



引言
在上一篇文章,我们成功搭建了自己的“源码实验室”,在DefaultMQProducerImpl的sendDefaultImpl方法上,设下了我们的第一个断点。
按照常规路线,我们应该从这个断点开始,一步步深入客户端(Producer)的内部,去探究它如何选择Broker、如何封装网络请求。但是,为了让我们的课程更加聚焦于核心,我们将暂时跳过客户端的细节,直接穿越网络,抵达我们消息旅程的目的地,也是整个RocketMQ系统中负载最高、技术最核心的地方——Broker。
为什么Broker是“心脏”?因为所有的数据流,无论是生产者写入,还是消费者读取,都必须经过它来泵送和中转。Broker的性能,直接决定了整个集群的吞吐能力。而支撑Broker强大“心跳”的,正是其无与伦比的高性能存储机制。
你是否曾好奇:
- 为什么RocketMQ敢号称单机支持百万级的TPS写入?它究竟施展了什么“魔法”,能让磁盘I/O不再成为瓶颈?
- 如果所有Topic的消息都混在一起写入,消费者又是如何能高效地只读取到自己订阅的那部分消息,而不必遍历所有消息?
今天,我们深入Broker的存储核心,解剖其两大脉络——CommitLog与ConsumeQueue。我们将亲眼见证,一个顶级的分布式系统,是如何通过精妙的架构设计,将看似平凡的磁盘,压榨出极致的性能。
一、 写入的“魔法”:CommitLog与颠覆常识的“顺序写”
在传统的数据库或文件系统设计中,我们通常认为“磁盘I/O”是性能的主要瓶颈。我们总是小心翼翼地设计索引、减少访盘次数。然而,RocketMQ却反其道而行之,将所有收到的消息,简单粗暴地、持续不断地追加到一个巨大的文件里。这个文件,就是CommitLog。
这种设计的背后,隐藏着一个颠覆我们常识,却又无比朴素的计算机科学原理。
1. 朴素的真理:顺序写 vs. 随机写
想象一下,你有两种记笔记的方式:
- 方式一(顺序写):你拿出一个新的笔记本,从第一页第一行开始,一直往后写,写满一页再翻到下一页。
- 方式二(随机写):你的笔记内容,需要更新到笔记本中不同章节、不同页码的特定位置。你需要不停地来回翻页,找到位置,再下笔修改。
哪种方式更快?答案不言而喻。
在机械硬盘(HDD)上,这种速度差异是天壤之别的。因为硬盘的磁头需要花费大量的“寻道时间”和“旋转延迟”来定位到正确的磁道和扇区(类似你翻页的动作)。而顺序写,磁头几乎不需要移动,可以连续不断地写入数据。
即便是在固态硬盘(SSD)上,虽然其随机读写性能远超HDD,但其内部的“写入放大”等机制,也决定了顺序写的性能和寿命,依然要优于大量的随机写。
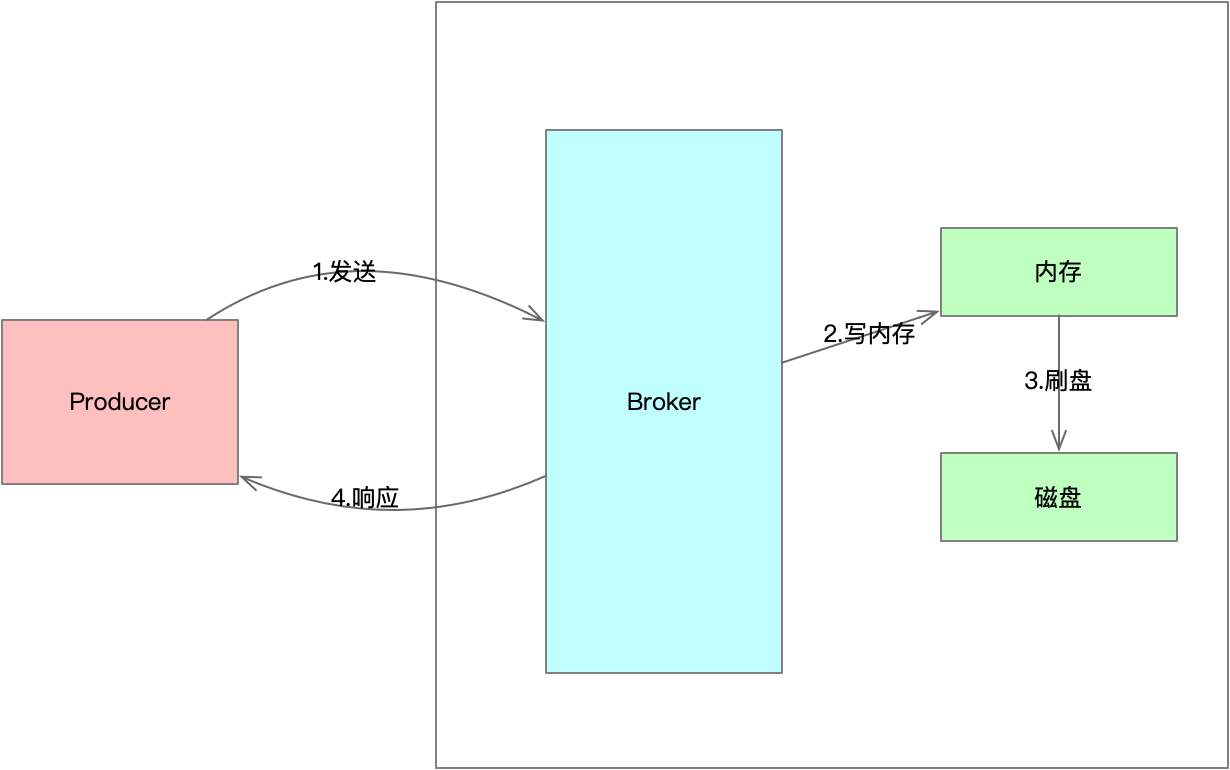
RocketMQ的第一个性能魔法,就是将所有对消息的“写入”操作,巧妙地转化为了对单个文件(CommitLog)的“顺序追加写入”。
2. CommitLog的极致设计
CommitLog是Broker中所有消息的物理存储本体。无论这条消息属于哪个Topic、哪个Queue,它都会被一视同仁地追加到CommitLog文件的末尾。
这种设计带来了几个无与伦比的好处:
- 极致的写入性能:如上所述,纯顺序I/O的性能,可以与内存写入相媲美。
- 简化数据恢复:由于消息是严格有序的,当Broker异常宕机时,只需要根据checkpoint,从上一个安全刷盘点开始,顺序恢复即可,过程非常简单快速。
3 借力操作系统:Page Cache与内存映射(mmap)
你可能会问,即便是顺序写,那也是写磁盘,怎么可能媲美内存呢?这里,RocketMQ施展了第二个,也是更关键的“魔法”——它将写入操作,最大程度地委托给了现代操作系统的“智慧”。
a. 页缓存(Page Cache):当我们向磁盘写入数据时,操作系统并不会立即、同步地将数据写入物理磁盘。它会先将数据写入到一块区域,这块区域就是Page Cache。然后,操作系统会根据自己的调度策略(比如攒够一定量的数据、或者在系统空闲时),再异步地将这块内存中的数据,刷写到磁盘上。
对于RocketMQ这样的应用来说,消息写入CommitLog,实际上绝大多数时候,只是在写内存(Page Cache),其速度自然是极快的。只要系统不宕机,这部分数据就是安全的。
b. 内存映射文件(Memory Mapped Files, mmap):为了更高效地利用Page Cache,RocketMQ使用了mmap技术。它允许应用程序将一个文件直接映射到进程的虚拟地址空间。之后,你对这块内存的读写,就像操作一个普通的内存数组一样简单,而操作系统会自动帮你处理好这块内存与对应磁盘文件之间的数据交换。
mmap相比传统的I/O方式,减少了一次内核空间到用户空间的数据拷贝,实现了所谓的“零拷贝”,进一步提升了I/O效率。
总结一下,RocketMQ的高性能写入秘诀 = 顺序写 + Page Cache + mmap。 它并非自己造出了什么黑科技,而是将基础原理和操作系统特性,运用到了极致。
- 源码入口:
org.apache.rocketmq.store.CommitLog类中的putMessage()方法,是所有消息写入的必经之路。
二、 读取的“艺术”:ConsumeQueue与CQRS思想的实践
好了,现在我们知道,所有的消息都被混在了一个巨大的CommitLog文件里。一个新的问题随之而来: 一个Consumer只想消费TOPIC_ORDER_CREATE这个主题的消息,它该如何在存储海量数据的CommitLog中,快速找到属于自己的那几条消息呢?
难道要从头到尾扫描一遍CommitLog,逐条判断消息的Topic吗?这显然是无法接受的。
为了解决这个问题,RocketMQ引入了它存储设计的另一半,也是同样闪耀着智慧光芒的设计——ConsumeQueue。
1. ConsumeQueue:轻量级的“消息索引”
ConsumeQueue可以被理解为CommitLog的“索引文件”。它遵循“关注点分离”的原则,将消息的“数据存储”和“消息的检索”这两个职责,彻底分开了。
- 物理结构:
ConsumeQueue不再是存储消息的完整内容,而是存储了固定长度的索引条目。每个Topic下的每个Message Queue,都会对应一个独立的ConsumeQueue文件。 - 索引条目:每一条索引,只包含三个关键信息,总共20个字节:
- CommitLog Offset(8字节):这条消息在
CommitLog文件中的物理起始位置。 - Message Size(4字节):这条消息的总长度。
- Tag HashCode(8字节):消息标签(Tag)的哈希值,用于服务端进行消息过滤。
- CommitLog Offset(8字节):这条消息在
2. 固定长度的魔力
为什么“固定长度”如此重要?
因为对于一个文件,如果我知道每个条目的长度是固定的(比如20字节),那么要查找第N条记录,我只需要用 N * 20 就可以直接计算出它在文件中的起始偏移量,然后进行一次随机读即可。这个查找的时间复杂度是O(1)!
这就完美地解决了高效查找的问题。当一个Consumer要拉取消息时,它的流程是:
- Consumer告诉Broker:“我要拉取
TOPIC_ORDER_CREATE下Queue-0的第100条消息开始的10条消息。” - Broker根据
Queue-0,找到对应的ConsumeQueue文件。 - 通过
100 * 20,Broker直接定位到第100条索引的位置,然后连续读取10条索引。 - 遍历这10条索引,根据每条索引中记录的
CommitLog Offset和Message Size,再到CommitLog文件中,精准地读取出消息的完整内容。
3. CQRS架构思想的完美体现
如果你对架构模式有所了解,你会立刻发现,CommitLog + ConsumeQueue的设计,是命令查询职责分离(CQRS, Command Query Responsibility Segregation)模式的一次教科书般的实践。
- 命令(Command):指所有“写入”或“修改”数据的操作。在RocketMQ中,所有消息的写入,都由
CommitLog来统一处理。它只关心一件事:如何以最快的方式把数据写进去。 - 查询(Query):指所有“读取”数据的操作。在RocketMQ中,消息的查找和消费,则由
ConsumeQueue这个专门的“读取模型”来负责。它只关心如何最高效地为消费者提供索引服务。
通过将写入模型和读取模型分离,RocketMQ得以针对性地对两者进行独立优化,最终实现了“写入快、读取也快”的双赢局面。
- 源码入口:
org.apache.rocketmq.store.DefaultMessageStore中的getMessage()方法,是消费消息时,组合ConsumeQueue和CommitLog进行查询的核心逻辑。
三、 读写旅程:一次完整的消息处理流程
现在,让我们将写入和读取的流程串联起来,欣赏一曲由Broker指挥的、优雅的“读写旅程”。
1. 【开始:消息抵达】
- 一条消息由Producer通过网络,抵达Broker。
2. 【第一步:写入】
- Broker的
SendMessageProcessor线程,调用CommitLog.putMessage()。 - 消息被加锁、顺序地追加到
CommitLog当前正在写入的文件末尾(实际上是写入Page Cache)。这个过程极度迅捷。 - 写入成功后,向Producer返回ACK。
3. 【第二步:构建索引】
- Broker内部有一个后台服务(
ReputMessageService)。 - 这个服务像一个勤劳的图书管理员,它会异步地、不断地扫描
CommitLog中新增的消息。 - 对于每一条新消息,它会解析出其Topic, QueueId, Tag等信息,然后构建一条20字节的
ConsumeQueue索引,并将其追加到对应的ConsumeQueue文件中。
4. 【第三步:读取】
- Consumer发起
PullMessage请求。 - Broker的
PullMessageProcessor线程,根据请求中的Queue和Offset,到ConsumeQueue中快速定位并读取一批索引。 - 再根据索引,回到
CommitLog中,将完整的消息内容捞取出来,返回给Consumer。
在控制台页面对消息的检索,也是从这里构建的索引文件来实现的。
这套机制,完美地平衡了性能、可靠性与功能复杂度,是整个RocketMQ架构设计的基石,也是其架构设计最精妙绝伦的部分。
结语:从“是什么”到“为什么”
今天的课程,我们深入了Broker的“心脏”,揭开了其高性能存储的两个核心秘密:
- 写入端:通过
CommitLog+ 顺序写 + mmap,将写入性能压榨到极致。 - 读取端:通过
ConsumeQueue作为轻量级索引,实现了高效的查找。 - 整体架构:通过CQRS思想,将读写模型分离,实现了两者的独立优化。
希望大家理解,我们学习这些,不仅仅是为了知道“RocketMQ是这么做的”,更重要的是要思考“它为什么要这么做?”,以及“这种思想,我能用到我自己的系统里吗?”
当你下次需要设计一个高并发的日志收集系统、一个交易流水记录系统,或者任何需要“海量写、聚合查”的场景时,RocketMQ的这套“CommitLog + Index”的思想,或许就能成为你手中最强大的武器。
核心的秘密已经揭开,但一个健壮的系统,光有强劲的心跳还不够。它还需要有面对意外的“恢复能力”和处理复杂事务的“智慧”。在下一篇文章,我们将继续探索Broker的另外两大支柱:高可用(Master/Slave)与分布式事务(事务消息)。

















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









