







 本文探讨了Self-Attention的高计算复杂度问题及忽略样本间联系的不足,提出了External Attention(EA)。通过使用两个串联MLP作为memory units,EA将计算复杂度降至O(n),并利用全训练数据学习,考虑了样本间联系,实现了多头外部注意力机制。
本文探讨了Self-Attention的高计算复杂度问题及忽略样本间联系的不足,提出了External Attention(EA)。通过使用两个串联MLP作为memory units,EA将计算复杂度降至O(n),并利用全训练数据学习,考虑了样本间联系,实现了多头外部注意力机制。
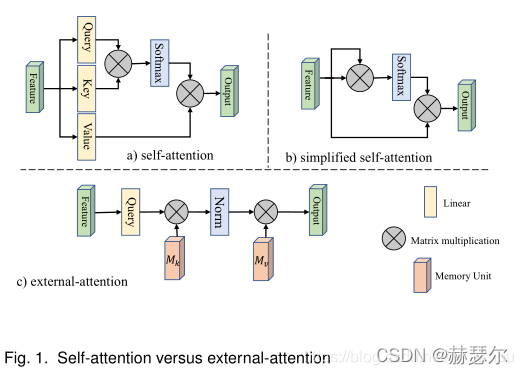
External Attention(EA)详解
要解决的Self-Attention(SA)的两个痛点问题:
(1)O(n^2)的计算复杂度;
(2)SA是在同一个样本上根据不同位置计算Attention,忽略了不同样本之间的联系。
因此,本文采用了两个串联的MLP结构作为memory units,使得计算复杂度降低到了O(n);
此外,这两个memory units是基于全部的训练数据学习的,因此也隐式的考虑了不同样本之间的联系。
from model.aExternal Attention(EA)详解
要解决的Self-Attention(SA)的两个痛点问题:
(1)O(n^2)的计算复杂度;
(2)SA是在同一个样本上根据不同位置计算Attention,忽略了不同样本之间的联系。
因此,本文采用了两个串联的MLP结构作为memory units,使得计算复杂度降低到了O(n);
此外,这两个memory units是基于全部的训练数据学习的,因此也隐式的考虑了不同样本之间的联系。
from model.a
 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























