




 本文介绍了一种新的AI框架RAISE,通过集成长期和短期记忆系统,增强了ReAct在复杂对话任务中的控制力和适应性。实验使用贝壳房地产数据集,评估了RAISE在处理对话策略和利用LLMs的能力。
本文介绍了一种新的AI框架RAISE,通过集成长期和短期记忆系统,增强了ReAct在复杂对话任务中的控制力和适应性。实验使用贝壳房地产数据集,评估了RAISE在处理对话策略和利用LLMs的能力。
0-摘要
提出RAISE( Reasoning and Acting through Scratchpad and Examples)框架,加强版的ReAct,增加一个双重(长+短记忆)的记忆组件。表明这种框架在复杂的多轮任务中,能够提高Agent的控制能力和适应能力。
1-引言
在大模型领域的一个大的挑战是把大模型集成对话式的Agent。亟需一个更复杂的框架来利用LLM在解决其在会话环境中的局限性。本文提出RAISE,是一个加强版的ReAct框架。RAISE的主要创新在于给 ReAct增加一个双重的记忆系统,分别为长期记忆和短期记忆。便签组件的功能是作为临时存储器,捕获以及处理来自最近互动的关键信息和结论,类似于短期记忆。同时检索模块,从历史中检所和当前对话上下文相关的例子,作为长期记忆。RAISE构建了一个全面,复杂的Agent场景,从头开始构建一个AGENT,以确保真实世界交互中的真实性和相关性。
实验评估用的数据集是:房地产销售的专门内部数据集(贝壳自己的数据集)
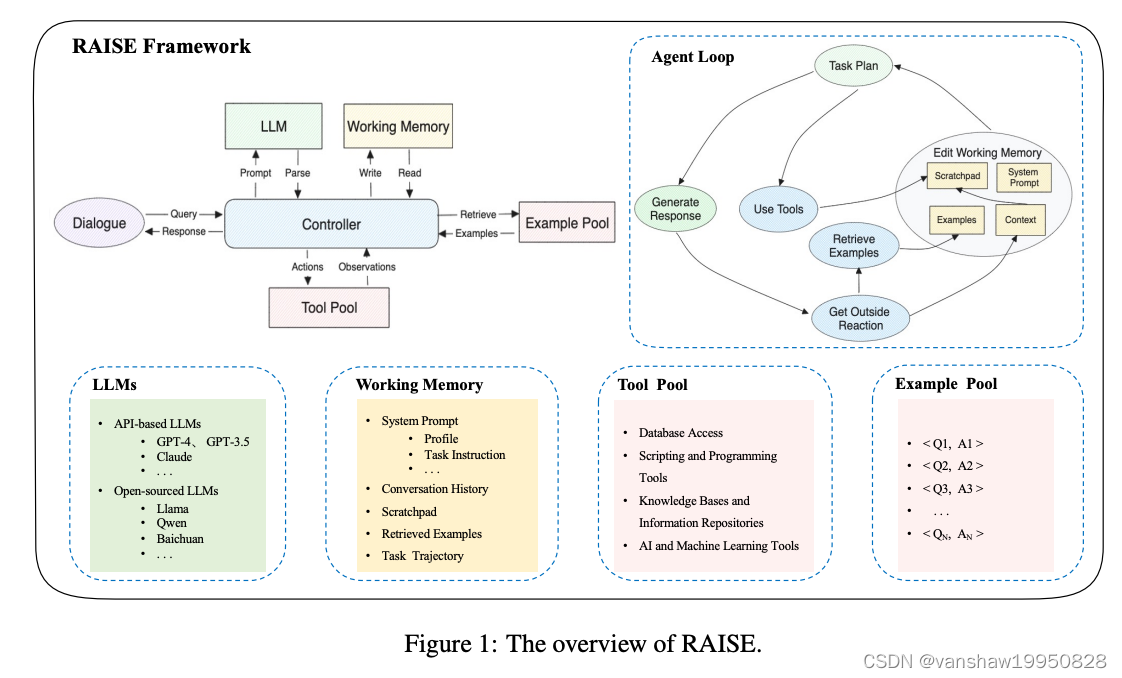
2-方法
(1)对话模块
接受用户输入,给用户输出Agent处理好的回答
(2)LLMs
agent 的大脑🧠,负责感知,根据具体任务做出计划,Tool选择,总结等等。既可以直接用Prompt工程,也可以用微调来获得。
(3)记忆模块
记忆模块帮助RAISE存储从环境中获得信息,帮助Agent做下一步的决策。记忆有以下组件构成:
- System Prompt(系统级别Prompt) :包括profile(身份定义,对象,行为等等),任务指引,工具描述,few-shot examples, system prompt 可以是静态的,也可以是动态的
- Context(上下文):包括对话上下文,任务轨迹
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









