






 本文介绍了一种名为AdderNet的新型神经网络,该网络用加法运算替代传统卷积神经网络(CNN)中的卷积计算,显著降低了计算成本和能耗。AdderNet通过采用l1范数距离度量代替卷积操作,实现了这一目标。实验结果显示,在CIFAR10和CIFAR100数据集上,AdderNet能够达到与ResNet20相当的精度,尽管存在一定的精度差距,但其在计算效率方面的优势不容忽视。
本文介绍了一种名为AdderNet的新型神经网络,该网络用加法运算替代传统卷积神经网络(CNN)中的卷积计算,显著降低了计算成本和能耗。AdderNet通过采用l1范数距离度量代替卷积操作,实现了这一目标。实验结果显示,在CIFAR10和CIFAR100数据集上,AdderNet能够达到与ResNet20相当的精度,尽管存在一定的精度差距,但其在计算效率方面的优势不容忽视。
论文地址:https://arxiv.org/abs/1912.13200v2
Abstract
作者用加法代替神经网络中的卷积计算,将传统的CNN转变成AdderNet,大大减少了计算成本、能耗等。具体的做法就是把卷积看作是距离度量的方式,用 l 1 l_1 l1范数来代替卷积。
Adder Networks
普通的卷积滤波器:
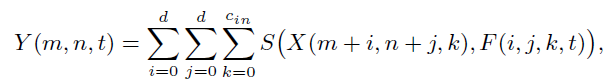
加法网络滤波器(利用
l
1
l_1
l1距离):
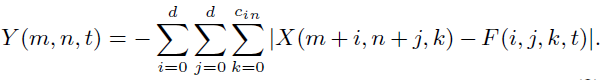
但是卷积滤波器输出可正可负,而加法滤波器恒为负数,因此需要通过batch normalization将输出归一化到合适的范围。
Optimization
反向传播进行梯度计算时,CNN的输出对滤波器的偏导为:
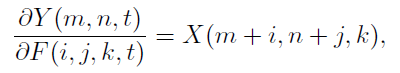
而加法网络:
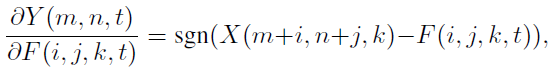
由于signSGD的优化方法几乎不会选择最陡的下降方向,而且随着维数增加效果更差,所以建议使用
l
2
l_2
l2范数的导数来更新:
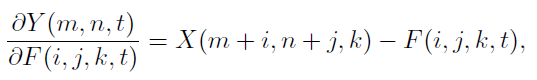
反向传播使用的是全精度的梯度,梯度的绝对值可能会大于1,这样会产生梯度爆炸,所以将梯度截断在[-1,1]。
输入特征的梯度为:
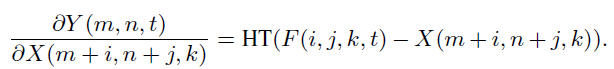
其中,HT是HardTanh函数:
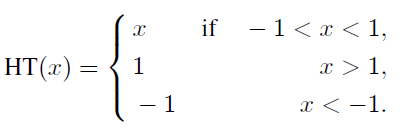
Experiment
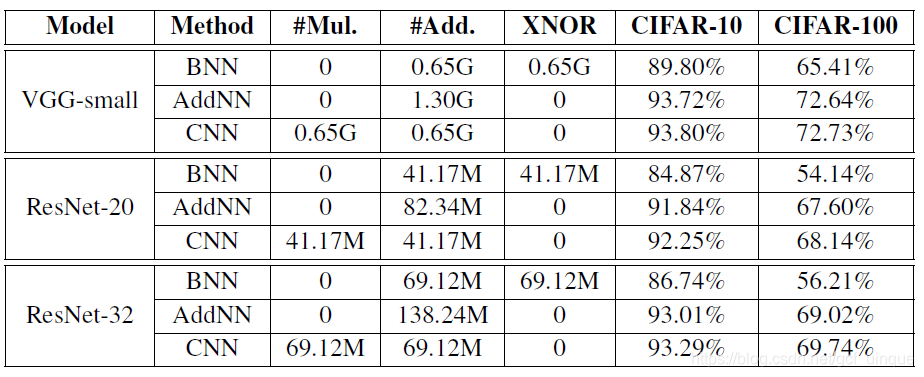
在cifar10和cifar100上的实验结果:
实验复现:
在cifar10上,resnet20的精度为92.46%,addernet精度为91.31%,其中addernet的精度和论文存在0.5%的差距。而且由于使用加法滤波器,cuda无法加速,训练的时间极其漫长。

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









