



符号解析
1. 基本符号(CMDP与强化学习背景)
-
π ( a ∣ s ) \pi(a|s) π(a∣s): 策略函数,在状态 s s s下选择动作 a a a的概率分布。
- 意义:决定代理行为的概率模型,通常为参数化的神经网络。
- 作用:CPO优化的核心对象,出现在公式3和10中。
- 公式关联:与 J ( π ) J(\pi) J(π)、 J C i ( π ) J_{C_i}(\pi) JCi(π)、 D T V ( π ′ ∥ π ∣ s ) D_{TV}(\pi' \|\pi | s) DTV(π′∥π∣s)、 D ~ K L \tilde{D}_{KL} D~KL相关。
-
J ( π ) J(\pi) J(π): 期望折扣奖励,定义为:
J ( π ) = E τ ∼ π [ ∑ t = 0 ∞ γ t R ( s t , a t , s t + 1 ) ] J(\pi) = \mathbb{E}_{\tau \sim \pi} \left[ \sum_{t=0}^{\infty} \gamma^t R(s_t, a_t, s_{t+1}) \right] J(π)=Eτ∼π[∑t=0∞γtR(st,at,st+1)]- 意义:衡量策略 π \pi π的长期奖励。
- 作用:CPO优化的目标,公式3和10的目标函数。
- 公式关联:定理1和推论1提供其近似界限。
-
J C i ( π ) J_{C_i}(\pi) JCi(π): 期望折扣成本,定义为:
J C i ( π ) = E τ ∼ π [ ∑ t = 0 ∞ γ t C i ( s t , a t , s t + 1 ) ] J_{C_i}(\pi) = \mathbb{E}_{\tau \sim \pi} \left[ \sum_{t=0}^{\infty} \gamma^t C_i(s_t, a_t, s_{t+1}) \right] JCi(π)=Eτ∼π[∑t=0∞γtCi(st,at,st+1)]- 意义:衡量第 i i i个约束的累计成本(如安全性)。
- 作用:CPO确保 J C i ( π ) ≤ d i J_{C_i}(\pi) \leq d_i JCi(π)≤di,公式3、10和推论2相关。
- 公式关联:与 c i c_i ci和 A C i π A_{C_i}^\pi ACiπ连接。
-
d i d_i di: 第 i i i个约束的阈值。
- 意义:成本 J C i ( π ) J_{C_i}(\pi) JCi(π)的上限。
- 作用:定义约束条件,出现在公式3、10和11。
- 公式关联:通过 c i = J C i ( π k ) − d i c_i = J_{C_i}(\pi_k) - d_i ci=JCi(πk)−di影响优化。
-
γ \gamma γ: 折扣因子, γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1)。
- 意义:控制未来奖励和成本的权重。
- 作用:调节 J ( π ) J(\pi) J(π)、 J C i ( π ) J_{C_i}(\pi) JCi(π)和界限中的因子。
- 公式关联:出现在 1 1 − γ \frac{1}{1-\gamma} 1−γ1和 γ ( 1 − γ ) 2 \frac{\gamma}{(1-\gamma)^2} (1−γ)2γ。
-
d π ( s ) d^\pi(s) dπ(s): 折扣未来状态分布,定义为:
d π ( s ) = ( 1 − γ ) ∑ t = 0 ∞ γ t P ( s t = s ∣ π ) d^\pi(s) = (1-\gamma) \sum_{t=0}^{\infty} \gamma^t P(s_t = s | \pi) dπ(s)=(1−γ)∑t=0∞γtP(st=s∣π)- 意义:策略 π \pi π下状态 s s s的访问概率。
- 作用:支持基于当前策略的采样,出现在 L π , f L_{\pi,f} Lπ,f和 D ~ K L \tilde{D}_{KL} D~KL。
- 公式关联:与 D T V ( d π ′ ∥ d π ) D_{TV}(d^{\pi'} \| d^\pi) DTV(dπ′∥dπ)相关。
2. 定理1相关符号
-
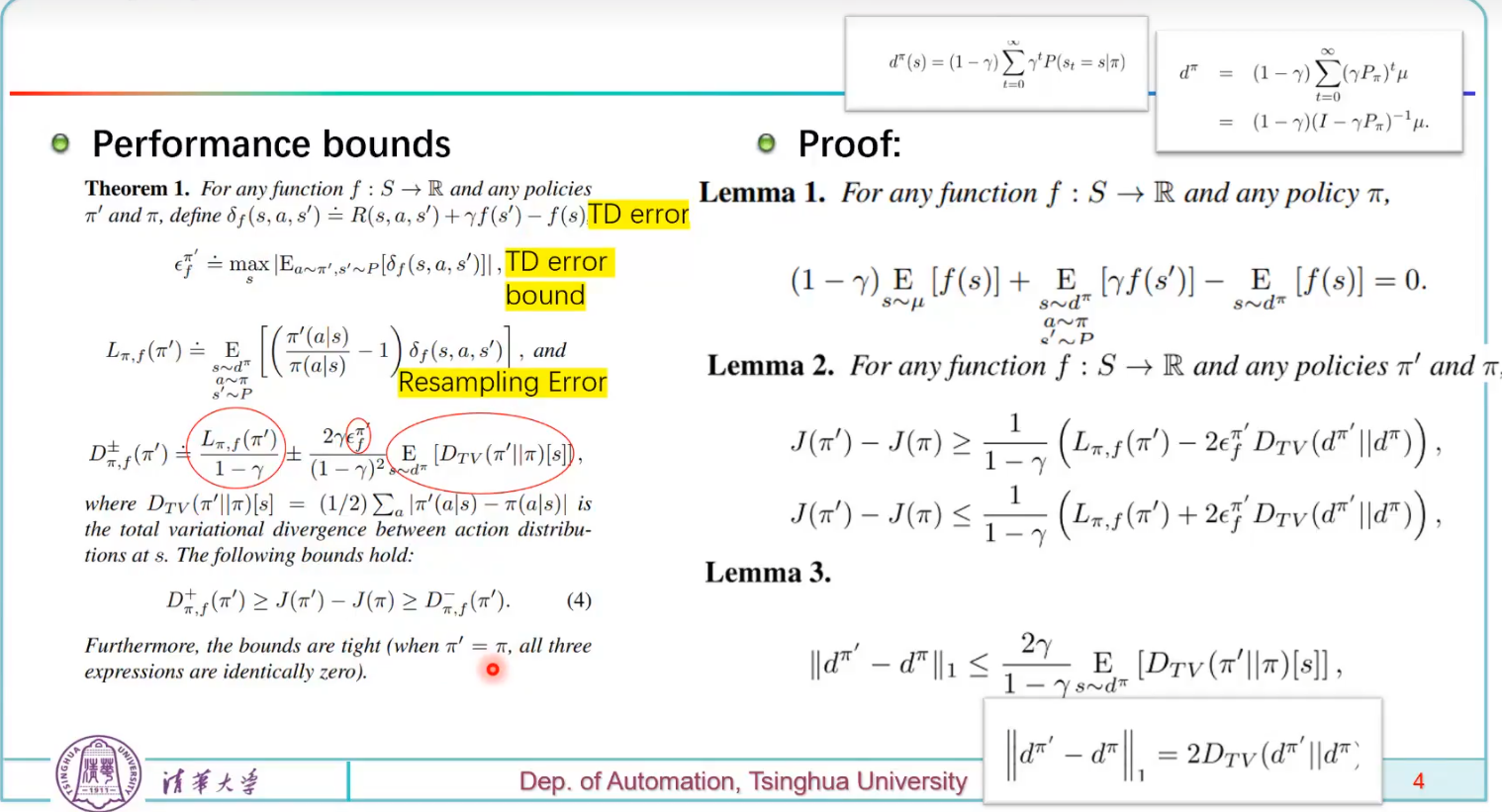
δ f ( s , a , s ′ ) \delta_f(s,a,s') δf(s,a,s′): 辅助函数,定义为:
δ f ( s , a , s ′ ) = R ( s , a , s ′ ) + γ f ( s ′ ) − f ( s ) \delta_f(s,a,s') = R(s,a,s') + \gamma f(s') - f(s) δf(s,a,s′)=R(s,a,s′)+γf(s′)−f(s)- 意义:结合奖励和函数 f f f,衡量状态转移的影响。
- 作用:构造 L π , f ( π ′ ) L_{\pi,f}(\pi') Lπ,f(π′),支持回报差异近似。
- 公式关联:当 f = V π f = V^\pi f=Vπ时, δ f = A π ( s , a ) \delta_f = A^\pi(s,a) δf=Aπ(s,a),用于推论1。
-
L π , f ( π ′ ) L_{\pi,f}(\pi') Lπ,f(π′): 代理函数,定义为:
L π , f ( π ′ ) = E s ∼ d π , a ∼ π ′ , s ′ ∼ P [ ( π ′ ( a ∣ s ) π ( a ∣ s ) − 1 ) δ f ( s , a , s ′ ) ] L_{\pi,f}(\pi') = \mathbb{E}_{s \sim d^\pi, a \sim \pi', s' \sim P} \left[ \left( \frac{\pi'(a|s)}{\pi(a|s)} - 1 \right) \delta_f(s,a,s') \right] Lπ,f(π′)=Es∼dπ,a∼π′,s′∼P[(π(a∣s)π′(a∣s)−1)δf(s,a,s′)]- 意义:近似 J ( π ′ ) − J ( π ) J(\pi') - J(\pi) J(π′)−J(π),使用当前策略的分布。
- 作用:定理1的核心,降低计算复杂度。
- 公式关联:与 δ f \delta_f δf和 A π A^\pi Aπ连接,特化到公式10。
-
ϵ f π ′ \epsilon_f^{\pi'} ϵfπ′: 最大波动,定义为:
ϵ f π ′ = max s ∣ E a ∼ π ′ , s ′ ∼ P [ δ f ( s , a , s ′ ) ] ∣ \epsilon_f^{\pi'} = \max_s \left| \mathbb{E}_{a \sim \pi', s' \sim P} \left[ \delta_f(s,a,s') \right] \right| ϵfπ′=maxs∣Ea∼π′,s′∼P[δf(s,a,s′)]∣- 意义:衡量 δ f \delta_f δf的偏差范围。
- 作用:控制定理1界限的误差。
- 公式关联:出现在 D π , f ± D_{\pi,f}^{\pm} Dπ,f±,特化为 ϵ π ′ \epsilon^{\pi'} ϵπ′和 ϵ C i π ′ \epsilon_{C_i}^{\pi'} ϵCiπ′。
-
D T V ( π ′ ∥ π ∣ s ) D_{TV}(\pi' \|\pi | s) DTV(π′∥π∣s): 总变差距离,定义为:
D T V ( π ′ ∥ π ∣ s ) = 1 2 ∑ a ∣ π ′ ( a ∣ s ) − π ( a ∣ s ) ∣ D_{TV}(\pi' \|\pi | s) = \frac{1}{2} \sum_a |\pi'(a|s) - \pi(a|s)| DTV(π′∥π∣s)=21∑a∣π′(a∣s)−π(a∣s)∣- 意义:度量策略在状态 s s s下的差异。
- 作用:控制界限误差,限制更新幅度。
- 公式关联:通过引理3与 D T V ( d π ′ ∥ d π ) D_{TV}(d^{\pi'} \| d^\pi) DTV(dπ′∥dπ)连接,推论3转为 D K L D_{KL} DKL。
-
D T V ( d π ′ ∥ d π ) D_{TV}(d^{\pi'} \| d^\pi) DTV(dπ′∥dπ): 状态分布差异,定义为:
D T V ( d π ′ ∥ d π ) = 1 2 ∑ s ∣ d π ′ ( s ) − d π ( s ) ∣ D_{TV}(d^{\pi'} \| d^\pi) = \frac{1}{2} \sum_s |d^{\pi'}(s) - d^\pi(s)| DTV(dπ′∥dπ)=21∑s∣dπ′(s)−dπ(s)∣- 意义:度量状态分布的差异。
- 作用:在引理2中控制误差。
- 公式关联:通过引理3转为 E s ∼ d π [ D T V ( π ′ ∥ π ∣ s ) ] \mathbb{E}_{s \sim d^\pi} \left[ D_{TV}(\pi' \|\pi | s) \right] Es∼dπ[DTV(π′∥π∣s)]。
-
D π , f ± ( π ′ ) D_{\pi,f}^{\pm}(\pi') Dπ,f±(π′): 回报界限,定义为:
D π , f ± ( π ′ ) = L π , f ( π ′ ) 1 − γ ± 2 γ ϵ f π ′ ( 1 − γ ) 2 E s ∼ d π [ D T V ( π ′ ∥ π ∣ s ) ] D_{\pi,f}^{\pm}(\pi') = \frac{L_{\pi,f}(\pi')}{1-\gamma} \pm \frac{2\gamma \epsilon_f^{\pi'}}{(1-\gamma)^2} \mathbb{E}_{s \sim d^\pi} \left[ D_{TV}(\pi' \|\pi | s) \right] Dπ,f±(π′)=1−γLπ,f(π′)±(1−γ)22γϵfπ′Es∼dπ[DTV(π′∥π∣s)]- 意义:界定 J ( π ′ ) − J ( π ) J(\pi') - J(\pi) J(π′)−J(π)。
- 作用:支持CPO的代理优化。
- 公式关联:整合 L π , f L_{\pi,f} Lπ,f、 ϵ f π ′ \epsilon_f^{\pi'} ϵfπ′、 D T V D_{TV} DTV,特化到推论1-2。
3. 推论1-3相关符号
-
A π ( s , a ) A^\pi(s,a) Aπ(s,a): 优势函数,定义为:
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)- 意义:衡量动作 a a a的相对优劣。
- 作用:推论1中作为奖励优化的代理目标。
- 公式关联:当 δ f = A π \delta_f = A^\pi δf=Aπ,用于公式10。
-
ϵ π ′ \epsilon^{\pi'} ϵπ′: 优势偏差,定义为:
ϵ π ′ = max s ∣ E a ∼ π ′ [ A π ( s , a ) ] ∣ \epsilon^{\pi'} = \max_s |\mathbb{E}_{a \sim \pi'} [A^\pi(s,a)]| ϵπ′=maxs∣Ea∼π′[Aπ(s,a)]∣- 意义:衡量 A π A^\pi Aπ的偏差。
- 作用:控制推论1的误差。
- 公式关联:替换 ϵ f π ′ \epsilon_f^{\pi'} ϵfπ′,用于命题1。
-
A C i π ( s , a ) A_{C_i}^\pi(s,a) ACiπ(s,a): 约束优势函数,定义为:
A C i π ( s , a ) = Q C i π ( s , a ) − V C i π ( s ) A_{C_i}^\pi(s,a) = Q_{C_i}^\pi(s,a) - V_{C_i}^\pi(s) ACiπ(s,a)=QCiπ(s,a)−VCiπ(s)- 意义:衡量动作对约束成本的影响。
- 作用:推论2中作为约束的代理。
- 公式关联:用于公式10的约束。
-
ϵ C i π ′ \epsilon_{C_i}^{\pi'} ϵCiπ′: 约束优势偏差,定义为:
ϵ C i π ′ = max s ∣ E a ∼ π ′ [ A C i π ( s , a ) ] ∣ \epsilon_{C_i}^{\pi'} = \max_s |\mathbb{E}_{a \sim \pi'} [A_{C_i}^\pi(s,a)]| ϵCiπ′=maxs∣Ea∼π′[ACiπ(s,a)]∣- 意义:衡量约束优势的偏差。
- 作用:控制推论2的误差。
- 公式关联:用于命题2。
-
D ~ K L ( π ∥ π k ) \tilde{D}_{KL}(\pi \|\pi_k) D~KL(π∥πk): 平均KL散度,定义为:
D ~ K L ( π ∥ π k ) = E s ∼ d π k [ D K L ( π ∥ π k ∣ s ) ] \tilde{D}_{KL}(\pi \|\pi_k) = \mathbb{E}_{s \sim d^{\pi_k}} \left[ D_{KL}(\pi \|\pi_k | s) \right] D~KL(π∥πk)=Es∼dπk[DKL(π∥πk∣s)]- 意义:度量策略差异。
- 作用:限制信任区域更新。
- 公式关联:推论3连接 D T V D_{TV} DTV,用于公式10和11。
4. 第6部分相关符号
-
g g g: 目标梯度,定义为:
g = ∇ θ E s ∼ d π k , a ∼ π θ [ A π k ( s , a ) ] ∣ θ = θ k g = \nabla_\theta \mathbb{E}_{s \sim d^{\pi_k}, a \sim \pi_\theta} \left[ A^{\pi_k}(s,a) \right] |_{\theta = \theta_k} g=∇θEs∼dπk,a∼πθ[Aπk(s,a)]∣θ=θk- 意义:奖励优化的方向。
- 作用:驱动公式11的更新。
- 公式关联:来自公式10,进入公式12-13。
-
b i b_i bi: 约束梯度,定义为:
b i = ∇ θ ( J C i ( π k ) + 1 1 − γ E s ∼ d π k , a ∼ π θ [ A C i π k ( s , a ) ] ) ∣ θ = θ k b_i = \nabla_\theta \left( J_{C_i}(\pi_k) + \frac{1}{1-\gamma} \mathbb{E}_{s \sim d^{\pi_k}, a \sim \pi_\theta} \left[ A_{C_i}^{\pi_k}(s,a) \right] \right) |_{\theta = \theta_k} bi=∇θ(JCi(πk)+1−γ1Es∼dπk,a∼πθ[ACiπk(s,a)])∣θ=θk- 意义:约束成本的变化方向。
- 作用:线性化公式11的约束。
- 公式关联:用于公式14和 B B B。
-
c i c_i ci: 约束违反量,定义为:
c i = J C i ( π k ) − d i c_i = J_{C_i}(\pi_k) - d_i ci=JCi(πk)−di- 意义:当前约束违反程度。
- 作用:指导公式11的约束。
- 公式关联:与推论2和命题2相关。
-
H H H: Hessian矩阵,定义为:
H = ∇ θ 2 E s ∼ d π k [ D K L ( π θ ∥ π k ∣ s ) ] ∣ θ = θ k H = \nabla_\theta^2 \mathbb{E}_{s \sim d^{\pi_k}} \left[ D_{KL}(\pi_\theta \|\pi_k | s) \right] |_{\theta = \theta_k} H=∇θ2Es∼dπk[DKL(πθ∥πk∣s)]∣θ=θk- 意义:KL散度的曲率。
- 作用:二次近似公式11的约束。
- 公式关联:与 D ~ K L \tilde{D}_{KL} D~KL相关,进入公式13-14。
-
λ , ν \lambda, \nu λ,ν: 对偶变量。
- 意义: λ \lambda λ控制信任区域, ν \nu ν平衡约束。
- 作用:优化公式12,决定公式13的更新。
- 公式关联:与公式11对应。
-
C i + ( s , a , s ′ ) C_i^+(s,a,s') Ci+(s,a,s′): 整形成本,定义为:
C i + ( s , a , s ′ ) = C i ( s , a , s ′ ) + Δ i ( s , a , s ′ ) C_i^+(s,a,s') = C_i(s,a,s') + \Delta_i(s,a,s') Ci+(s,a,s′)=Ci(s,a,s′)+Δi(s,a,s′)- 意义:平滑约束成本。
- 作用:增强公式11的鲁棒性。
- 公式关联:支持推论2的上界。
公式关系总结
- 第5部分: δ f \delta_f δf、 L π , f L_{\pi,f} Lπ,f、 ϵ f π ′ \epsilon_f^{\pi'} ϵfπ′、 D T V D_{TV} DTV构建定理1的界限, A π A^\pi Aπ、 ϵ π ′ \epsilon^{\pi'} ϵπ′、 A C i π A_{C_i}^\pi ACiπ、 ϵ C i π ′ \epsilon_{C_i}^{\pi'} ϵCiπ′特化到奖励和约束, D ~ K L \tilde{D}_{KL} D~KL连接信任区域,构成公式10。
- 第6部分: g g g、 b i b_i bi、 c i c_i ci、 H H H线性化公式10为公式11, λ \lambda λ、 ν \nu ν求解对偶问题(公式12-13), C i + C_i^+ Ci+增强鲁棒性(公式15),公式14处理不可行情况。
- 整体逻辑:符号从定义问题( π \pi π、 J ( π ) J(\pi) J(π)、 J C i J_{C_i} JCi)到理论界限( δ f \delta_f δf、 L π , f L_{\pi,f} Lπ,f等),再到代理优化( A π A^\pi Aπ、 A C i π A_{C_i}^\pi ACiπ),最后实现高效计算( g g g、 b i b_i bi、 H H H等)。



















 26
26

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











