




文章目录
R语言|临床预测模型(一)
本部分主要是基于丁香园《临床预测模型构建&机器学习(R语言进阶)》课程和《R语言临床预测模型实战》的笔记总结,所有内容均基于 R 语言实现,主要内容为构建临床预测模型,即基于已知参数通过回归建模分析或其他非参数化的方法如机器学习来计算未知结果发生的可能性,同时还包括模型效能评价与验证等。
临床预测模型包括诊断模型和预后模型:
- 诊断模型:基于研究对象的症状和体征及其他临床资料,判断研究对象是否患某种疾病或处于某种状态。
- 预后模型:基于某种疾病或状态,估计研究对象未来死亡、复发某种疾病或其他伤残事件出现的风险。
概述
1. 主要的建模方式
- 参数化方法:线性模型、广义线性模型、logistic 回归…
- 半参数化方法:竞争风险模型、cox 回归…
- 非参数化方法(没有回归系统,没有参数但可预测):机器学习(神经网络、随机森林、决策树…)
2. 预测模型的呈现形式
通常参数化或半参数化方法可以转化为如下形式,但机器学习方法较难转化为如下形式,在可解释性上存在一定问题。
-
列线图 Nomogram
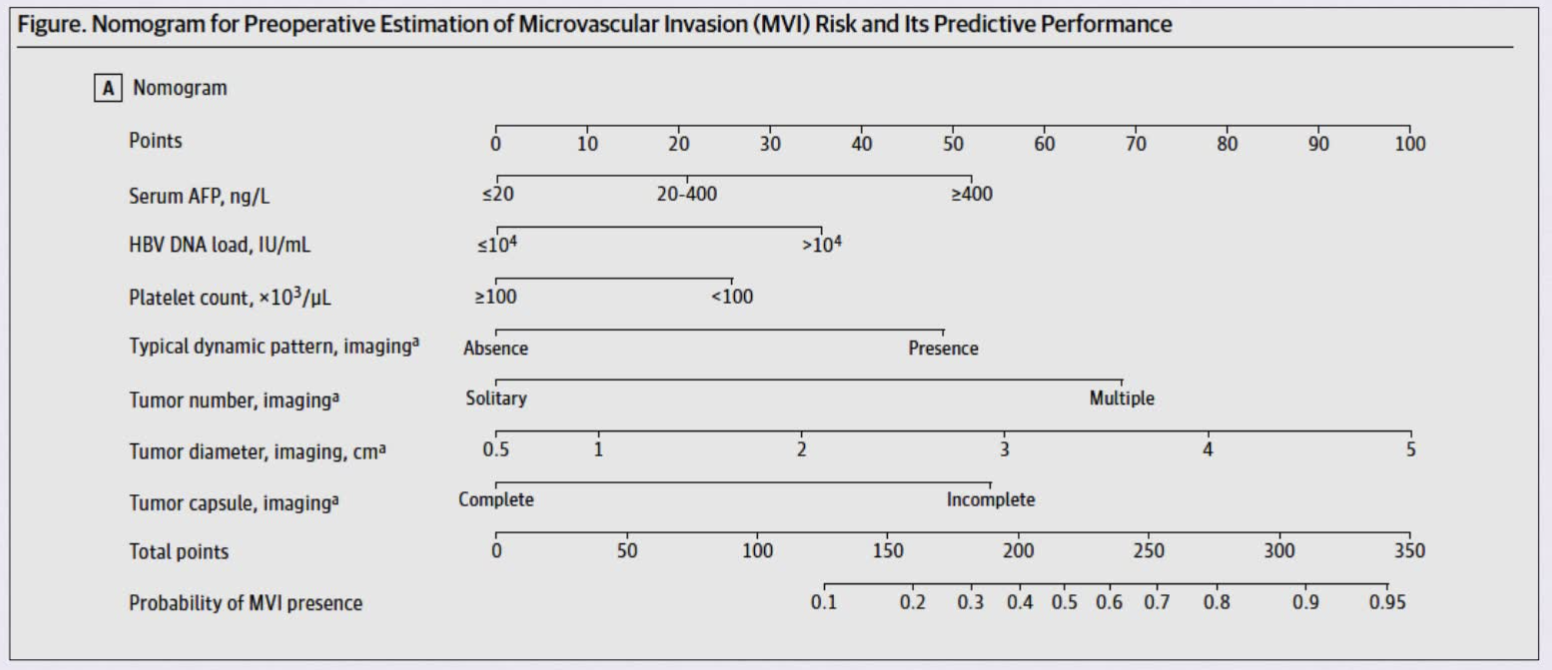
-
网页计算器
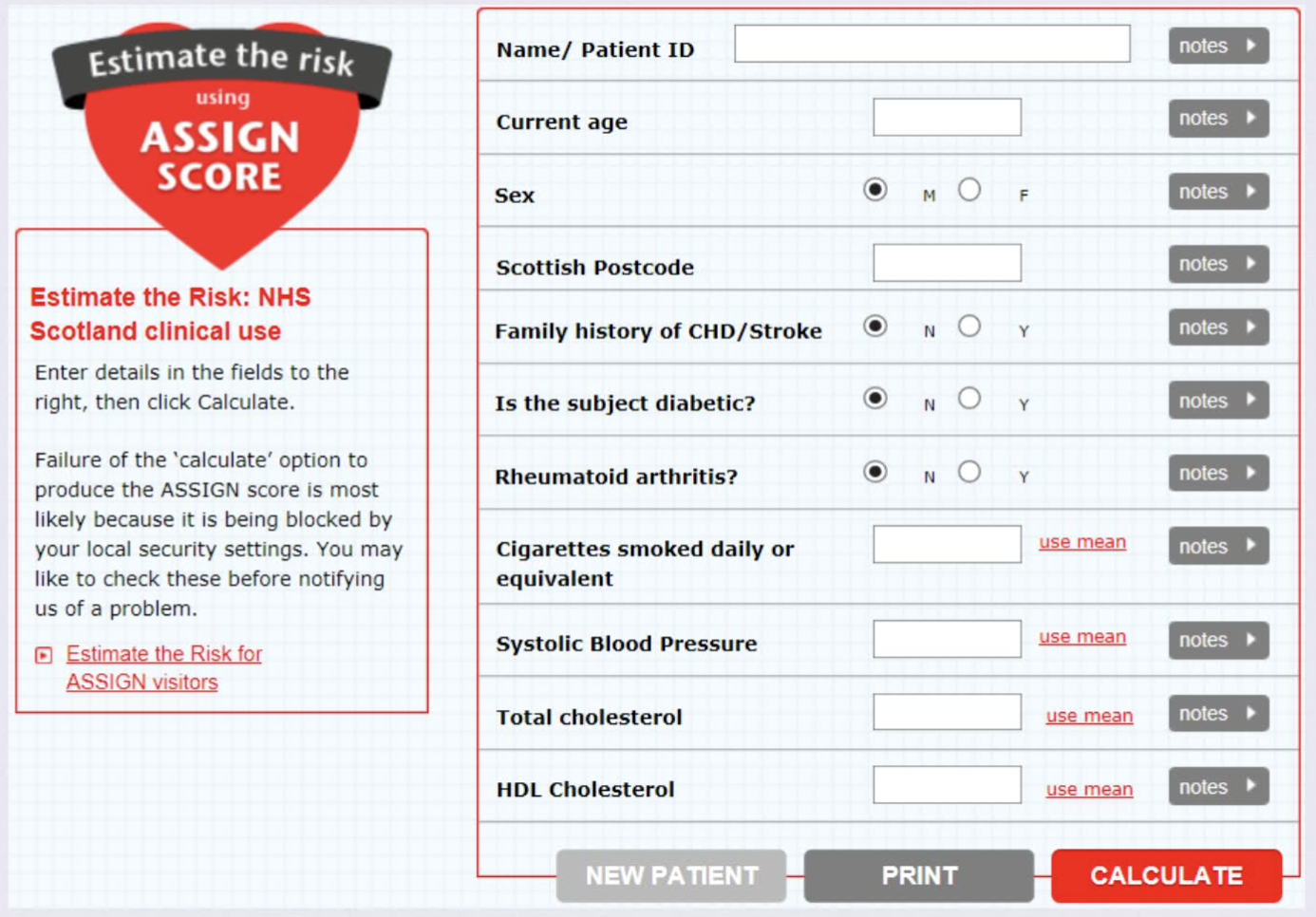
-
评分系统
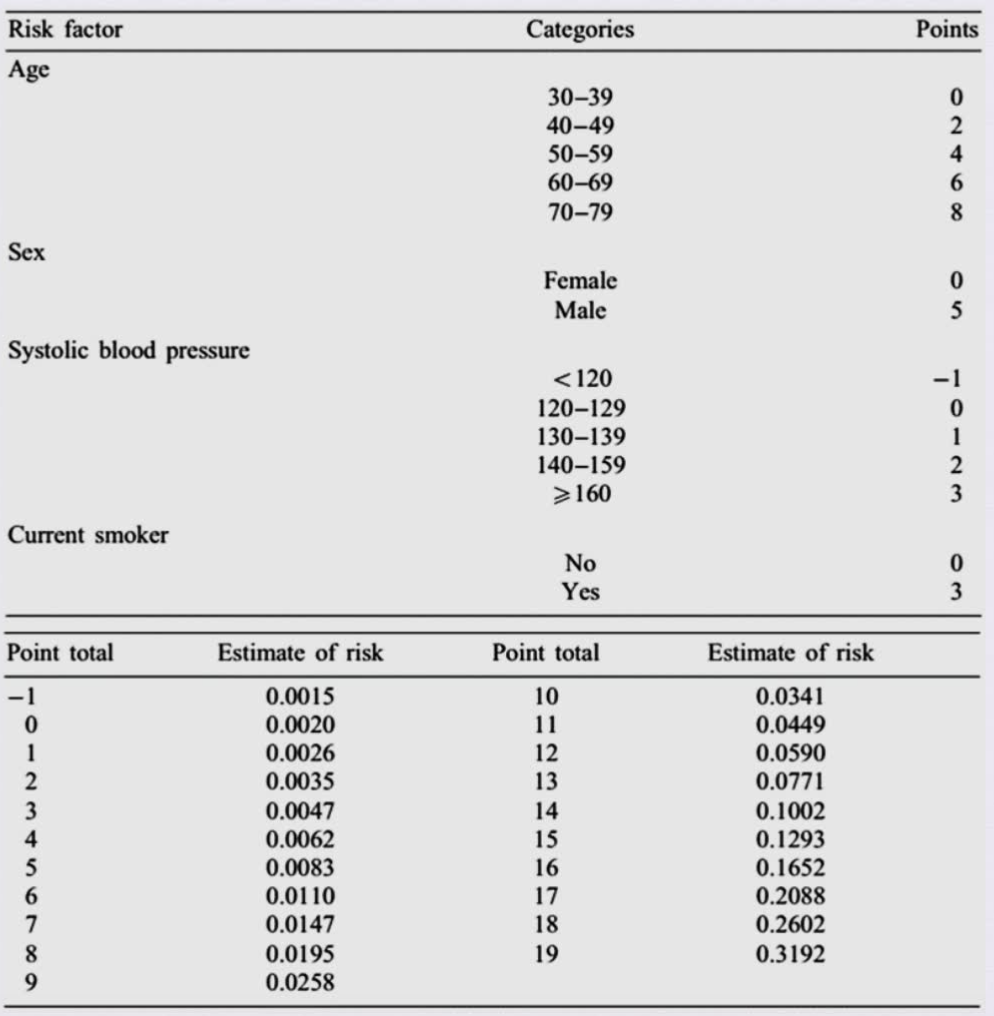
3. 临床预测模型构建方式
参数化和半参数化模型的特点在于可以给出回归系数;非参数化模型则没有回归方程,没有回归系数,因此较难转化为临床可解释的结果,但是可以实现预测。
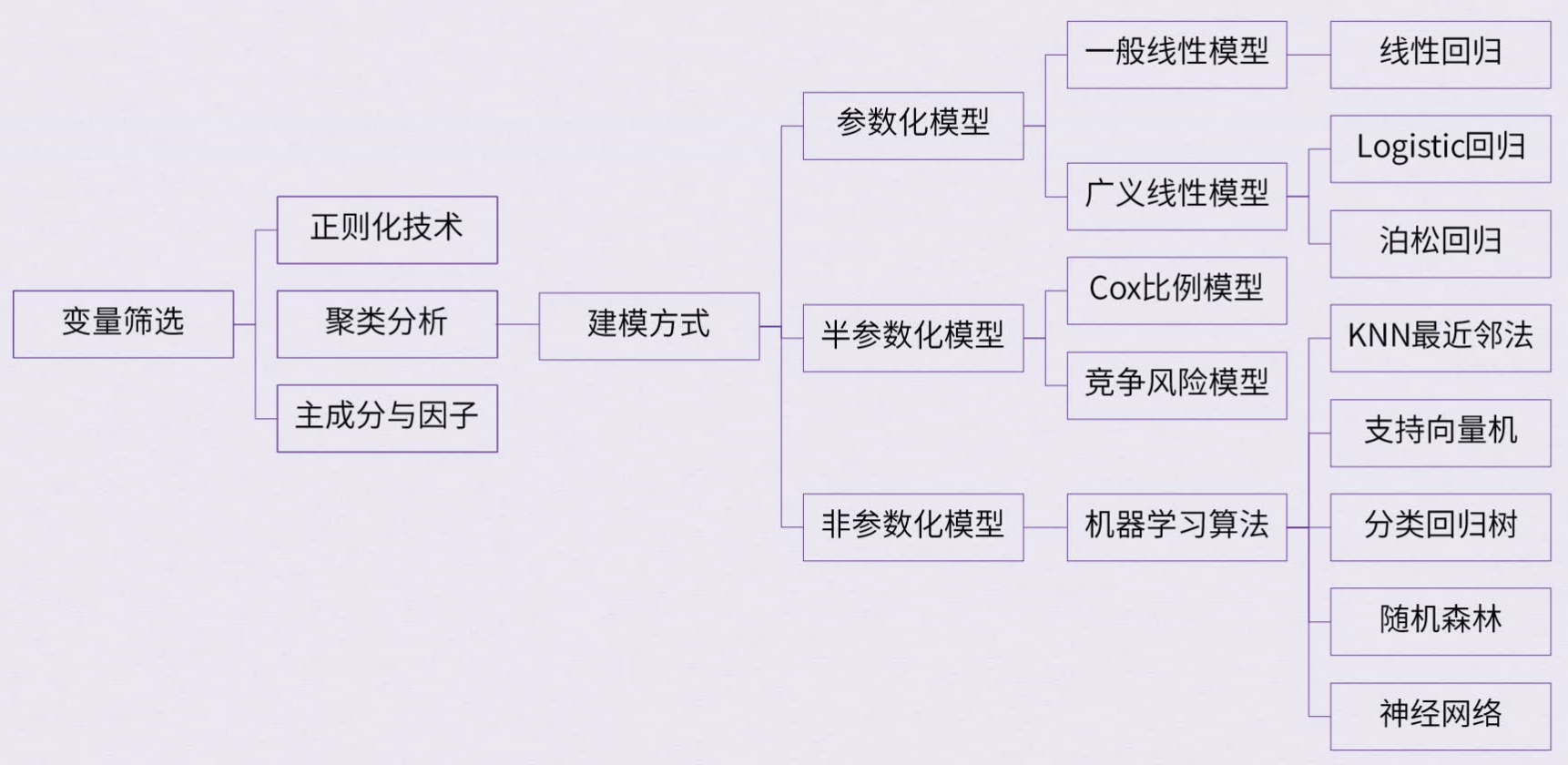
**补充:**变量筛选
- 正则化技术:岭回归、lasso 回归、弹性网络
- 变量降维技术(非参模型):聚类分析、主成分与因子
4. 临床预测模型类研究思路
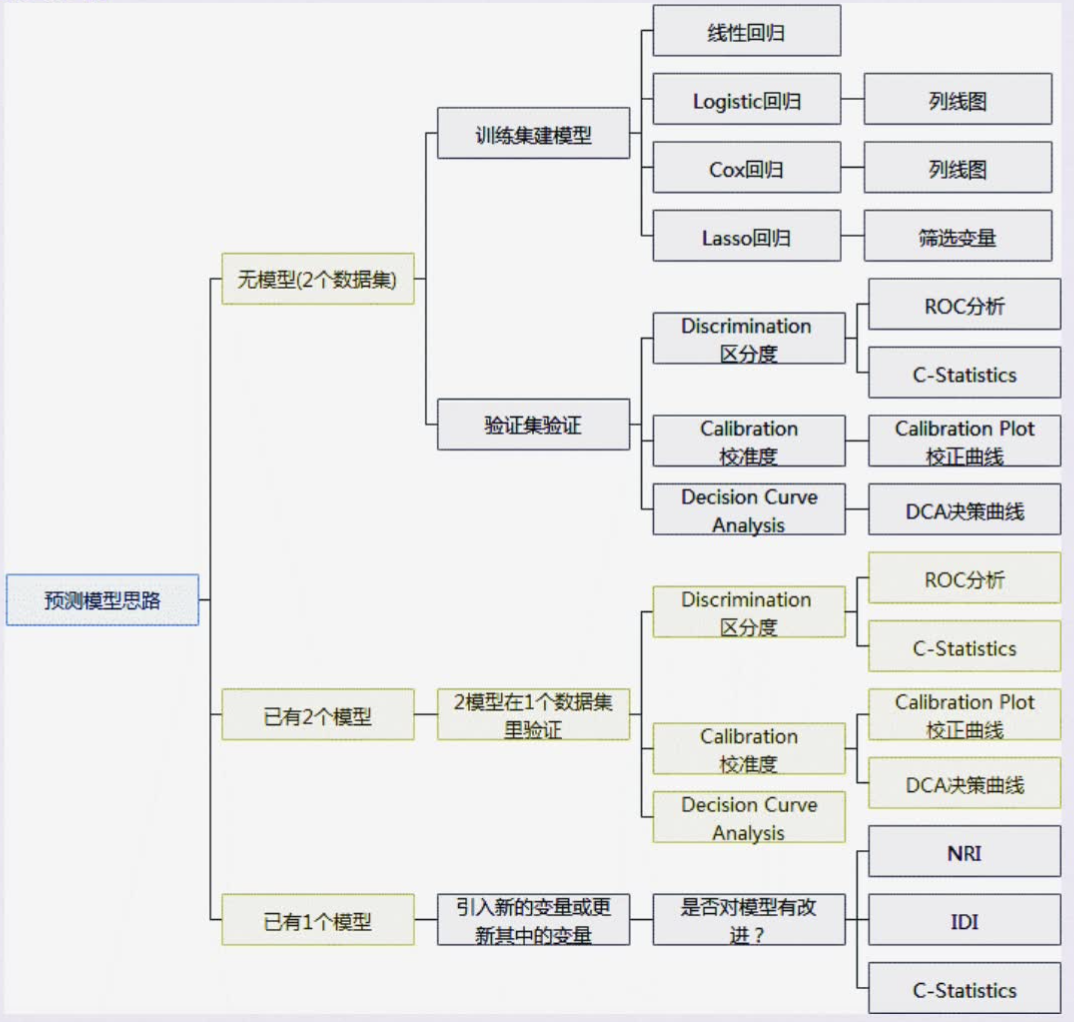
5. 临床预测模型的构建
- 结果为二分类(是否死亡、是否痊愈)-> 构建二分类 Logistic 临床预测模型
- 结果为等级资料(心功能分级)-> 构建有序 Logistic 临床预测模型
- 结果指标包括生存结局、生存时间 -> 构建生存资料的临床预测模型,根据生存结局是否包含竞争事件,决定是拟合 Cox 回归临床预测模型还是拟合竞争风险临床预测模型
临床预测模型流程
Step1. 模型构建
- 先单后多:先进行单因素分析,再将单因素分析“有意义”(此处认为 p<0.05 即为有意义,但其本身也存在一定争议)的变量一起纳入多因素模型。
- 简单且大多数情况下可行
- 在自变量过多、自变量间存在共线性或者缺失值较多时存在一定局限性
- 逐步回归:在构建多因素模型时,并非纳入变量越多越好,因此需要从多因素中挑选部分因素建立“最优”模型(该模型需要能够反映自变量与因变量之间的真实联系,同时自变量数目应尽可能少)。
- 不能保证为最佳模型
- Lasso:对于高维数据,普通变量筛选难以避免过拟合和自变量间的多重共线性问题,Lasso 可以通过限制估计出的系数避免多重共线性(当系数缩减至0即实现了筛选变量),同时还可以通过加入正则化项避免过拟合。
- 可能会将存在共线性的自变量强行剔除
- 随机森林:有监督学习,对于样本和自变量进行抽样生成多个决策树并进行预测,将预测结果的众数或平均数作为预测结果汇总以提升准确率
- 当没有验证数据时,可以使用决策树未用到的样本估计,与真实结果比较得到带外误差
- 最优子集:对 p 个自变量的所有可能组合(共 2^p 个)分别使用回归进行拟合,根据残差平方和 RSS 和 R^2 的改善情况选择最优模型,筛选对因变量影响较大的自变量
Step2. 模型评价
在模型构建过程中,所拟合的模型不一定是最优模型或者好模型,即其可能存在欠拟合的情况,因此需要进行模型评价。
-
拟合优度检验:使用拟合度检验计算每个个体结局事件的预测值,并按照预测值大小对数据分组(一般为5~10组),进行 Hosmer-Lemeshow 拟合优度检验,考察预测值与实际值的吻合程度,p>0.05则说明模型拟合效果较好
-
ROC 曲线:主要用来评价预测模型的鉴别/区分能力,可用于不同指标间的比较,以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制曲线,曲线越接近左上角,曲线下面积越大,其预测价值越大,一般认为面积大于0.8诊断价值较大。
-
Calibration 校准曲线:一般用于评价预测模型准确性,以预测发生率为横坐标,以实际发生率为纵坐标的散点图,对其直线拟合,如果各点均落在过原点、斜率为45º的直线上则准确性好,离直线越远则越差。
-
DCA 曲线:以阈概率为横坐标,以利减去弊之后的净获益率为纵坐标,曲线整体越靠近右上角表明预测模型实用性越好。实际应用时存在两条参考线:
(1) 横线表示所有样本都是阴性,所有人都未接受干预,净获益率为 0 ,
(2) 斜线表示所有样本都是阳性,所有人都接受了干预,净获益曲线为斜率为负值的反斜线;
DCA 曲线越靠近两条参考线,其临床实用性越差。
Step3. 模型验证
对于所构建的模型,当用于预测另外的数据时可能效果不佳出现过拟合的现象,因此需要进行模型验证。
- 交叉验证:将一定比例数据挑选出来作为训练集,将其余未选中样本作为测试集,先在训练集上构建模型,再在测试集上做预测。
- 内部验证:手动将样本随机分成训练集、测试集,先在训练集上获取模型,再在测试集上进行测试
- Hold out Method(简单交叉验证)-> 最常用
- K-fold Cross Validation(K-CV,K折交叉验证)
- Leave-One-Out Cross Validation(LOO-CV,留一法交叉验证/N折交叉验证)
- 外部验证:基于内部数据建模完成之后,收集外部数据进行模型的验证
- 内部验证:手动将样本随机分成训练集、测试集,先在训练集上获取模型,再在测试集上进行测试
- Bootstrap 法:非参数统计方法,对样本进行重抽样估计总体特征。
- 充分利用已知样本信息,具有一定的稳健性
- 可以避免交叉验证造成的样本减少问题
- 可用于创造样本随机性
参考
- 丁香公开课:临床预测模型构建&机器学习(R语言进阶)
- 《R语言临床预测模型实战》(清华大学出版社)

















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









