了60%。
结论在1分钟内得到:问题明确出在/api/orders这个核心接口上,表现为延迟急剧升高和大量错误。
2. 第二步(定位边界 - 链路追踪):工程师立即切换到Skywalking链路追踪系统,筛选出过去15分钟内,所有标记为“Error”的、访问/api/orders的Trace。
-
他随机点开一条红色的、耗时30s的Trace。
-
这条Trace的调用链路清晰地展示了请求的完整旅程:
-
api-gateway: 5ms -
order-service: 30000ms (父Span)-
-> user-service: 10ms (子Span, OK) -
-> coupon-service: 20ms (子Span, OK) -
-> inventory-service: 29950ms (子Span, Error)
-
-
-
结论在3分钟内得出:问题的根源,不在订单服务本身,而在于它对库存服务(inventory-service)的一次同步RPC调用上。这次调用消耗了将近30秒,并最终失败。
3. 第三步(追溯根因 - 日志):工程师复制了这条Trace的Trace ID。
-
他切换到Kibana集中式日志平台,在搜索框中输入:
trace.id: "xxxxxxxxx"。 -
所有与这次失败请求相关的、来自不同服务的日志,瞬间被全部筛选出来,并按时间线排列。
-
他将日志过滤条件,进一步 narrowing down 到
service: "inventory-service"。 -
一条刺眼的
ERROR级别的结构化日志出现在眼前:
{
"timestamp": "...", "level": "ERROR",
"service": "inventory-service",
"trace.id": "xxxxxxxxx",
"span.id": "yyyyyyyyy",
"message": "Failed to lock inventory for product xxx",
"reason": "java.sql.SQLException: Deadlock found when trying to get lock; try restarting transaction",
"sql": "UPDATE inventory SET stock = stock - 1 WHERE product_id = 321 AND stock > 0"
}
最终结论(5分钟内)得出:根本原因找到了! 库存服务在更新商品库存时,发生了数据库死锁。这导致了调用超时,进而引发了整个下单链路的失败。
接下来,DBA和库存服务的工程师可以立即介入,分析该SQL的锁竞争问题,并快速给出解决方案。一场原本可能需要数小时才能解决的“神秘”故障,在可观测性体系的帮助下,在5分钟内就完成了从“发现”到“定位”再到“定因”的全过程。
看到这里,肯定会有小伙伴立马指出:如果库存的负责人有监控,他第一时间收到监控告警不就直接发现和解决问题了吗?诚然,这是没错的。但是对于大型分布式系统而言,动辄都要几百上千台机器,各种应用、数据库之间的依赖关系是非常复杂的,各个节点需要有自己的监控而且能够串起来。如果不是这样,出问题后,一条链路上的各个团队信息不统一,各自搞各自的,研发效率极低。
结语:让掌控感,成为架构师的底气
今天,我们学习了如何通过日志、指标和链路追踪这三大支柱,来构建一个“白盒”的可观测系统。我们必须深刻地认识到,可观测性,不是一个锦上添花的“附加功能”,而是现代分布式架构的“标尺”。一个缺乏可观测性的系统,无论其功能多么强大,都如同一匹无法被驯服的野马,你永远不知道它下一次会把你甩向何方。
作为架构师,我们的职责,不仅仅是设计出“能跑”的系统,更是要设计出“能被理解、能被掌控”的系统。这意味着:
-
我们要在项目启动之初,就将统一的可观测性技术栈和规范,纳入架构设计的蓝图中。
-
我们要倡导和推动一种“谁构建,谁运维”的文化,让每一个工程师,都将为自己的代码植入“可观测性探针”,视为自己分内的工作。
最终,当我们面对线上那庞大而复杂的“数字生命体”时,我们不再感到恐惧和无力。因为我们知道,我们手中握有三大支柱提供的武器,我们有足够的信心和能力,去洞察它的每一次心跳,诊断它的每一种病症。这份源于深刻洞察的掌控感,正是一名卓越架构师真正的技术底气所在。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









