 优化Pandas数据筛选效率
优化Pandas数据筛选效率





 本文探讨了在处理ConceptNet5中文数据集时,如何利用Pandas库进行高效的数据筛选。通过对比不同方法的执行时间,发现直接使用布尔运算比apply方法更高效,并进一步优化了代码,将速度提升了数倍。
本文探讨了在处理ConceptNet5中文数据集时,如何利用Pandas库进行高效的数据筛选。通过对比不同方法的执行时间,发现直接使用布尔运算比apply方法更高效,并进一步优化了代码,将速度提升了数倍。
这里选取的数据集为 conceptNet5 的中文数据集
data = pd.read_csv(FILE, delimiter='\t')
data.columns = ['uri', 'relation', 'start', 'end', 'json']
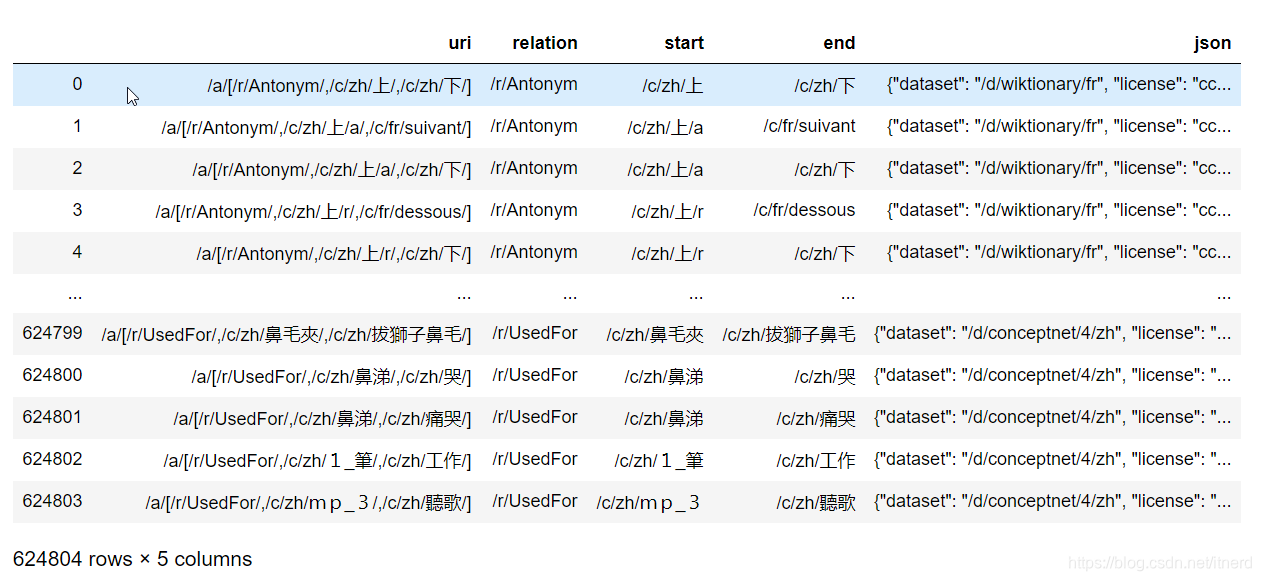
使用布尔运算
使用计时器参见:【python 代码计时】
with Timer() as t:
data[data['start'].str.contains('zh') & data['end'].str.contains('zh')]
'''
[time spent: 0.57s]
'''
这个速度还比较快了
使用 apply 方法
with Timer() as t:
data[data.apply(lambda row: 'zh' in row['start'] and 'zh' in row['end'],axis=1)]
'''
[time spent: 9.03s]
'''
apply 是逐行遍历,看来没有做并行优化,
然鹅!上面的代码是有问题的!是可以优化的!
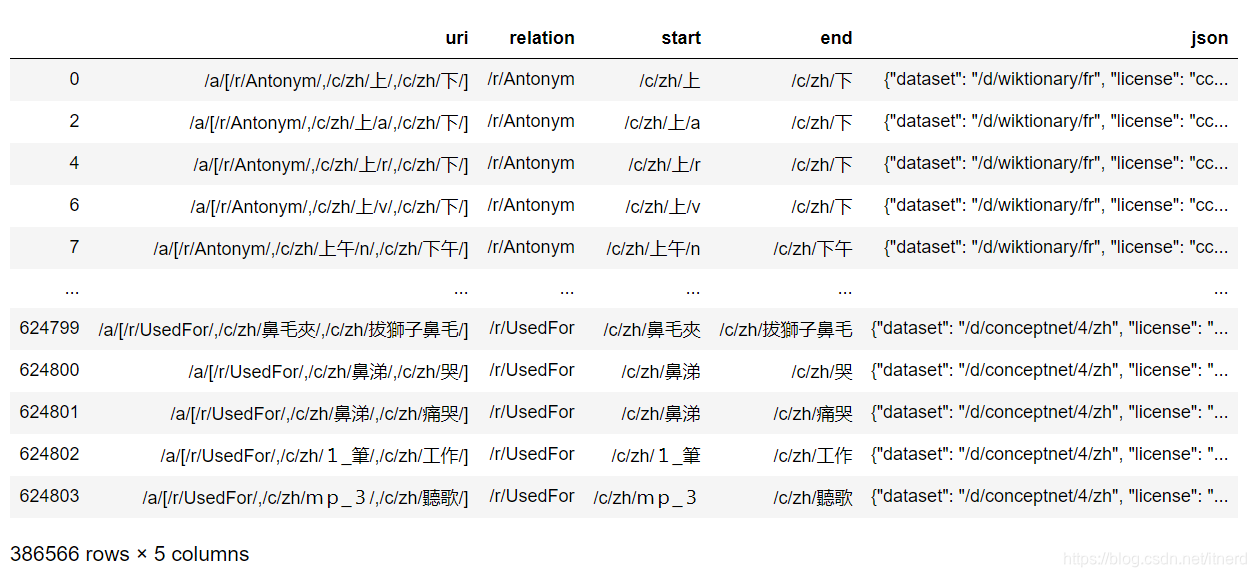
最大的问题就是上面的代码把不相关的列也牵扯了进来,正确的写法应该是:
with Timer() as t:
data[data['start'].apply(lambda row: row.find('zh')>0) & data['end'].apply(lambda row: row.find('zh')>0)]
'''
[time spent: 0.33s]
'''
速度提升令人震惊!


















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











