



1. GraphRAG概述
paper: https://arxiv.org/pdf/2404.16130
github: https://github.com/microsoft/graphrag/
doc: https://microsoft.github.io/graphrag/
GraphRAG是微软开源的基于图的检索增强生成(RAG)方法,主要针对以查询为中心的摘要任务(Query-Focused Summarization, QFS)。QFS的目标是围绕用户提出的问题,生成相关信息摘要。简单说,QFS根据用户的查询,从多个信息源中提取与问题最相关的内容,并整合成清晰的答案或总结。
举个例子:假设用户的查询为“电动车的优点是什么?”,QFS会从一个或多个文档中提取与电动车优点相关的信息,例如环保性、经济性和性能,然后加以总结并回答。而不是仅仅简单地返回信息片段或者提供整个文档的总结。
传统方法在解决QFS问题时的局限性
(1)传统RAG方法:传统RAG主要用于明确的局部信息检索,其回答通常基于局部的信息片段。然而,对于较为抽象或综合性较强的问题,传统RAG难以将分散的知识点关联起来。例如,要了解“电动车的优点是什么?”,需要整合多个方面的信息,如环保特性、低运行成本和驾驶体验。通过将这些不同的信息结合起来,用户能够得出“电动车因其环保和经济性而受到青睐”的结论,但传统RAG难以有效实现这一目标。此外,传统RAG在理解大数据集或单个大型文档的总结性语义概念时表现也较差,无法全面把握核心内容,例如,“这篇文章的中心思想是什么?”
(2)传统QFS方法:虽然LLM在总结和信息提取方面表现出色,但仍然面临上下文窗口限制的挑战。在执行QFS任务时,这种限制可能导致无法充分利用所有相关信息。当处理大规模文本时,如果上下文窗口过长,QFS还可能遇到信息“lost in middle”的问题。长文本超出模型的上下文窗口,关键的信息可能无法有效提取和整合。
GraphRAG怎么解决这些问题?
GraphRAG结合了传统RAG和QFS方法的优势,整体思路是知识社区+ MapReduce 。GraphRAG主要分为两个阶段:
(1)索引阶段(Indexing):基于原始数据生成知识图谱,为图谱划分多层级的社区,并为每个社区生成总结性摘要和描述。
(2) 查询阶段(Querying):在回答用户查询时,先利用每个社区的摘要生成局部回答,最后整合所有局部答案形成全局答案。
2. 论文细节
2.1 approach & pipeline
GraphRAG的方法流程图如下,左边为indexing的过程,右边为querying的过程。
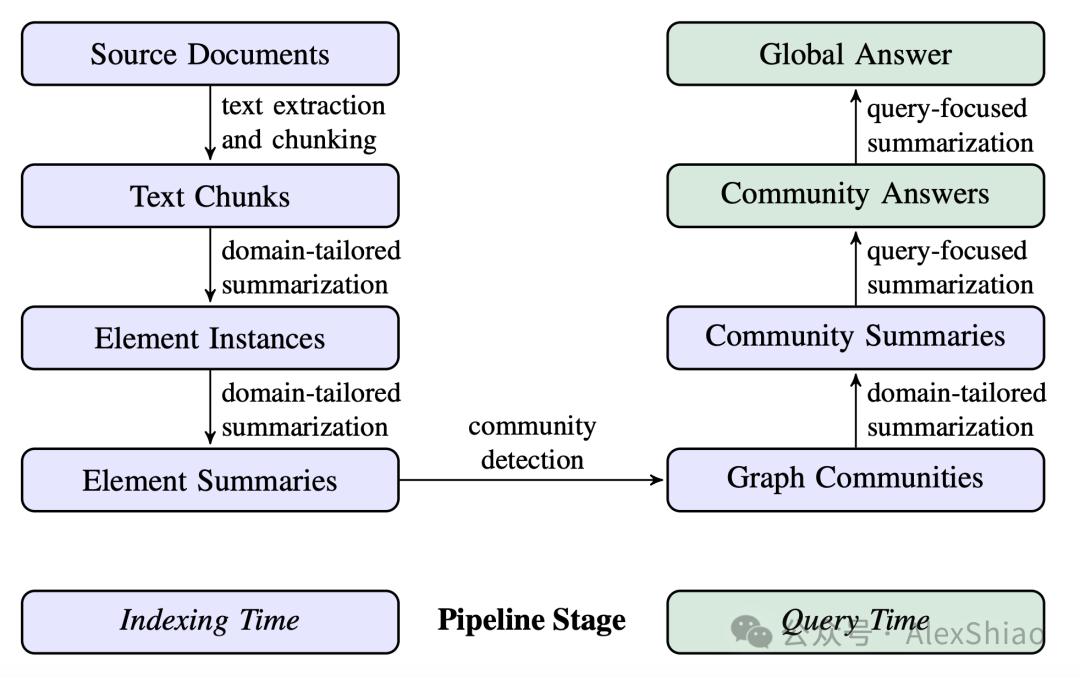
图1. GraphRAG 流程图
一步一步来看:
(1) Source Documents → Text Chunks
这一步是将原始文本切分成文本块。切分时需要考虑文本块的大小。虽然将文本切分成较大的块能够减少大模型的调用次数,但是较大的块容易导致实体识别时的召回率下降。从下图中可以看出,在单次实体抽取中,大小为600的块召回的实体数几乎是大小为2400的两倍(如图2 红框部分)。虽然理论上,文本块大一点通常效果会更好,实践中还是需要平衡准确率和召回率。论文中的块大小600。
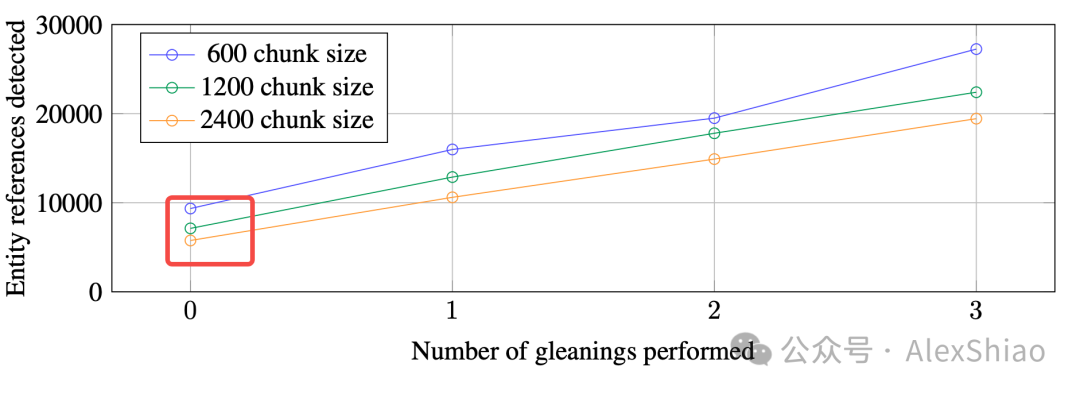
图2. 块大小与实体召回的数量
(2) Text Chunks → Element Instances
这一步从切好的文本块中提取实体和关系,抽取的内容包括名称、类型、描述等。这个抽取过程由大型模型自动完成,因此抽取的Prompt很重要,关于这里的prompt论文中提到下面几点:
-
领域定制化:基础抽取模板Prompt通常比较通用,适用于广泛的实体类别,如人名、地名和组织机构等。然而,当涉及到特定领域的知识抽取时,就需要进行领域定制化。例如,如果我想进行新能源汽车行业相关的实体抽取,关注的实体则应与技术、规格和产品等相关。这时,可以通过给Prompt提供一些few-shot示例来更好地适应文档主题。
-
多轮抽取:如前所述,较大的文本块可能会遗漏许多实体。论文中采用了多轮抽取的策略,鼓励通过多次抽取来发现更多实体。具体过程如下:大模型进行首轮抽取 --> 对抽取结果进行评分,判断是否需要继续抽取 --> 如果仍需抽取,在新一轮的Prompt中加入“MANY entities were missed in the last extraction(上一轮的抽取中漏掉了很多实体)”,以促使模型继续抽取实体,直到达到设定的阈值。
-
协变量抽取:除了以上两点,GraphRAG还支持对和实体相关的协变量进行二次抽取。默认的协变量Prompt用于提取与实体相关的声明,包括主题、对象、类型、描述、源文本跨度及开始和结束日期等信息。
(3) Element Instances → Element Summaries
上一步中用大模型来抽取原始文本的实体描述,关系描述。但这些实例可能有重复,比如,相同的实体有不同的名称或者不同的描述。这时候就需要将相似或相关的实例进行分组,然后对每个组进行总结,最终形成一个描述性的文本块,代表该组的共同特征或关系。
了解知识图谱的话,可能会有担忧:这个图谱有很多冗余和噪音。传统的知识图谱技术中在这里会有词义消歧,实体对齐等过程。但是GraphRAG没有这么做,因为后续步骤中会对实体进行社区检测,相同的或者相关的节点会被分在一个社区。另外,LLM能够理解不同名称变体背后的共同实体,只要这些变体之间有足够的连接,就能有效地缓解这些问题。所以这些冗余和噪声其实对整个框架和效果并没有什么影响。
(4) Element Summaries → Graph Communities
经过前面几步,到这里图谱算是建好了,图中的节点表示实体,实体通过关系相连,边的权重表示关系出现次数的归一化计数。GraphRAG使用Leiden社区检测算法,将图划分为多层级的社区结构。层级结构的每一层都提供了社区划分,能够全面覆盖图中的节点,并且每个节点只属于一个社区(互斥性),同时所有节点都被分配到某个社区(完全覆盖)。这种划分方式允许使用分而治之的方法进行全局摘要,从而更高效地理解和分析整个图的结构和特征。
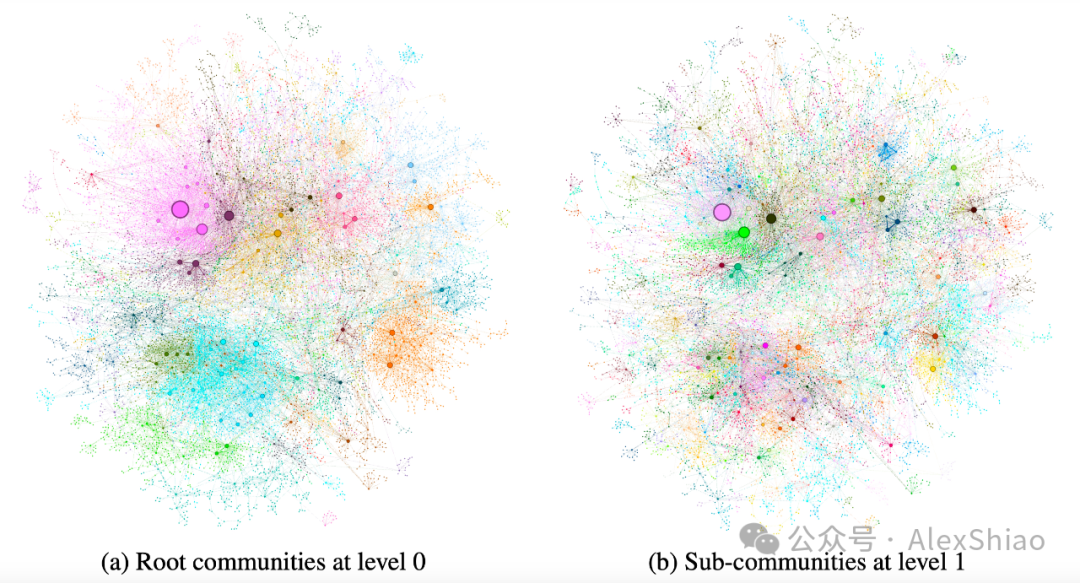
图3. 不同级别的社区图示
图(a)展示的是level0的社区,社区等级越高,模块化程度越高。b是level1社区,level0的子社区,是根社区的内部结构。
(5) Graph Communities → Community Summaries
这一步为每个Leiden层级的每个社区生成社区摘要。
-
leaf-level:针对低层次社区的元素摘要(节点、边、协变量)被优先处理,并逐步添加到大模型的上下文窗口中,直到达到Token限制。加入的优先级按社区边的源节点和目标节点的度数之和(即整体重要性)降序排列,依次添加源节点、目标节点、相关协变量及边的描述。
-
higher-level:对于更高层级的社区,如果所有元素摘要能在上下文窗口的Token限制内,就像处理叶子级社区一样处理,总结该社区的所有元素摘要。否则,根据元素摘要的Token数量对子社区进行降序排序,逐步用更短的子社区摘要替代较长的元素摘要,直到满足上下文窗口的限制。
(6) Community Summaries → Community Answers → Global Answer
当有用户查询过来的时候,用上一步生成的社区摘要来生成最终答案。生成全局答案的步骤如下:
-
准备社区摘要:社区摘要被随机打乱,按预设的token大小分成多个块。这样能保证相关信息分散在多个上下文,而不是集中在一个窗口,防止信息丢失。
-
映射(mapping)社区答案:每个块并生成用户query的答案,生成答案的同时,还生成一个对解决用户问题帮助程度的分数,分数为0的答案被过滤掉。
-
归纳(reduce)全局答案:把社区的答案进行降序排序,逐步添加到上下文中直到达到token限制。用于生成全局回答。
2.2 实验评估
(1)数据集
数据集:Podcast transcripts + News articles
由于很多问答数据集的问题主要针对于显式的事实检索,而非基于数据理解的摘要级别提问。所以论文在实验时为每个数据集生成高层次的抽象内容理解问题。这个问题生成的步骤如下:
给定数据集和数据集描述,要求大模型识别这个数据集的N个潜在用户,以及每个用户用这个数据集可以完成的N个任务。对每组(用户,任务)要求大模型生成N个需要了解整个数据集才能回答的问题。论文中N=5,因此每个数据集生成125个测试问题。
(2)评估指标
论文中评估答案的维度如下:
-
Comprehensiveness:答案提供了覆盖问题各个方面的细节程度。
-
Diversity:答案在提供不同视角和见解方面的丰富性和多样性程度。
-
Empowerment:答案是否有效帮助读者理解和做出明智判断。
-
Directness:答案具体而清晰地回答问题的程度。
(3)实验设置
论文中研究了在6种不同方法上做全局问答,让这些方法两两PK。
-
C0:用根级别的社区摘要来回答问题
-
C1:用C0的子社区摘要来回答问题,不存在时投影到C0社区。
-
C2:用C1的子社区摘要来回答问题,不存在时投影到C1社区。
-
C3:用C2的子社区摘要来回答问题,不存在时投影到C2社区。
-
SS:朴素的RAG方法,把检索到的片段直接加入到上下文窗口中,用于生成答案。
-
TS:和GraphRAG回答问题的pipeline(map-reduce的过程)一致,只是不用社区摘要回答问题,而是用原始文本来回答。
(4)实验效果
-
全局方法 VS 简单RAG方法
全局方法在各个数据集上的全面性和多样性指标上始终优于简单RAG(SS)方法。看上图的胜率。
同时直接性指标也得到了预期结果,即在所有比较中,简单RAG产生的响应是最直接的。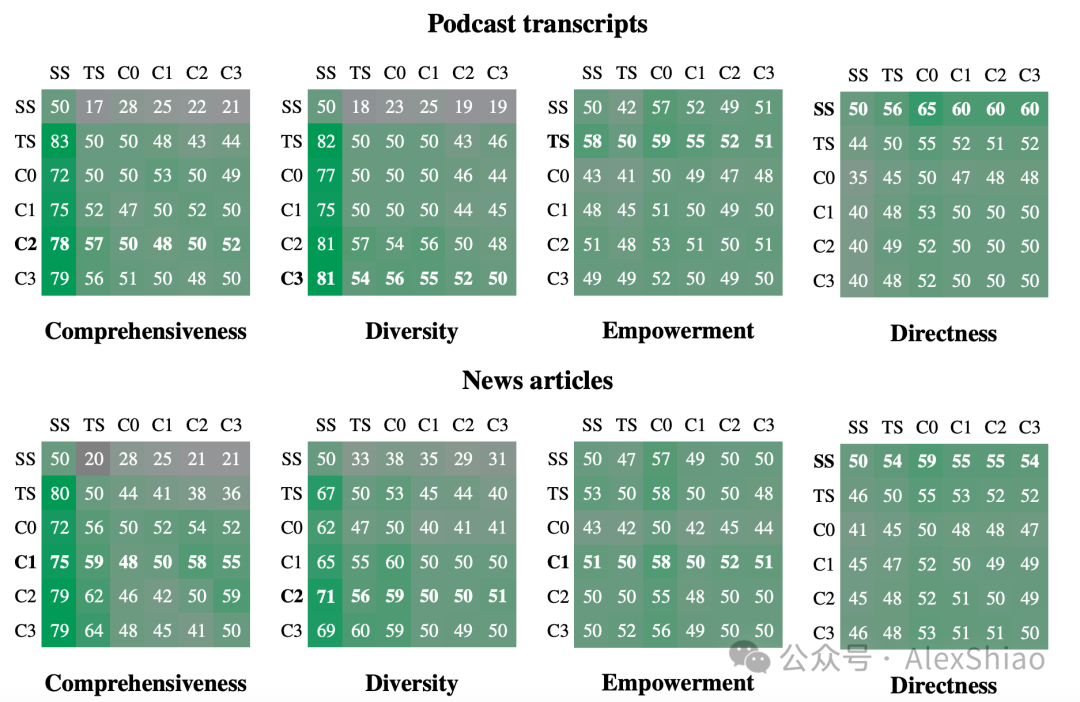
图4. 不同方法之间的PK效果
-
社区摘要和原文本比较 除了C0级摘要方法外外,其他级别社区摘要通常在全面性和多样性指标上相较用原始文本的方法(TS)有提升,虽然胜率不是特别大。另外,对于低级社区摘要(C3),GraphRAG所需的上下文Token减少了26-33%;而对于根级社区摘要(C0),所需Token减少超过97%。尽管与其他全局方法相比,性能略有下降,但是根级(C0)级的GraphRAG仍然为迭代问答提供了一种高效的解决方法,同时在全面性(72%胜率)和多样性(62%胜率)方面相较于简单RAG保持了优势。
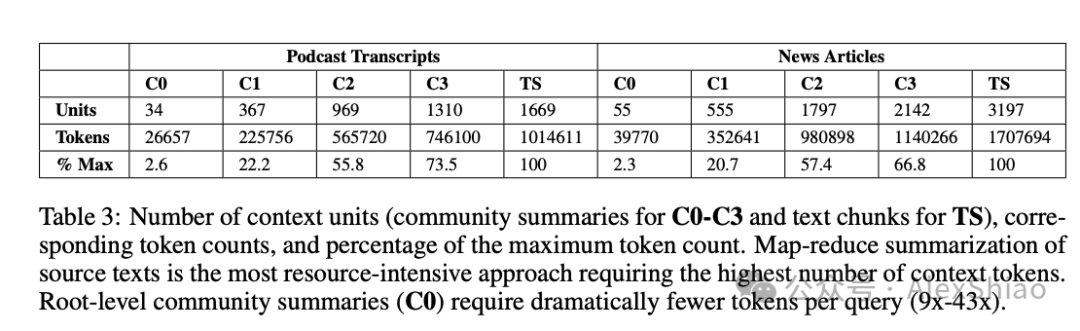
图5. 不同层级社区的Token数量对比
2.3 结论
Graph RAG结合了知识图谱、RAG和QFS方法。初步实验评估显示,GraphRAG的答案在全面性和多样性上相比于简单RAG基线有显著提升,同时和简单的map-reduce无图全局方法(TS)相比,也表现良好。在需要对同一数据集进行多个全局查询的情况下,GraphRAG的C0级摘要索引不仅优于简单RAG,还以较低的Token成本实现了与其他全局方法相当的效果。
3. 相关项目推荐
这里主要推荐两个github上的开源项目:
-
graphrag-visualizer:图谱可视化,数据的可视化。
🔗:https://noworneverev.github.io/graphrag-visualizer/
-
GraphRAG-Local-UI:做了整个GraphRAG的操作界面,包括文档上传,模型选择(包括本地模型),图谱展示,问答界面,Prompt-tuning。
🔗:https://github.com/severian42/GraphRAG-Local-UI

















 1866
1866



 到【灌水乐园】发言
到【灌水乐园】发言








