




在做图像语义分割的时候,编码器通过卷积层得到图像的一些特征,但是解码器需要该特征还原到原图像的尺寸大小,才可以对原图像的每个像素点进行分类。从一个较小尺寸的矩阵进行变换,得到较大尺寸的矩阵,在这个过程就是上采样。
常见的上采样的方法有(1)插值法(最邻近插值、双线性插值等) (2)转置卷积(又称为反卷积) (3)上采样(unsampling)(4)上池化(unpooling)
插值法
插值法不需要学习任何的参数,只是根据已知的像素点对未知的点进行预测估计,从而可以扩大图像的尺寸,达到上采样的效果。常见的插值方法可以参考这篇文章:https://blog.youkuaiyun.com/stf1065716904/article/details/78450997
转置卷积
与插值法不同,转置卷积需要学习一些参数。我们知道卷积操作如果不加padding会使图像尺寸缩小;相反地,转置卷积(反卷积)会让图像的尺寸增大。这篇文章介绍转置卷积非常详细:https://blog.youkuaiyun.com/LoseInVain/article/details/81098502
这里对该文章做一下简单的概括。假如我们对一个 4∗44*44∗4 的原图像矩阵,用 3∗33*33∗3 的卷积核做 stride为1、padding为 0 的卷积,则会得到一个 2∗22*22∗2 的特征图矩阵。该卷积的过程可以等价为矩阵的乘法:在上述卷积中, 3∗33*33∗3 的卷积核可以转化为 4∗164*164∗16 的卷积矩阵, 4∗44*44∗4 的原图像转化为 16∗116*116∗1 的向量,两者进行矩阵乘法可得到 4∗14*14∗1 的向量,最后resize为 2∗22*22∗2 的特征图矩阵。
所以重点来了,拥有一个 4∗164*164∗16 的卷积矩阵,可将 4∗44*44∗4 的图像变为 2∗22*22∗2;那么,如果拥有一个 16∗416*416∗4 的矩阵,可将 2∗22*22∗2 的矩阵变为 4∗44*44∗4。
假如现在的图像尺寸是 2∗22*22∗2,要将其恢复到 4∗44*44∗4。首先将其转化为 4∗14*14∗1,再与卷积矩阵的转置矩阵 16∗416*416∗4做乘法,可以得到 16∗116*116∗1 的向量,最后resize为 4∗44*44∗4 的图像矩阵。
转置卷积的矩阵并不是正向卷积矩阵直接转置得到,而只是维度上与正向卷积矩阵构成了转置关系。转置卷积也不是标准意义上的卷积,但可以当作卷积来使用。在实践中,可以先将原始矩阵做上池化(即在中间部分填0),再做正向卷积,这样的效果和转置卷积是相同的。
unsampling
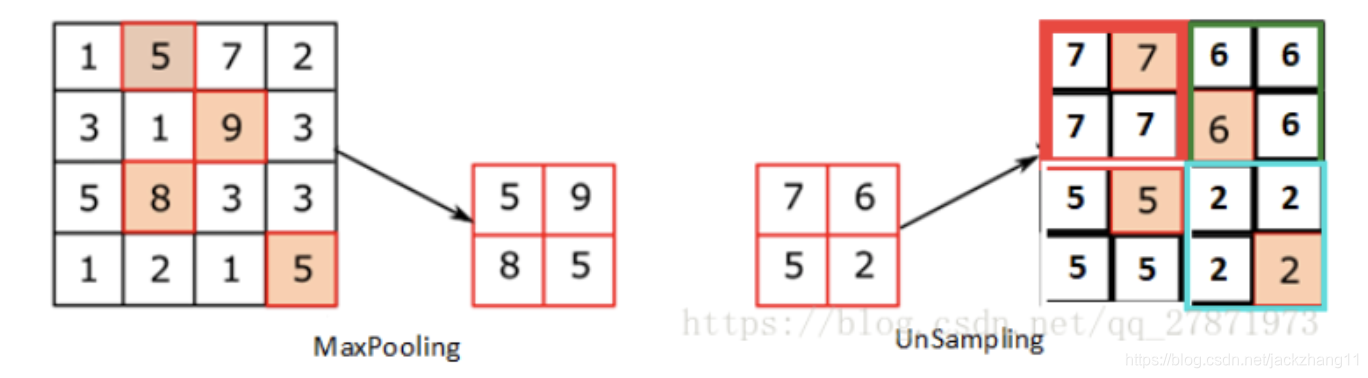
unsampling 就是在直接将特征图的元素进行复制,以扩充feature map
unpooling
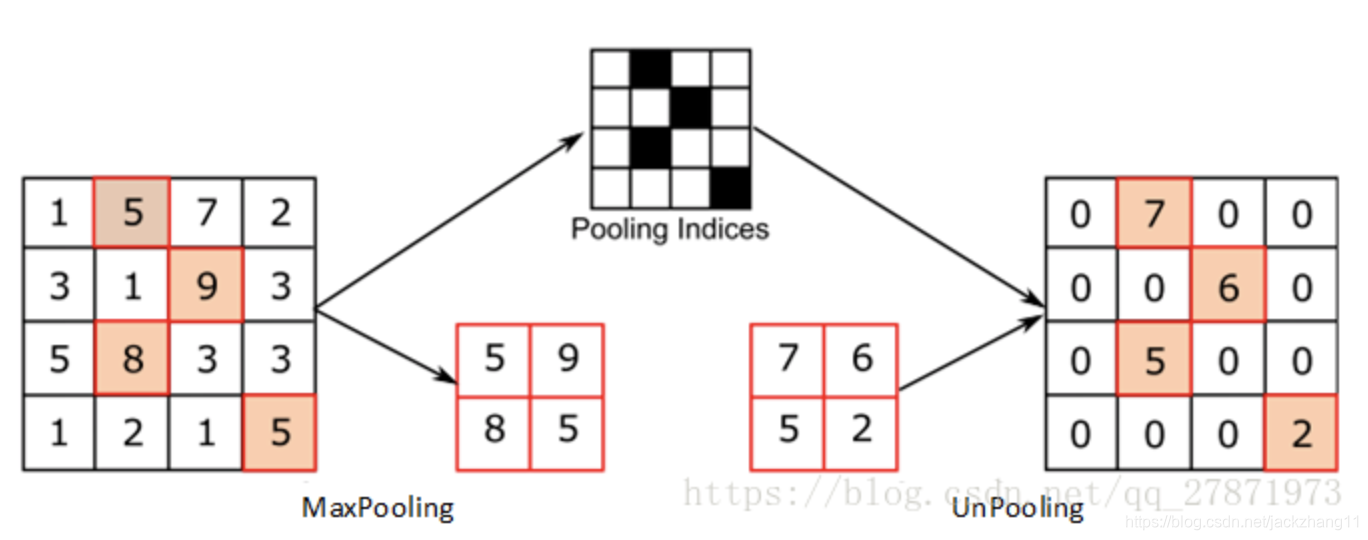
unpooling 与 unsampling 类似,只是变为用 0 元素对特征图进行填充

















 2875
2875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









