



强化学习的性能很大程度取决于奖励的可获取性与设计质量。本文围绕稀疏奖励、逆强化学习、目标经验回放(HER)、课程式强化学习以及约束处理,梳理关键概念与实践技巧。
目录
在强化学习(RL)的落地过程中,算法工程师往往会有这样的感叹:“模型调参只是体力活,设计奖励函数才是玄学。”
一个好的奖励函数能让智能体(Agent)一日千里;而一个糟糕的设置,要么让 Agent 在稀疏奖励(Sparse Reward) 的荒漠中迷失,要么让 Agent 为了高分而无视安全约束(Constraints)。
本文将深入探讨解决奖励难题的法宝,并配合图解,带您看透其背后的逻辑。
奖励稀疏性与为什么难
- 稀疏奖励:只有在终点或极少时刻才给回报(如完成迷宫、抓到物体)。
- 难点:探索成本高、信用分配困难,导致学习不稳定或停滞。
- 对策总览:提升奖励密度(塑形/替代目标)、改进探索(HER/课程)、学习隐式奖励(逆强化学习)、引入约束优化安全性。
2. 逆强化学习 (IRL):让专家“言传身教”
当我们无法用公式写出什么是“完美的驾驶习惯”或“优雅的步态”时,最好的办法是让 Agent 模仿专家。逆强化学习不是直接模仿动作(那是行为克隆),而是学习专家行为背后的奖励函数。
- 核心思路:从专家轨迹推断一个奖励函数 R,使专家策略在该奖励下最优或近似最优。相当于“先学会人喜欢什么,再用 RL 去最大化”。
- 常见方法:
- 最大熵 IRL:在满足专家特征匹配的同时最大化路径熵,避免过度确定性,数学上是求解
p(τ) ∝ exp(∑ r(s,a))的分布。 - 生成对抗式 IRL(GAIL/AIRL):判别器学习区分专家与策略轨迹,相当于学习潜在奖励;策略通过对抗训练逼近专家。AIRL 直接给出可迁移的奖励函数。
- 能量模型/分布匹配:直接拟合轨迹分布,再还原到奖励或能量函数(如 Diffusion-IRL)。
- 最大熵 IRL:在满足专家特征匹配的同时最大化路径熵,避免过度确定性,数学上是求解
- 案例(机器人抓取示意):收集 50-100 条人示范的抓取轨迹(包含成功/失败),用 GAIL 训练判别器与策略;判别器输出作为奖励,策略在仿真中滚动优化,最终可在真实机器人上零/小样本微调。
- 适用场景:奖励难以手工设计(自动驾驶交规偏好、机器人操作、对话/推荐的用户偏好)。
- 实践要点:
- 专家数据质量决定上限;多样且覆盖典型状态更好,可混入少量合成/扩增示范。
- 特征/表示学习重要:视觉任务可用自监督或对比学习先训编码器,再冻结/微调。
- 训练稳定性:对抗法需梯度平衡与正则(梯度惩罚、谱归一化);判别器不能过强,否则奖励饱和。
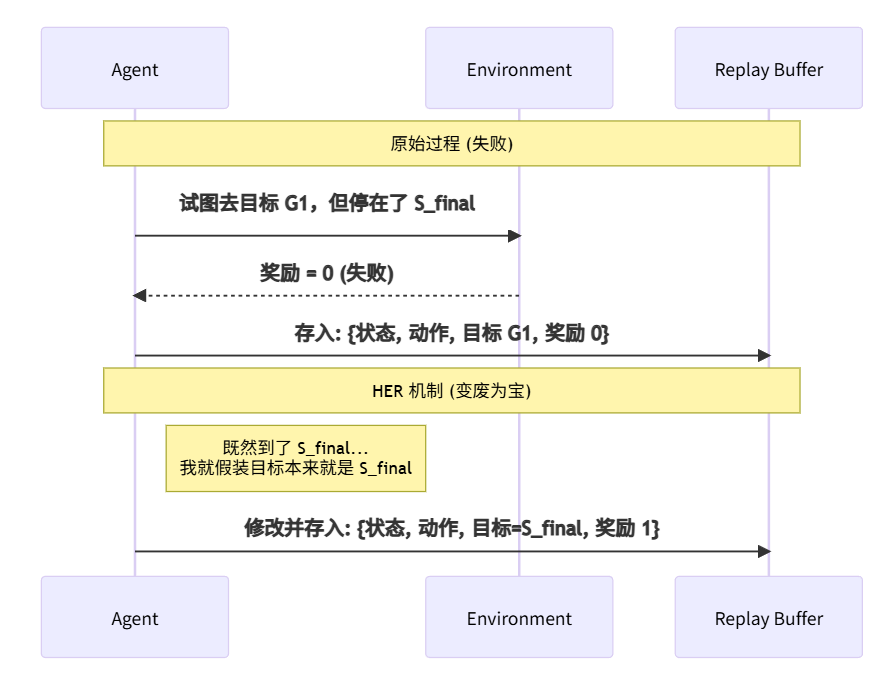
3. 目标经验回放 (HER):解决稀疏奖励的神来之笔
在机械臂抓取等任务中,只有“抓到了”才有 1 分,其他时候全是 0 分。Agent 可能探索几万次都拿不到 1 分,梯度无法更新。HER (Hindsight Experience Replay) 的思想是:事后诸葛亮。哪怕没做到原本的目标,但我到达了另一个地方,我就假设那个地方就是我原本想去的。
- 核心技巧:将“已达成的结果”当作“本该达到的目标”进行重标记,把失败轨迹变成成功样本,显著提升稀疏奖励下的样本效率。
- 适用:多目标或目标可描述的任务(如位姿控制、导航、抓取)。常与 DDPG/TD3/SAC + goal conditioning 结合。
- 工作流程示例(FetchReach):
- 采集一条 episode,原目标 g 是抓手移动到坐标 g;实际达到的坐标记为 g’。
- 写入 replay buffer 时保存
(s,a,s', achieved_goal=g', desired_goal=g)。 - 训练时重采样多个目标:用 future 策略抽取同一轨迹后面的 achieved_goal 作为新的 desired_goal,再重算奖励
r' = f(achieved_goal', desired_goal')。 - 在同一 batch 中混合原始与重标记样本,更新 Q/策略网络。
- 关键配置:
- 目标表示:在 replay buffer 中同时存储 state、action、next_state、achieved_goal、desired_goal。
- 采样策略:future(从同一轨迹后续时刻抽目标)通常效果最好;也可尝试 final/episode;抽取比例常用 4:1 或 8:1(HER:原始)。
- 奖励重写:用重标记后的 goal 重新计算 r;注意终止条件与成功判定。
- 注意:
- 与稀疏奖励天然契合,但需小心分布偏移;可搭配探索噪声、随机目标采样或混入 dense shaping。
- 若目标空间大且语义复杂,可引入语言/视觉嵌入(如 CLIP 表达目标),配合对比或自监督对齐。
- 若使用分层策略,高层提出子目标,低层可结合 HER 重标记子目标,加速学习技能。
4. 课程式强化学习 (Curriculum RL):从入门到精通
不要试图让刚出生的婴儿跑马拉松。课程式学习主张动态调整环境难度,解决奖励过难获取的问题。
- 思路:从简单到难组织训练任务/目标,降低探索难度、平滑策略提升。
- 设计方式:
- 手工课程:先易后难地调节目标距离、障碍数量、动作限制。
- 自适应课程:基于成功率自动调节任务难度(目标采样分布随成功率移动)。
- 教师-学生:教师生成有挑战但可解的任务(如 ALP-GMM、RL^2)。
- 实践技巧:
- 难度信号要可度量(成功率/回报分位数)。
- 难度调节要防止灾难性遗忘(混合采样旧任务)。
- 课程与 HER 可叠加:课程调节目标分布,HER提升利用率。
- 案例(迷宫导航):从“无障碍短距离”开始,成功率>80% 时增加障碍或延长路径;若成功率<30%,回退到上一难度并加大 HER 重标记比例;全程保留 10-20% 旧难度样本防遗忘。
5.奖励的设置技巧:魔鬼在细节中
当必须人工设计奖励时,我们需要关注以下四个维度:
(1) 正负奖励与大小 (Magnitude & Sign)
如果奖励是 +1000,梯度更新步长太大,网络权重会震荡(Exploding)。
如果奖励是 +0.0001,网络可能学不动(Vanishing)。
最佳实践:通常将奖励裁剪(Clip)到 [-1, 1] 区间,或者使用 Batch Normalization 对奖励进行归一化。
(2) 奖励塑形 (Reward Shaping)
为了引导 Agent,我们不仅给最终结果打分,还给过程打分。
普通的塑形容易导致 Agent 绕圈刷分。
基于势能的塑形 (Potential-based):
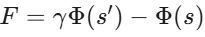
这就像物理学中的势能,无论你怎么绕路,从 A 点到 B 点的势能差是固定的,保证了最优策略不变。
(3) 分层强化学习 (HRL)
解决“长程任务”(Long-horizon)的奖励分配问题。
(4) 约束强化学习 (Constrained RL)
场景:自动驾驶不能撞人,机械臂不能打翻水杯。
普通方法 vs. 约束方法:
普通方法:撞人扣 10000 分。风险:如果赶时间的奖励是 10001 分,Agent 依然会选择撞人。
约束方法 (CMDP):将优化目标与约束分离。
图解概念:优化可行域
想象一个山峰(奖励函数曲面)。普通 RL 寻找最高点。
约束 RL 在山峰周围画了一个圈(安全边界)。Agent 只能在圈内寻找最高点,哪怕圈外的点更高,绝对不允许越界。
总结
不想设奖励? 用 IRL 抄作业。
奖励太难拿? 用 HER 改答案,或 Curriculum 降难度。
必须自己设?
HRL 拆解任务;
Reward Shaping 引导方向;
Constrained RL 守住底线。
奖励的设置与塑形策略
- 正负奖励与尺度:保持量级稳定,避免梯度爆炸/消失;对称处罚(撞墙、超时)与鼓励(接近目标)要量纲一致。
- 奖励塑形(Reward Shaping):
- 潜在函数塑形(Potential-based, Ng et al. 1999):F(s,a,s’) = γΦ(s’) - Φ(s),在理想条件下不改变最优策略。
- 距离型塑形:对目标距离/角度等连续度量给平滑奖励,避免纯稀疏。
- 进度奖励:分阶段里程碑(通过门、完成子任务)。
- 惩罚噪声:对高能耗、抖动、危险动作小幅惩罚。
- 分层强化学习(HRL):
- 高层选子目标/技能,低层执行;减少长视野信用分配难度。
- 高层可用稀疏奖励,低层用密集塑形;搭配 HER 重标记子目标。
- 实用准则:
- 少改 reward,大改状态/目标分布先看收敛曲线与行为。
- 避免“奖励黑洞”:塑形项不应盖过主目标;定期用 ablation 关掉塑形验证策略是否仍达成主目标。
- 案例(机械臂抓取):主目标奖励=成功抓起+放置 1.0;塑形项=手爪到目标距离的负值(归一化到 -0.1~0),加速度/力矩惩罚 -0.01;每通过“靠近-抓取-抬升-放置”四个子阶段给 0.1 进度奖励,验证 ablation 后主任务仍可完成。
约束强化学习与安全
- 问题:需要同时优化性能与安全/成本(能耗、碰撞、越界)。
- 经典框架:约束马尔可夫决策过程(CMDP),优化主回报 J,约束成本 C≤c。
- 算法路线:
- 拉格朗日法:主网络 + 拉格朗日乘子,在线调节权重(如 PPO-Lagrangian)。
- 安全层/投影:在动作前做可行性投影(control barrier function,QP 层)。
- 惩罚学习:将约束视作成本并加大惩罚,但需调优权重并验证可行性。
- 模型预测/盾牌(shielding):利用模型或规则在高风险时覆盖动作。
- 实践要点:
- 先定义可计算的成本信号(碰撞、越界、扭矩超限)。
- 评估用双指标:主回报与约束违背率/成本分位数。
- 训练中逐步收紧约束或提升惩罚,避免初期完全探索受阻。
- 案例(无人机穿越门框):主回报=通过速度与成功率;成本=机体与障碍的最小距离阈值/碰撞标记;先用较宽安全阈值训练,再逐步收紧;部署前加 QP 投影层限制最大倾角与速度,实测对约束违背率做线上监控。
综合落地建议
- 先定任务类型:稀疏目标类→考虑 HER/课程/HRL;偏模仿→IRL/GAIL;安全敏感→CMDP/拉格朗日。
- 先解决表征:状态/目标编码质量决定算法上限,视觉任务用对比学习或预训练特征。
- 监控:成功率、平均回报、成本、约束违背率、动作分布;定期可视化轨迹。
- 消融与调参:关掉塑形项、调整目标采样、修改课程难度,验证行为变化。
小结
- 稀疏奖励需要提升样本利用率(HER)和探索可行性(课程/HRL)。
- 奖励难以显式设计时,用逆强化学习从专家示范中推断偏好。
- 安全或资源约束通过 CMDP、拉格朗日或安全层处理,评估需双指标。
- 奖励塑形要克制、可解释,并与主目标对齐;定期做消融检查偏差。



















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











