







SVD-矩阵分解
在很多情况下,数据中的一小段携带了数据集中的大部分信息,其他信息则要么是噪声,要么就是毫不相关的信息。在线性代数中还有很多矩阵分解技术。最常见的一种矩阵分解技术就是SVD。SVD将原始的数据集矩阵Data分解成三个矩阵U、和
,如果原始矩阵Data是m行n列,那么U、
和
就分别是m行m列、m行n列和n行n列。
矩阵只有对角元素,其他元素均为0。这些对角元素称为奇异值,他们对应了原始数据集Data的奇异值。
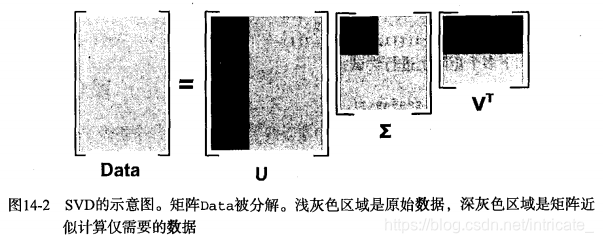
如何确定保留前几个奇异值呢?确定要保留的奇异值的数目有很多启发式的策略,其中一个典型的做法就是保留矩阵中90%的能量信息,总能量信息=所有的奇异值求平方和。下面介绍SVD的一个经典应用。
基于协同过滤的推荐引擎
这里以向用户推荐相似的物品为例,我们需要计算的是物品之间的相似度(因为物品的维度小于用户数)。
计算相似度可以使用以下这几种方法:1.欧式距离 2.皮尔逊相关系数 3.余弦相似度
那么如何对推荐引擎进行评价呢?
我们可以采用前面多次使用的交叉测试的方法,具体的做法就是,将某些已知的评分值去掉,然后对它们进行预测,最后计算预测值和真实值之间的差异。
因为实际数据都是稀疏的,所以使用SVD可以得更好的效果。具体案例见Python代码
基于SVD的图像压缩
对于一些图像,我们可以使用SVD来进行压缩,减少存储所需的空间。例子中介绍了对32×32的手写图像进行压缩,使用了SVD后,只需要两个奇异值,和原来32×32=1024相比,只需要64+64+2=130个数字即可,获得了近乎10倍的压缩比。
Python代码如下:
from numpy import *
from numpy import linalg as la
def loadExData(): # (m,n)
return[[0, 0, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]]
# 测试svd算法
# Data = loadExData()
# U,sigma,VT = la.svd(Data) # numpy的linalg库中有svd函数用于奇异值分解
# print("U:\n", U) # (m,m)
# print("sigma:\n", sigma) # 对角阵,(m,n),但是numpy为了压缩空间存储,只会看到对角线上的数值,即显示一个(1,n)的矢量
# print("VT:\n", VT) # (n,n)
# # 观察到sigma的值,发现前2个比较大,故可以将5维降成2维
# # Data(m,n) = U(m,2) * Σ(2,2) * V^(T)(2,n)
# Sig2 = mat([[sigma[0],0], [0,sigma[1]]]) # 构造Σ(2,2)
# newData = U[:,:2] * Sig2 * VT[:2,:]
# print("newData:\n", newData)
def loadExData2(): # 行代表用户,列代表物品
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 欧氏距离
# inA, inB必须是列向量,否则会计算错误
def ecludSim(inA,inB):
return 1.0/(1.0 + la.norm(inA - inB)) # linalg.norm() 用于计算范式 ||A-B||
# 皮尔逊相关系数
def pearsSim(inA,inB):
if len(inA) < 3 : return 1.0 # 如果向量不存在3个或更多的点,该函数返回1,表示两个向量完全相关
return 0.5+0.5*corrcoef(inA, inB, rowvar=0)[0][1] # [-1,1] 归一化 [0,1]
# 余弦相似度
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom) # [-1,1] 归一化 [0,1]
# 基于物品相似度的推荐引擎
'''
计算某一用户对未打分项物品的评分
@param dataMat:数据矩阵 (user, item)
@param user:用户编号
@param simMeas:相似度计算方法
@param item:未打分项物品编号
'''
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1] # 多少个物品
simTotal = 0.0; # 总相似度
ratSimTotal = 0.0 # 总的评分(相似度和当前用户评分的乘积)
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0: continue # 如果用户没有对某物品评分,则跳过该物品
overLap = nonzero(logical_and(dataMat[:,item].A>0, \
dataMat[:,j].A>0))[0] # 找到所有用户对这两种物品都打过分的项的索引
if len(overLap) == 0: similarity = 0 # 如果没有找到对两种物品都打过分的项,则相似度为0
else: similarity = simMeas(dataMat[overLap,item], \
dataMat[overLap,j]) # 否则,计算两种物品打过分的项的相似度
print('the %d and %d similarity is: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal # 将评分值映射到[1,5]之间,返回该未打分项物品的评分
# 使用svd的评分估计,参数解释同standEst
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) # 前4个奇异值包含总能量的90%,故将矩阵降维成4维
xformedItems = dataMat.T * U[:,:4] * Sig4.I # 利用U矩阵将物品转换到低维空间中,即降成4维
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue # 加不加 j==item 无所谓,因为item本来就是未评分的物品
similarity = simMeas(xformedItems[item,:].T,\
xformedItems[j,:].T) # 相似度的计算是在低维(4维)空间进行的,注意这里必须是列向量
print('the %d and %d similarity is: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal
'''
对该用户每一个未评分的物品计算评分,进行排序,产生推荐
@param dataMat:数据矩阵 (user, item)
@param user:用户编号
@param simMeas:相似度计算方法,默认余弦相似度计算方法
@param estMethod:评分估计的方法,默认不使用svd矩阵分解
'''
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
unratedItems = nonzero(dataMat[user,:].A==0)[1] # 返回该用户未打过分的物品的索引(列的索引)
if len(unratedItems) == 0: return 'you rated everything' # 如果不存在该用户未打过分的物品,则直接退出
itemScores = []
for item in unratedItems: # 对于每一个未打过分的物品
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore)) # (未打分的物品, 该物品预测的评分)
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N] # 按照物品评分(jj[1])从大到小排序
dataMat = mat([[4,4,0,2,2],[4,0,0,3,3],[4,0,0,1,1],[1,1,1,2,0],[2,2,2,0,0],[1,1,1,0,0],[5,5,5,0,0]])
print("cosSim:\n", recommend(dataMat,2)) # 用户2代表矩阵的第3行
'''
结果:
the 1 and 0 similarity is: 1.000000
the 1 and 3 similarity is: 0.928746
the 1 and 4 similarity is: 1.000000
the 2 and 0 similarity is: 1.000000
the 2 and 3 similarity is: 1.000000
the 2 and 4 similarity is: 0.000000
[(2, 2.5), (1, 2.0243290220056256)]
用户2对物品2的打分值为2.5(第2列),对物品1(第2列)
'''
print("ecludSim:\n", recommend(dataMat,2,simMeas=ecludSim)) # 欧氏距离,[(2, 3.0), (1, 2.8266504712098603)]
print("pearsSim:\n", recommend(dataMat,2,simMeas=pearsSim)) # 皮尔逊相关系数,[(2, 2.5), (1, 2.0)]
# 测试带svd的评分估计
print()
dataMat2 = mat(loadExData2())
print("svdEst + pearsSim:\n", recommend(dataMat2,2,100,simMeas=pearsSim,estMethod=svdEst)) # 皮尔逊相关系数
# 基于SVD的图像压缩
def printMat(inMat, thresh=0.8):
for i in range(32):
for k in range(32):
if float(inMat[i,k]) > thresh:
print(1,end='') # end默认是'\n',所以如果不换行,将end设置为''或' '
else: print(0,end='')
print()
# @param numSV:奇异值数目,默认为3
def imgCompress(numSV=3, thresh=0.8):
myl = []
for line in open('0_5.txt').readlines():
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat = mat(myl)
print("****original matrix******")
printMat(myMat, thresh)
U,Sigma,VT = la.svd(myMat)
SigRecon = mat(zeros((numSV, numSV)))
for k in range(numSV): # 构造对角阵,保留前numSV个奇异值
SigRecon[k,k] = Sigma[k]
reconMat = U[:,:numSV] * SigRecon * VT[:numSV,:] # 重构后的矩阵 (m,n)
print("****reconstructed matrix using %d singular values******" % numSV)
printMat(reconMat, thresh)
print("\n基于SVD的图像压缩:")
imgCompress(2) # 发现只需要保留两个奇异值,就可以得到近似的压缩图像

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









