




论文链接:https://arxiv.org/pdf/2105.02358.pdf
Motivation
self-attention在各种视觉任务中大放异彩,相比于卷积这类局部感知的操作,self-attention可以获取更多的long-range dependency,从而学习到融合了全局特征的feature。但是self-attention自身存在两个缺点:(1)计算量太大,计算复杂度与pixel的平方相关;(2)没有考虑不同样本之间的潜在关联,只是单独处理每一个样本,在单个样本内去捕获这类long-range dependency。
针对这两个问题,作者提出了一个external attention模块,仅仅通过两个可学习的external unit,就可以简化self-attention的时间复杂度,简化到与pixel数量线性相关;同时由于两个unit是external的,对于整个数据集来说都是shared,所以还可以隐式地考虑到不同样本之间的关联。两个unit在实现的时候是两个linear layer,因此可以直接end2end优化。
Related Work
这部分写了两三年来最经典的一些视觉attention,self-attention,transformer相关的研究进展,墙裂推荐看一下。
Method
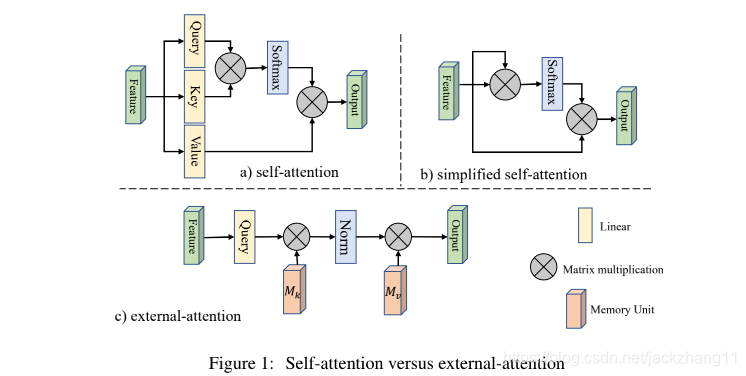
上图中(a)和(b)分别表示经典的self-attention和简化版self-attention,计算复杂度均为O(dN2)O(dN^{2})O(dN
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5620
5620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









