




 博客围绕R语言相关性分析展开,介绍了Pearson、Spearman和Kendall相关及偏相关类型,提及相关性显著性检验函数cor.test()和corr.test(),说明了不同分布下相关性方法的选择,还详细阐述了使用corrplot、ggcorrplot包及pheatmap绘制相关性热图的方法。
博客围绕R语言相关性分析展开,介绍了Pearson、Spearman和Kendall相关及偏相关类型,提及相关性显著性检验函数cor.test()和corr.test(),说明了不同分布下相关性方法的选择,还详细阐述了使用corrplot、ggcorrplot包及pheatmap绘制相关性热图的方法。
目录
相关的类型
1. Pearson、Spearman和Kendall相关
cor(x, y = NULL, use = "everything",
method = c("pearson", "kendall", "spearman"))
states<-state.x77[,1:6]
cov(states)#协方差
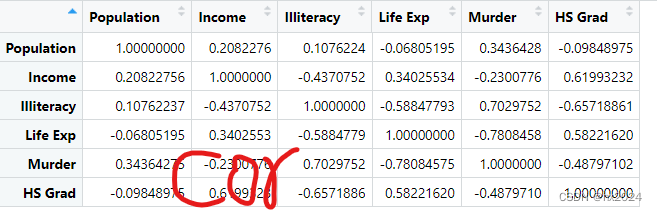
cor <- cor(states)#相关性
1.计量资料 计量资料(measurement data)又称定量资料(quantitative data)或数值变量(numericalvariable)资料。为观测每个观察单位某项指标的大小而获得的资料。其变量值是定量的,表现为数值大小,一般有度量衡单位。根据其观测值取值是否连续,又可分为连续型(continuous)或离散型(discrete)两类。前者可在实数范围内任意取值,如身高、体重、血压等;后者只取整数值,如某医院每年的病死人数等。
2.计数资料 计数资料(cnumeration data)又称定性资料(qualitative data)或无序分类变量(unorderedcategorical variable)资料,亦称名义变量(nominal variable)资料。为将观察单位按某种属性或类别分组计数,分组汇总各组观察单位数后而得到的资料。其变量值是定性的,表现为互不相容的属性或类别,如试验结果的阳性阴性、家族史的有无等。分两种情形:
(1)二分类:如检查某小学学生大便中的蛔虫卵,以每个学生为观察单位,结果可报告为蛔虫卵阴性与阳性两类;如观察某药治疗某病患者的疗效,以每个患者为观察单位,结果可归纳为治愈与未愈两类。两类间相互对立,互不相容。
(2)多分类:如观察某人群的血型分布,以人为观察单位,结果可分为A型、B型、AB型与O型,为互不相容的四个类别。
3.等级资料 等级资料(ranked data)又称半定量资料(semi-quantitative data)或有序分类变量(ordinalcategorical variable)资料。为将观察单位按某种属性的不同程度分成等级后分组计数,分类汇总各组观察单位数后而得到的资料。其变量值具有半定量性质,表现为等级大小或属性程度。如观察某人群某血清反应,以人为观察单位,根据反应强度,结果可分一、±、+、++、+++、++++六级;又如观察用某药治疗某病患者的疗效,以每名患者为观察单位,结果可分为治愈、显效、好转、无效四级等。
2. 偏相关
library(ggm)
pcor(c(1,5,2,3,6),cov(states))
[1] 0.3462724pcor(c(1,5,2,3,6),cov(states))##控制了变量
相关性的显著性检验
cor.test()
可以使用cor.test()函数对单个的Pearson、Spearman和Kendall相 系数进行检验。简化后的使用格式为:
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),#指定进行双侧检验或单侧检验
method = c("pearson", "kendall", "spearman"),#计算的相关类型
exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8267
8267



 到【灌水乐园】发言
到【灌水乐园】发言







