






时间序列预测问题由来已久,毕竟预测未来是人类永恒的需求。
上世纪以来发展了众多时间序列预测模型,典型的有 ARMA, GARCH, ETS, SSM 等线性模型,在工程控制、金融等领域应用广泛。
预测说白了就是用历史数据预测未来值,即自回归。上述列举的传统方法主要考虑目标值 yty_tyt 和 历史值{yt−1,yt−2,…,yt−p,…}\{y_{t-1}, y_{t-2}, \ldots, y_{t-p}, \ldots\}{yt−1,yt−2,…,yt−p,…} 之间存在线性关系,局限性很强。
当考虑非线性自回归模型(NAR)时,假设
yt=f(yt−1,…,yt−p)
y_t = f(y_{t-1}, \ldots, y_{t-p})
yt=f(yt−1,…,yt−p)
此时机器学习中的各种回归方法都可以拿来试试,譬如:LR, SVR, CART, GBDT, XGBOOST, GP, ANN, RNN, LSTM, …
模型多如牛毛,哪个才是最强?并无定论。
既然把时间序列预测当做监督学习问题,就要求数据满足如下假设:

对时间序列的自回归模型而言,输入输出分布 P(X,Y)=P(yt,yt−1,…,yt−p)P(X, Y) = P(y_t, y_{t-1}, \ldots, y_{t-p})P(X,Y)=P(yt,yt−1,…,yt−p),即序列片段在整个序列中的分布。
要满足独立同分布假设,测试的时间片段应该在训练集中“出现过”,至少应该可以找到相似的片段,这意味着什么呢?
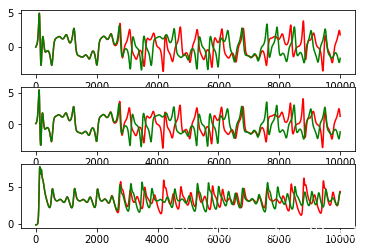
比如说上图中的混沌时间序列,由于混沌系统具有遍历性,序列的任意一个片段可以在历史中找到相似的片段。另一方面,由于混沌系统具有初值敏感性与非周期性,测试集中的片段绝对不会和训练集中的片段完全重合。所以混沌时间序列作为机器学习模型的数据集再合适不过了。
独立同分布假设实际上对时间序列做了很强的要求,首先序列必须是有界的,如果训练集中的数据分布在 1 到 2 之间, 测试的数据分布在 3 到 4 之间,很大概率会预测不好。
但我们常见的序列一般都是有趋势的,比如持续上涨、下跌,这些单调的序列不就不能用机器学习模型了?确实如此,对于这些具有趋势的序列,应该先做趋势分解,剩下的有界部分就可以使用(非线性)自回归模型了。


















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











