



在机器学习中,通常会需要管理自己的训练过程,我们很多同学可能是使用tensorboard或者直接npz来管理和记录训练过程的数据,但是问题在于都是本地化的,如果想要更加便捷,通过账户的形式直接上传云端,这样能够大大方便我们的训练和管理过程。今天要介绍的wandb工具就是新一代的训练记录与管理工具。
如何从零开始使用wandb呢?以下是具体的工作过程。
注册并登录wandb
前往官网进行注册(需要魔法):https://wandb.ai/
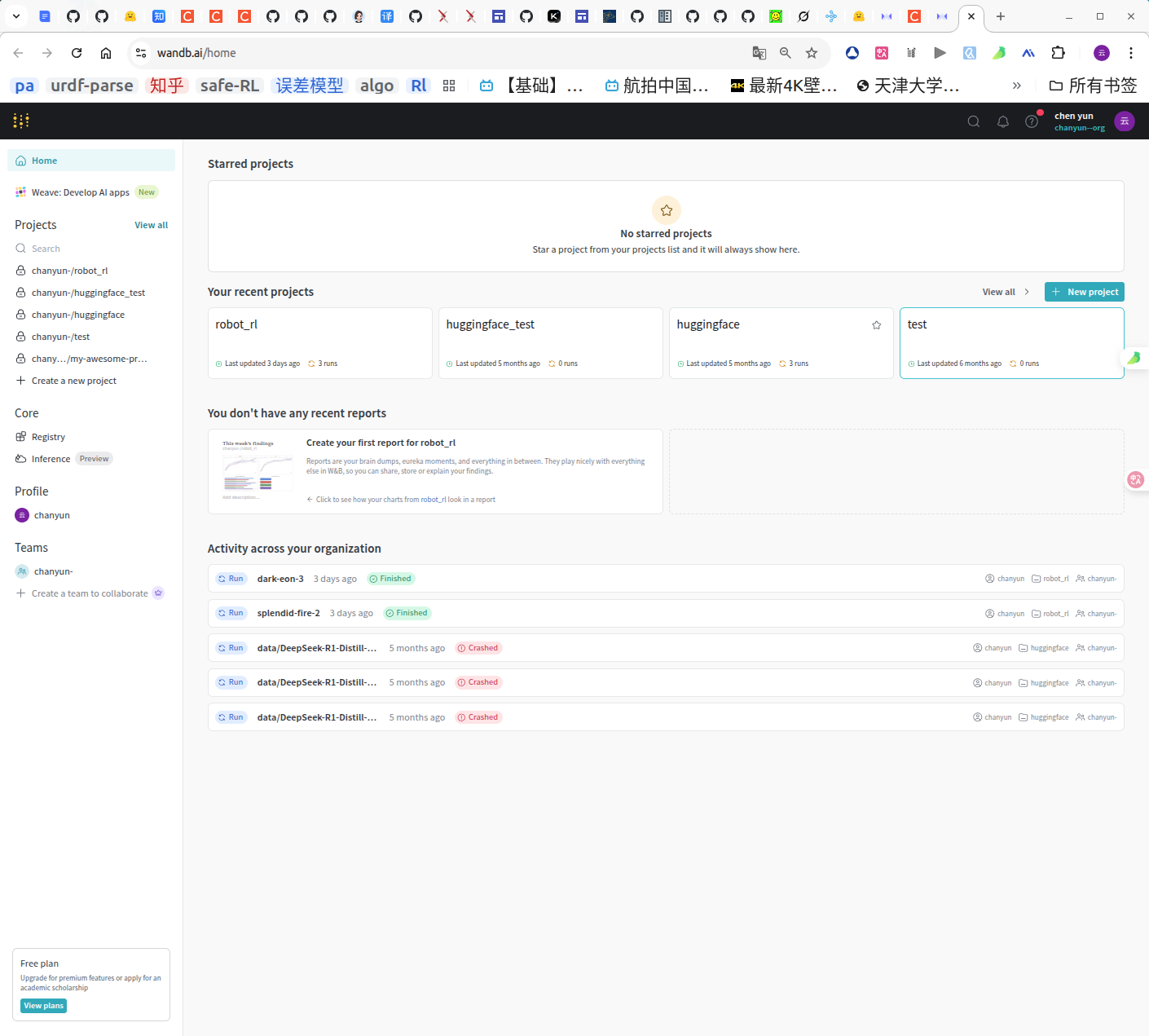
我使用的是google登录,由于个人的配置是与登录有关的,所以需要额外注意设置的用户名,密码等。通过new project创建一个新的项目:
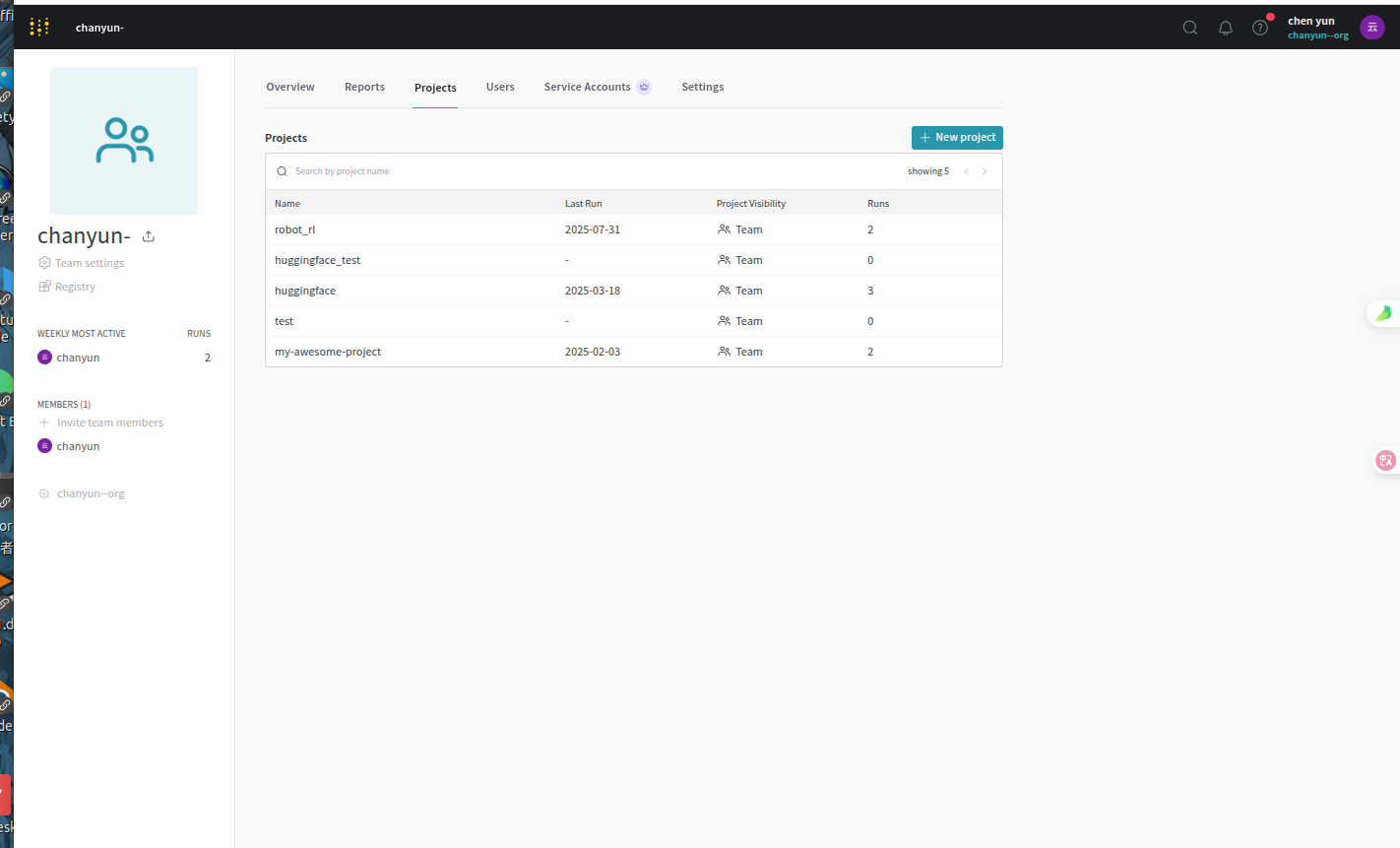
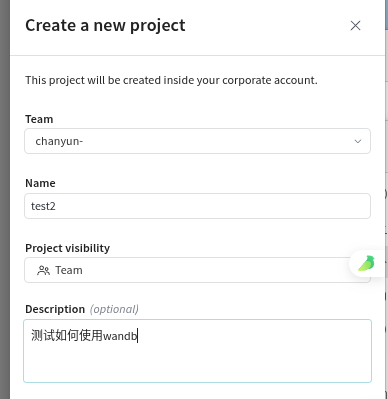
创建完成之后默认进入了weave中,我们需要的是models,并且可以看到自己的登录API密钥:
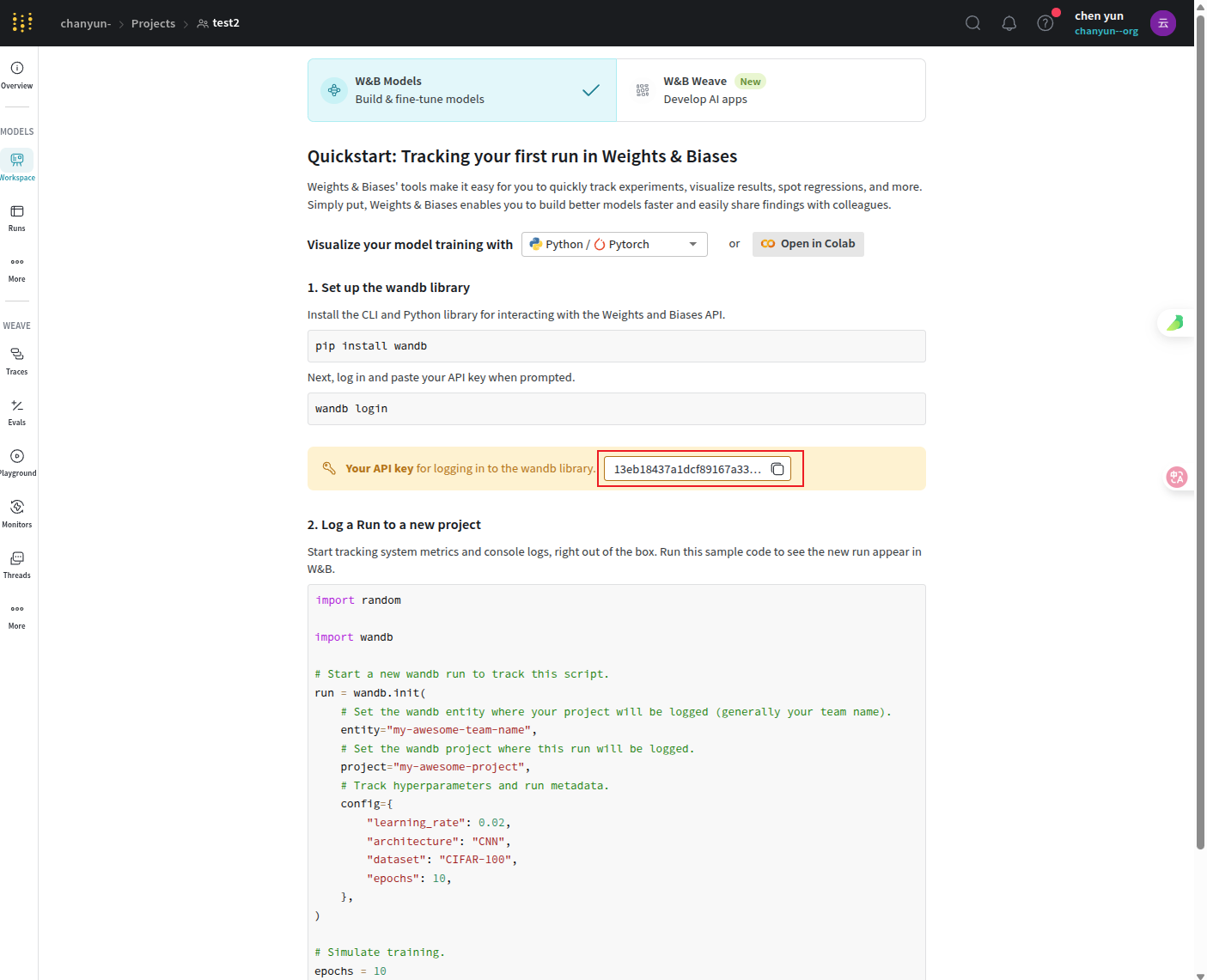
本地安装wandb并登录
在自己的python环境中安装wandb包,并且登录自己的账户:
pip install wandb
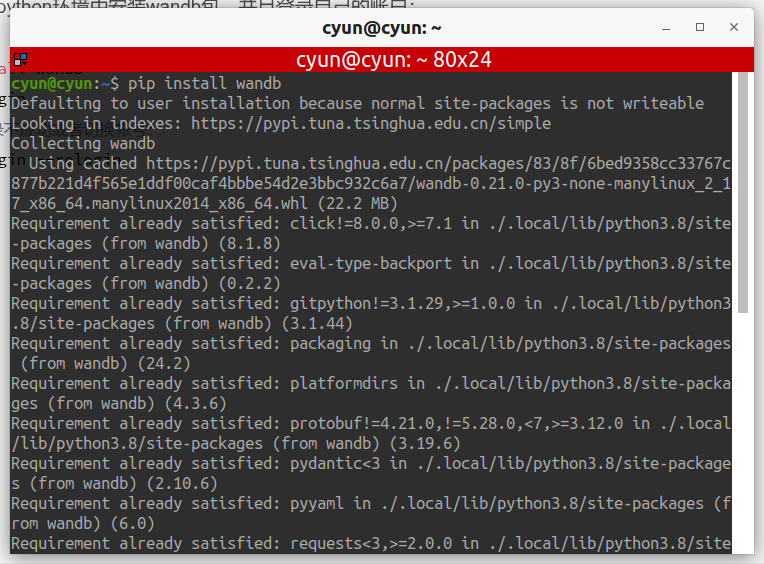
wandb login
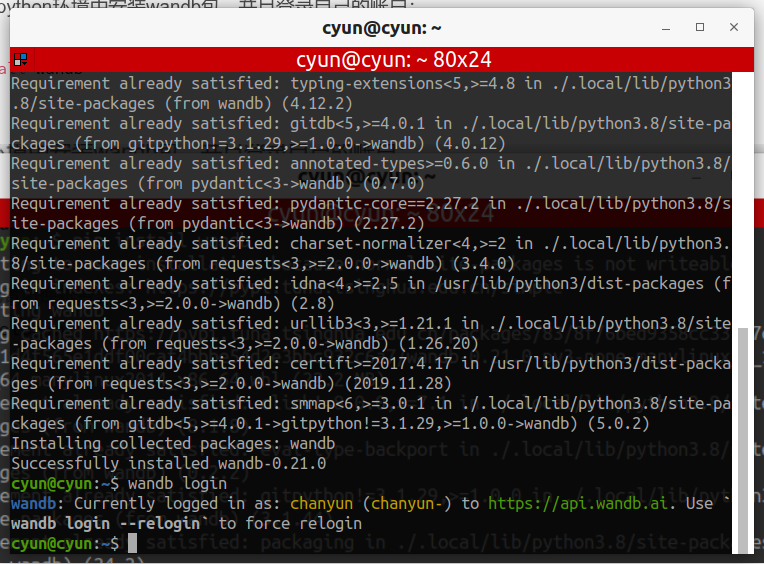
我这里直接就登录成功了,但是如果是第一次登录,需要进行配置,所以参考切换帐号的登录方式:
wandb login --relogin
对于初始登录而言,就是两个步骤,一个是按照链接给的地址登录网站,一个是输入刚才的API密钥:
cyun@cyun:~$ wandb login --relogin
wandb: Logging into wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server)
wandb: You can find your API key in your browser here: https://wandb.ai/authorize?ref=models
wandb: Paste an API key from your profile and hit enter, or press ctrl+c to quit:
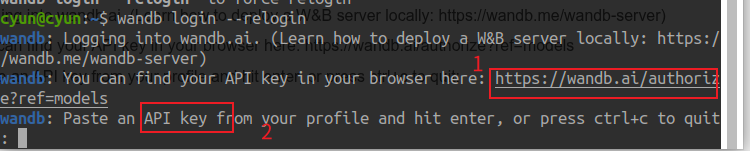
然后就完成了登录。
本地调试
在训练的时候,有时候会先进行调试,所以可以不启用wandb的云端数据上传功能。也就是设置了环境变量如下:
import os
os.environ['WANDB_MODE'] = 'offline'
调用上面语句可以在调试的时候不传数据去云端,但是运行日志会保留在本地?
此功能一般在调试bug的时候不想在云端保存训练数据时使用。
wandb的正式使用过程
我们通过python库去实现wandb的使用。步骤比较固定,按照相应过程即可。
导入wandb及其初始化
import wandb
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
# 1. 初始化wandb项目(每次训练会生成一个新的run)
wandb.init(
project="my_pytorch_training", # 项目名称(自定义)
name="first_experiment", # 本次实验名称(可选)
config={ # 记录超参数(自动保存到wandb)
"learning_rate": 0.001,
"batch_size": 32,
"epochs": 10,
"model": "SimpleCNN"
}
)
config = wandb.config # 可通过config访问超参数
这部分中我们初始化了一个wandb的记录器,并且config使用的是算法的config,这样就能很好的记录当前训练过程的算法超参数的设置。
如果后续还有超参数添加进去,通过以下过程更新:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
wandb.config.update({"device" : device , "model" : "Vgg16"})
记录数据
wandb.log记录相应的数据,可以是字典或者是图片:
if(step%100 == 0):
print("step:{} all_step:{} loss:{}".format(step,int(train_size/4),loss))
wandb.log({"loss": loss,
"epoch":epoch})
这个就是字典的形式记录。如果是图片,需要进行image的指定:
Img = wandb.Image(image, caption="epoch:{}".format(epoch) + string)
wandb.log({"epoch "+str(epoch): Img})
数据本身是自动上传云端的,所以其实也用不着再保存,但是模型可以选择保存一下:
# 7. 训练结束后,保存模型到wandb(可选)
torch.save(model.state_dict(), "model.pth")
wandb.save("model.pth") # 自动上传到wandb服务器
最后结束就行了:
wandb.finish()
完整示例
import wandb
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
# 1. 初始化wandb项目(每次训练会生成一个新的run)
wandb.init(
project="my_pytorch_training", # 项目名称(自定义)
name="first_experiment", # 本次实验名称(可选)
config={ # 记录超参数(自动保存到wandb)
"learning_rate": 0.001,
"batch_size": 32,
"epochs": 10,
"model": "SimpleCNN"
}
)
config = wandb.config # 可通过config访问超参数
# 2. 定义模型、数据和训练组件
class SimpleDataset(Dataset):
def __len__(self):
return 1000
def __getitem__(self, idx):
x = torch.randn(3, 32, 32) # 模拟3通道图像
y = torch.randint(0, 10, (1,))[0] # 模拟10分类标签
return x, y
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 16, 3)
self.fc = nn.Linear(16*30*30, 10)
def forward(self, x):
x = self.conv(x)
x = x.flatten(1)
return self.fc(x)
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
dataloader = DataLoader(SimpleDataset(), batch_size=config.batch_size, shuffle=True)
# 3. 训练循环中记录数据
for epoch in range(config.epochs):
model.train()
total_loss = 0.0
correct = 0
total = 0
for batch_idx, (inputs, labels) in enumerate(dataloader):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 计算批次指标
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 4. 记录批次级数据(每10个批次记录一次)
if batch_idx % 10 == 0:
batch_acc = correct / total
wandb.log({
"batch_loss": loss.item(),
"batch_accuracy": batch_acc,
"batch_idx": batch_idx,
"epoch": epoch # 关联到当前epoch
})
# 5. 记录 epoch 级数据(每个epoch结束后)
epoch_loss = total_loss / len(dataloader)
epoch_acc = correct / total
wandb.log({
"epoch_loss": epoch_loss,
"epoch_accuracy": epoch_acc,
"epoch": epoch
})
# 6. 记录图像(例如输入数据的示例)
if epoch % 2 == 0: # 每2个epoch记录一次
images = inputs[:4] # 取前4张图像
wandb.log({
"train_samples": wandb.Image(images, caption=f"Epoch {epoch} samples")
})
print(f"Epoch {epoch+1}/{config.epochs}, Loss: {epoch_loss:.4f}, Acc: {epoch_acc:.4f}")
# 7. 训练结束后,保存模型到wandb(可选)
torch.save(model.state_dict(), "model.pth")
wandb.save("model.pth") # 自动上传到wandb服务器
# 结束wandb会话
wandb.finish()
注意事项
1.对于数据记录来说,横纵坐标都是非常重要的,横坐标很好理解,就是我们去记录的wandb中的具体的值,比如:
wandb.log({
“batch_loss”: loss.item(),
“batch_accuracy”: batch_acc,
“batch_idx”: batch_idx,
“epoch”: epoch # 关联到当前epoch
})
那么纵坐标呢?
对于一般的记录过程来说,其实并不会在默认的图上显示我们需要的纵坐标,比如这里的:
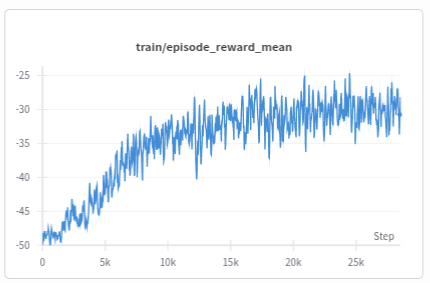
这里的纵坐标指代的含义是每次记录数据的那个step,可能更偏向于episode的含义,具体则是需要看记录数据的频率是如何设计的。同时,u由于我们设置了total_step:
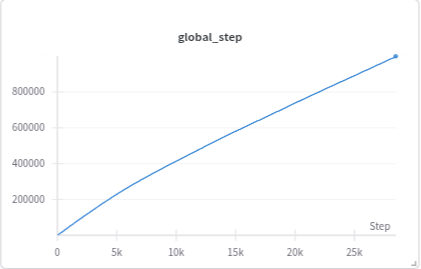
所以就可以自己把这两张图进行组合了:
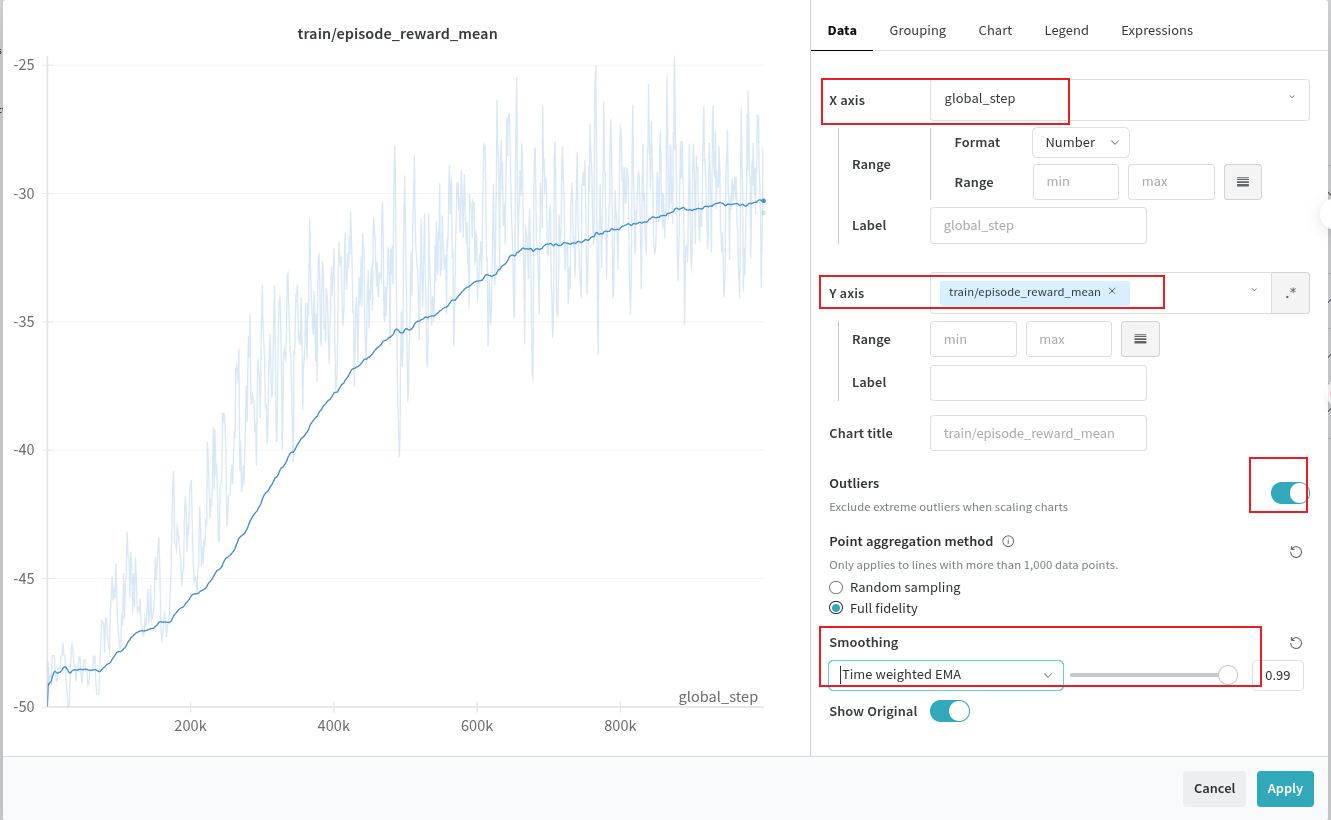
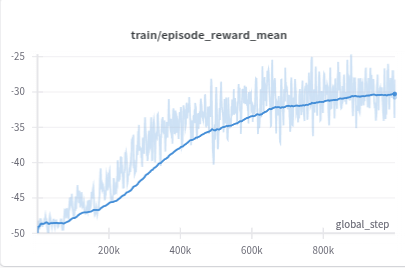
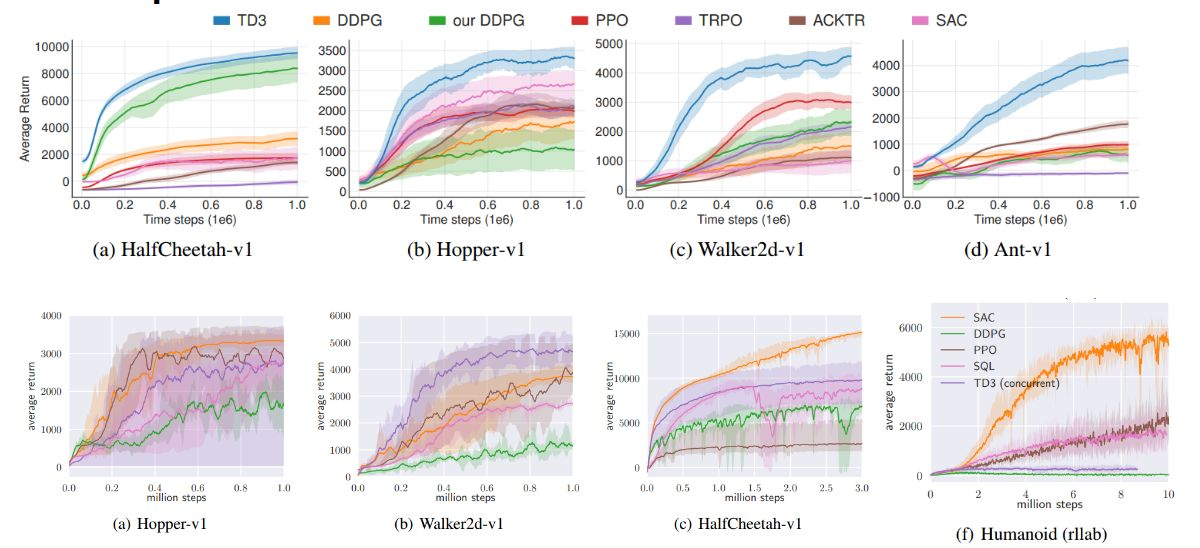
但是对于需要进行各种算法比较的可视化来说,这里的可视化应该是不能满足要求的,所以下一篇文章我们来看如何进行一个标准的训练数据可视化。也就是将wandb的数据进行导出,然后通过seaborn进行绘制的过程了,类似于这样的效果:



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











