




 本文详细介绍了深度学习中前向传播和反向传播的算法,包括网络结构定义、前向传播计算预测值、反向传播计算梯度,以及梯度下降算法的使用。通过具体的例子和计算图展示了反向传播的过程,并将其向量化为代码形式,为神经网络的训练提供了理论基础。
本文详细介绍了深度学习中前向传播和反向传播的算法,包括网络结构定义、前向传播计算预测值、反向传播计算梯度,以及梯度下降算法的使用。通过具体的例子和计算图展示了反向传播的过程,并将其向量化为代码形式,为神经网络的训练提供了理论基础。
1 定义网络结构
假设某二分类问题的网络结构由如图1.1组成(暂仅以2层网络举例,更高层数可依此类比),其输入的特征向量维数为n,隐藏层神经元个数为 ,输出层神经元个数为
(由于是二分类问题,故仅含一个)。
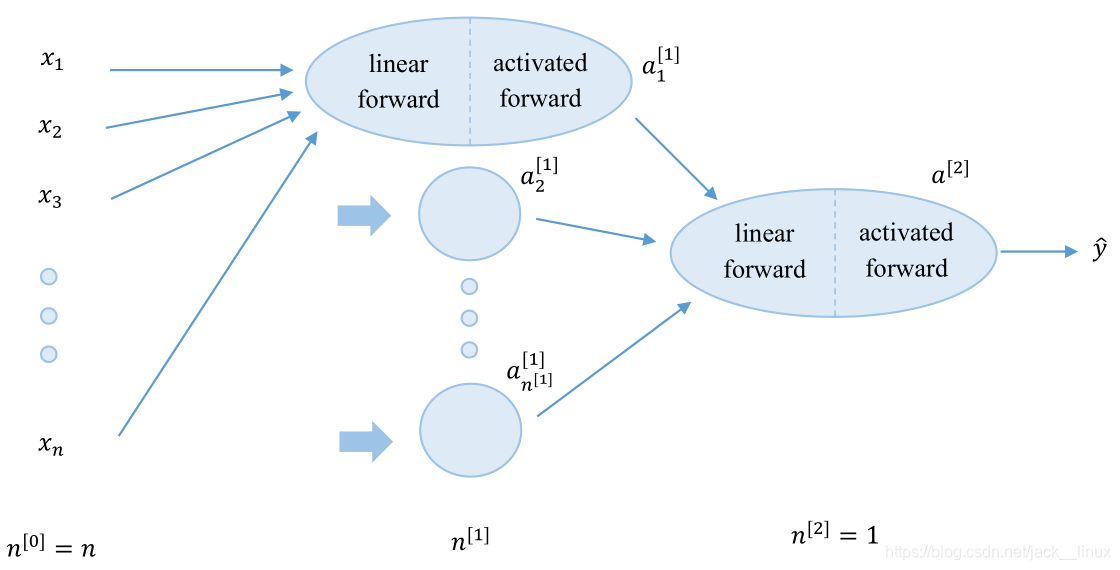
其训练过程为:首先获取训练数据 X ,初始化每层的训练参数 w、b ,并通过前向传播算法(包含线性前向传播和激活函数前向传播)得到 并计算
,然后通过反向传播算法(包含线性反向传播和激活函数反向传播)计算每层的 dw 和 db,最终通过梯度下降算法更新参数 w、b,并多次迭代该过程,得到训练参数。
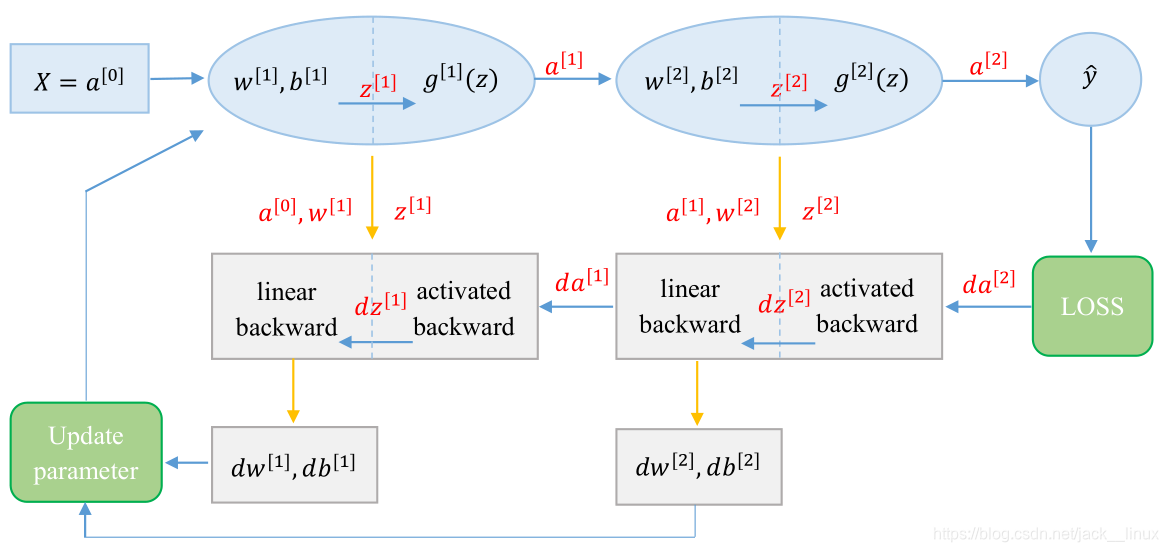
其中参数为:
类比可知 维数为
,
维数为
。
X 包含 m 个样本的 个特征值,
包含网络第1层的所有权重参数,
包含网络第1层的所有偏置参数。
2 前向传播算法
输入数据 X ,然后通过每层的权重 w 和偏置 b 计算得到输出预测值 ,并最终通过代价函数衡量算法的运行情况。
注:上式中 需要先广播(python中的一种运算机制)至
再参与运算。
,此处激活函数
选择 Relu 函数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 875
875






 到【灌水乐园】发言
到【灌水乐园】发言







