









关键词:Unbiased Estimation
一、说明
对于无偏和有偏估计,需要了解其叙事背景,是指整体和抽样的关系,也就是说整体的叙事是从理论角度的,而估计器原理是从实践角度说事;为了表明概率理论(不可操作)和统计学(可操作)的实践的一致性,于是提出有偏和无偏的观点。
二、关于无偏和有偏
如果给定参数的估计量 的 预期值等于该参数的真实值, 则称该估计量是无偏的 。另一个说法,如果估计量产生的参数估计平均而言是正确的,那么它就是无偏的。
我们先做一个思想实验,如通过打靶考核射手的水平,假如决定射手的因素有两个:眼力和手平衡。
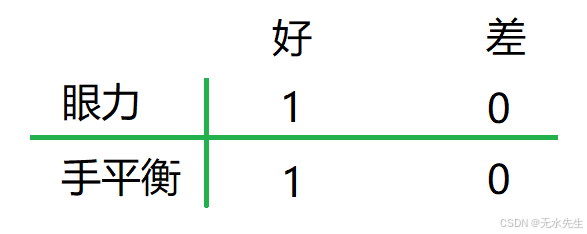
于是对于任意一个选手,这个选手的属性如下:
<眼力=1,手平衡=1>,<眼力=0,手平衡=1>,<眼力=1,手平衡=0>,
<眼力=0,手平衡=0>
打靶结果
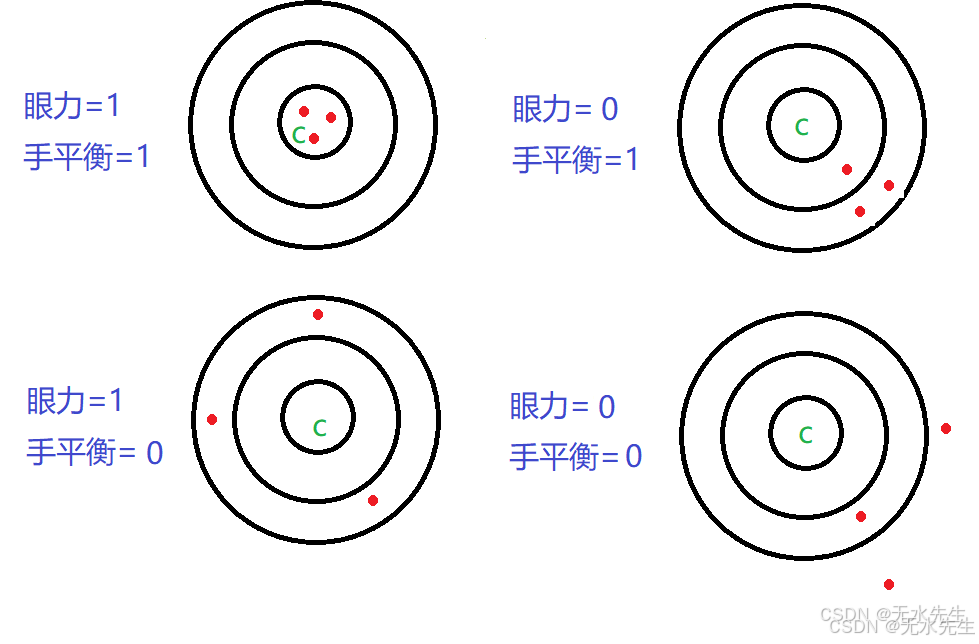
我们从上面例子解释“无偏”和“有偏”的关系。在以上打靶结果中,
<眼力=1,手平衡=1>和<眼力=1,手平衡=0>属于“无偏”
<眼力=0,手平衡=1>和<眼力=0,手平衡=0>属于“有偏”
为什么呢?
我们考虑打靶的重心值:
Xˉ=∑i=13Xi\bar{X}=\sum^{3}_{i=1}X_iXˉ=∑i=13Xi
当Xˉ\bar{X}Xˉ的极限等于把心c,那么就是无偏的,否则就是有偏的。
注意:有偏估计也不是没有意义的。只要能给出固定偏移,不难将无偏估计转化成无偏估计。
三、偏差和无偏差估计器
如果估计器u(X1,X2,…,Xn)u(X_1,X_2,\ldots,X_n)u(X1,X2,…,Xn)以下情况成立:
E[u(X1,X2,…,Xn)]=θE[u(X_1,X_2,\ldots,X_n)]=\thetaE[u(X1,X2,…,Xn)]=θ那么统计u(X1,X2,…,Xn)u(X_1,X_2,\ldots,X_n)u(X1,X2,…,Xn)是参数的无偏估计量θ\thetaθ。 否则,u(X1,X2,…,Xn)u(X_1,X_2,\ldots,X_n)u(X1,X2,…,Xn)是一个有偏估计θ\thetaθ。
3.1 贝努力变量p的无偏估计
如果XiX_iXi是具有参数的伯努利随机变量ppp, 那么:
p^=1n∑i=1nXi\hat{p}=\dfrac{1}{n}\sum\limits_{i=1}^nX_ip^=n1i=1∑nXi
是最大似然估计量(MLE)p^\hat{p}p^ 是p的无偏估计量.
证明:
回想一下,如果XiX_iXi是具有参数的伯努利随机变量ppp, 那么E(Xi)=pE(X_i)=pE(Xi)=p
。 这里对估计器求期望:
E(p^)=E(1n∑i=1nXi)=1n∑i=1nE(Xi)=1n∑i=1np=1n(np)=pE(\hat{p})=E\left(\dfrac{1}{n}\sum\limits_{i=1}^nX_i\right)=\dfrac{1}{n}\sum\limits_{i=1}^nE(X_i)=\dfrac{1}{n}\sum\limits_{i=1}^np=\dfrac{1}{n}(np)=pE(p^)=E(n1i=1∑nXi)=n1i=1∑nE(Xi)=n1i=1∑np=n1(np)=p
第一个等式成立,因为我们只是替换了p^\hat{p}p^及其定义。第二个等式根据线性组合的期望规则成立。第三个等式成立,因为E(Xi)=pE(X_i)=pE(Xi)=p。第四个等式成立,因为当你添加值p向上连加n次,你得到np。当然,最后一个等式是简单的代数。
总而言之,我们已经证明:E(p^)=pE(\hat {p})= pE(p^)=p
因此,最大似然估计量是p。
3.2 正态分布的无偏估计
如果XiX_iXi是具有均值的正态分布的随机变量,参数μ\muμ和方差σ2\sigma^2σ2的无偏估计是:
μ^=∑Xin=Xˉ\hat{\mu}=\dfrac{\sum X_i}{n}=\bar{X}μ^=n∑Xi=Xˉ
σ^2=∑(Xi−Xˉ)2n\hat{\sigma}^2=\dfrac{\sum(X_i-\bar{X})^2}{n}σ^2=n∑(Xi−Xˉ)2
下面用无偏性估计定义进行验证:
只要证明:E(Xi)=μE(X_i)=\muE(Xi)=μ和Var(Xi)=σ2\text{Var}(X_i)=\sigma^2Var(Xi)=σ2就可以。
E(Xˉ)=E(1n∑i=1nXi)=1n∑i=1nE(Xi)=1n∑i=1μ=1n(nμ)=μE(\bar{X})=E\left(\dfrac{1}{n}\sum\limits_{i=1}^nX_i\right)=\dfrac{1}{n}\sum\limits_{i=1}^nE(X_i)=\dfrac{1}{n}\sum\limits_{i=1}\mu=\dfrac{1}{n}(n\mu)=\muE(Xˉ)=E(n1i=1∑nXi)=n1i=1∑nE(Xi)=n1i=1∑μ=n1(nμ)=μ
第一个等式成立,因为我们只是用Xˉ\bar{X}Xˉ及其定义。同样,第二个相等性符合线性组合的期望规则。第三个相等性成立,因为E(Xi)=μE(X_i)=\muE(Xi)=μ.第四个相等性成立,因为当您将值μ\muμ累加n次倍,你会得到np。最后一个相等是简单代数。
总之,我们已经证明:E(Xˉ)=μE(\bar{X})=\muE(Xˉ)=μ
因此,最大似然估计量为μ\muμ是公正的.
下面我们证明σ^2=∑(Xi−Xˉ)2n\hat{\sigma}^2=\dfrac{\sum(X_i-\bar{X})^2}{n}σ^2=n∑(Xi−Xˉ)2也是公正无偏的。
首先回顾方差的基本定义:
Var(X)=E((X−E(X))2)=E(X2)−E(X)2Var(X)=E( (X-E(X))^2)=E(X^2)-E(X)^2Var(X)=E((X−E(X))2)=E(X2)−E(X)2
对于独立同分布的抽样样本(X1,X2,…,Xn)(X_1,X_2,\ldots,X_n)(X1,X2,…,Xn),每个随机变量数值特征是一样的,也就是说:
E(X1)=E(X2)=,…,E(Xn)=μE(X_1)=E(X_2)=,\ldots,E(X_n)=\muE(X1)=E(X2)=,…,E(Xn)=μ
Var(X)=Var(X1)=Var(X2)=,…,Var(Xn)=σ2Var(X)=Var(X_1)=Var(X_2)=,\ldots,Var(X_n)=\sigma^2Var(X)=Var(X1)=Var(X2)=,…,Var(Xn)=σ2
下面我们将给出证明
E(σ^2)=E(∑(Xi−Xˉ)2n)=∑E(Xi−Xˉ)2n=∑E(Xi2−2X2Xˉ+Xˉ2)n=∑[E(Xi2)−2E(XiXˉ)+E(Xˉ)2]n=∑[E(Xi2)−2E(Xi)Xˉ+(Xˉ)2)n=∑[E(Xi2)−Xˉ2]n=n[E(X2)−EXˉ2]n=E(X2)−EXˉ2=σ2E(\hat{\sigma}^2)=E(\dfrac{\sum(X_i-\bar{X})^2}{n})=\dfrac{\sum E(X_i-\bar{X})^2}{n}=\dfrac{\sum E(X_i^2-2X_2\bar{X}+\bar{X}^2)}{n}=\dfrac{\sum[ E(X_i^2)-2E(X_i\bar{X})+E(\bar{X})^2]}{n}=\dfrac{\sum[ E(X_i^2)-2E(X_i)\bar{X}+(\bar{X})^2)}{n}=\dfrac{\sum[ E(X_i^2)- \bar{X}^2]}{n}=\dfrac{n[ E(X^2)- E\bar{X}^2]}{n}= E(X^2)- E\bar{X}^2=\sigma^2E(σ^2)=E(n∑(Xi−Xˉ)2)=n∑E(Xi−Xˉ)2=n∑E(Xi2−2X2Xˉ+Xˉ2)=n∑[E(Xi2)−2E(XiXˉ)+E(Xˉ)2]=n∑[E(Xi2)−2E(Xi)Xˉ+(Xˉ)2)=n∑[E(Xi2)−Xˉ2]=nn[E(X2)−EXˉ2]=E(X2)−EXˉ2=σ2
第一个等号是等价代换,第二个等号E(期望)的线性等价性质。第三个等号。代数展开。第四个等号,期望线性恒等式。第五个等式,因为Xˉ\bar XXˉ不是随机变量,而XiX_iXi是随机变量,因此用E(cX)=cE(X)E(cX)=cE(X)E(cX)=cE(X)和E(Xˉ)=XˉE(\bar X)=\bar XE(Xˉ)=Xˉ简化;第六个等式,因为E(Xi)=E(X)E(X_i)=E(X)E(Xi)=E(X)这是因为两个随机变量的期望是一致的。第七个等式代数加和展开。第八等式,正态分布方差公式简化版。从而E(σ2^)=σ2E(\hat{\sigma^2})=\sigma^2E(σ2^)=σ2得证。
四、结论
这里需要首先肯定得是,有偏/无偏与误差偏差无关,不是说误差越大越有偏;一种可能是估计器误差很大,但他是无偏估计;另一种可能是估计器误差很小,但他是有偏估计。一个抽样有偏和无偏得判断措施就是对他求期望,该期望与整体得期望比较,发现有/无偏性。


















 1839
1839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











