






 本文分享了使用Pandas库高效读取CSV文件的方法,通过设置index_col和parse_dates参数,将索引列设为'No',并解析日期时间列,避免了默认索引的重复,提升了数据处理的效率。
本文分享了使用Pandas库高效读取CSV文件的方法,通过设置index_col和parse_dates参数,将索引列设为'No',并解析日期时间列,避免了默认索引的重复,提升了数据处理的效率。
发现了一个 pandas 读取 csv 的高级用法,下面直接读取一个 csv 文件:
path = 'PRSA_data_2010.1.1-2014.12.31.csv'
data = pd.read_csv(path)
data.head()
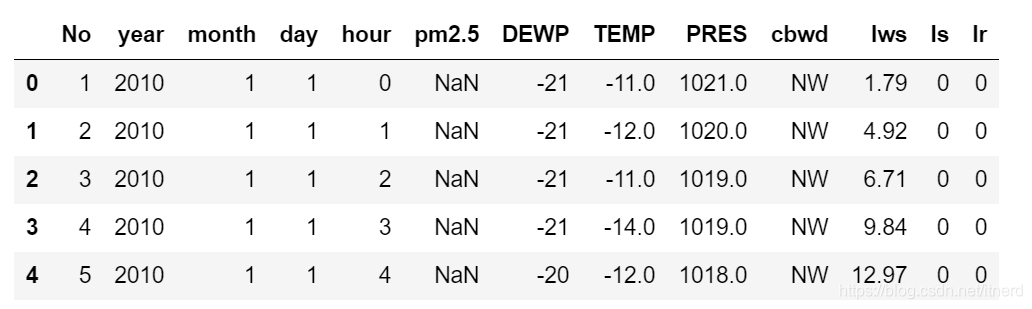
数据的年月日时是在不同列的,而且数据自带了第一列索引,和 pandas 的默认索引重复了。
下面改用高级读法:
df = pd.read_csv(path, index_col='No',
parse_dates={'datetime': [1,2,3,4]},
date_parser=lambda x: pd.datetime.strptime(x, '%Y %m %d %H')
)
df.head()
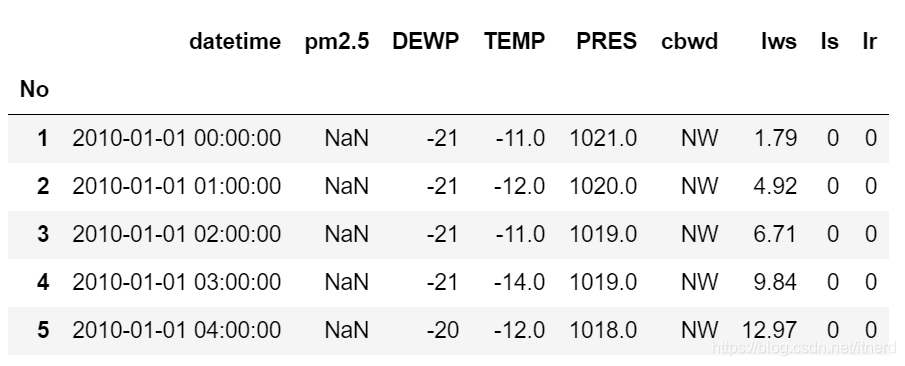
是不是舒服多了!


















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











