




摘要
注意机制,尤其是自我注意,在视觉任务的深度特征表示中发挥了越来越重要的作用。自注意力通过使用所有位置的成对亲和力计算特征的加权和来更新每个位置的特征,以捕获单个样本中的长期依赖关系。然而,self-attention 具有二次复杂度,并且忽略了不同样本之间的潜在相关性。本文提出了一种新的注意力机制,我们称之为外部注意力,它基于两个外部的、小的、可学习的、共享的内存,只需使用两个级联的线性层和两个归一化层就可以轻松实现;它方便地取代了现有流行架构中的 self-attention。外部注意力具有线性复杂性,并隐含考虑所有数据样本之间的相关性。我们进一步将多头机制纳入外部注意,以提供用于图像分类的全 MLP 架构,外部注意 MLP (EAMLP)。在图像分类、对象检测、语义分割、实例分割、图像生成和点云分析方面的大量实验表明,我们的方法提供的结果与自我注意机制及其一些变体相当或更好,而且计算和内存成本要低得多.
1.引言
由于self-attention 机制有助于提高在各种自然语言处理 [1]、[2] 和计算机视觉 [3]、[4] 任务中捕获远程依赖关系的能力。自注意力通过聚合单个样本中所有其他位置的特征来细化每个位置的表示,这导致样本中位置数量的二次计算复杂度。因此,一些变体试图以较低的计算成本来逼近 self-attention [5]、[6]、[7]、[8]。
此外,自注意力集中在单个样本内不同位置之间的自亲和性上,而忽略了与其他样本的潜在相关性。很容易看出,合并不同样本之间的相关性有助于更好地表示特征。例如,属于同一类别但分布在不同样本中的特征应该在语义分割任务中得到一致的处理,类似的观察适用于图像分类和其他各种视觉任务。
本文提出了一种新的轻量级注意力机制,我们称之为外部注意力(见图 1c))。如图 1a) 所示,计算自注意力需要首先通过计算自查询向量和自键向量之间的亲和度来计算注意力图,然后通过使用该注意力图对自值向量进行加权来生成新的特征图。外部注意力的作用不同。我们首先通过计算自查询向量和外部可学习键存储器之间的亲和力来计算注意力图,然后通过将此注意力图乘以另一个外部可学习值记忆产生一个定义的特征图。
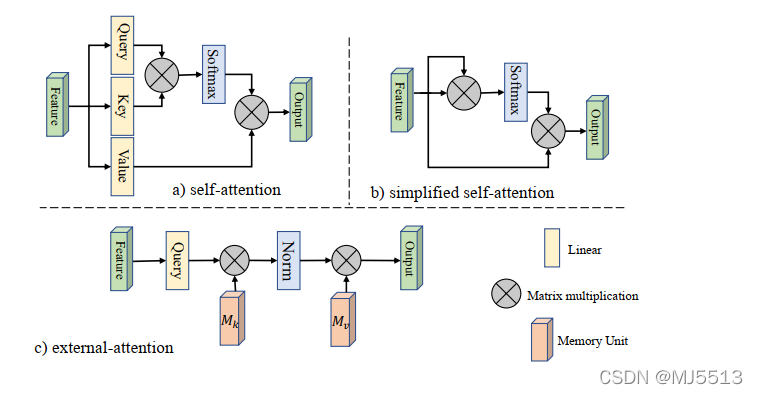
图1.自我关注与外部关注
实际上,这两个存储器是用线性层实现的,因此可以通过端到端的反向传播来优化。它们独立于单个样本,在整个数据集中共享,起到很强的正则化作用,提高了注意力机制的泛化能力。外部注意力轻量级的关键在于内存中的元素数量远小于输入特征中的数量,从而产生与输入元素数量成线性关系的计算复杂度。外部存储器旨在学习整个数据集中最具辨别力的特征,捕获信息量最大的部分,并排除来自其他样本的干扰信息。在稀疏编码 [9] 或字典学习 [10] 中可以找到类似的想法。然而,与那些方法不同的是,我们既不尝试重建输入特征,也不对注意力图应用任何显式稀疏正则化。
尽管提出的外部注意方法很简单,但它对各种视觉任务都很有效。由于其简单性,它可以很容易地整合到现有流行的基于自我注意的架构中,例如 DANet [4]、SAGAN [11] 和 T2T-Transformer [12]。图 3 展示了一个典型的架构,用我们的外部注意力代替自我注意力来完成图像语义分割任务。我们在分类、对象检测、语义分割、实例分割和生成等基本视觉任务上进行了广泛的实验,具有不同的输入模式(图像和点云)。结果表明,我们的方法取得了与原始的自我注意机制及其一些变体,计算成本要低得多。
为了学习相同输入的不同方面,我们将多头机构结合到外部注意力以提升其能力。得益于提出的多头外部关注,我们设计了一种新颖的全MLP结构EAMLP,它可以与CNN和原始Transformers相媲美,用于图像分类任务。
本文的主要贡献概括如下:
- 一种新的注意机制--外部注意,其复杂性为O(N);它可以取代现有体系结构中的自我注意。它可以在整个数据集中挖掘潜在的关系,具有很强的规则化作用,并提高了注意机制的泛化能力。
- 多头外部关注,这有利于我们构建一个全MLP架构;在ImageNet-1K数据集上实现了79.4%的TOP1准确率。
- 利用外部注意力进行图像分类、对象检测、语义分割、实例分割、图像生成、点云分类和点云分割的大量实验。在必须保持较低计算工作量的情况下,它比原始的自我注意机制及其一些变体获得了更好的结果。
2.相关工作
由于对注意机制的全面回顾超出了本文的范围,我们只讨论视觉领域中最密切相关的文献。
2.1 视觉任务中的注意机制
注意机制可以被视为一种根据激活的重要性重新分配资源的机制。它在人类视觉系统中扮演着重要的角色。在过去十年中,这一领域得到了蓬勃发展[3]、[13]、[14]、[15]、[16]、[17]、[18]。Hu等人提出了SENET[15],证明了注意力机制可以减少噪声,提高分类性能。随后,许多其他论文将其应用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 697
697




 到【灌水乐园】发言
到【灌水乐园】发言







