



论文地址:https://arxiv.org/abs/1908.09791v5
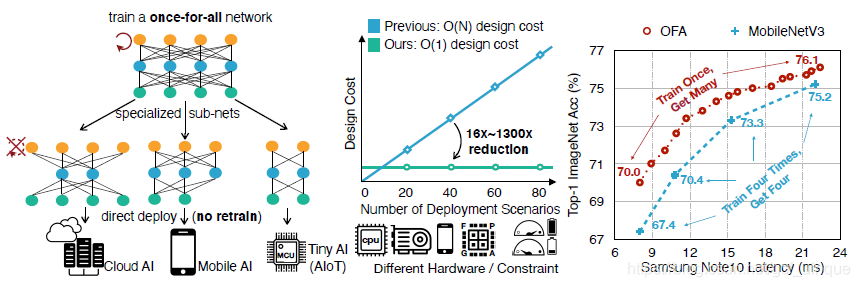
OFA网络主要的贡献就是只需要训练一次,就能得到大约2×10192 \times 10^{19}2×1019个网络,这些网络能部署在不同的场景,不需要针对不同场景训练不同的网络,因此与其他方法相比,部署成本从O(N)降为O(1),即部署场景增加,成本几乎不变,而且精度能达到当前SOTA水平甚至超过。
Method
OFA的总体优化目标为:
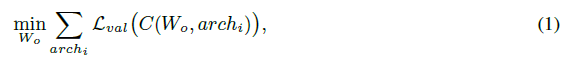
WoW_oWo是权重,archiarch_iarchi是结构配置,C(Wo,archi)C(W_o,arch_i)C(Wo,archi)就是从OFA网络的WoW_oWo中选择一部分构成结构为archiarch_iarchi的子网络。
为了使网络更灵活,作者从4个维度入手:深度(depth)、宽度(width)、核大小(kernel size)、分辨率(resolution)。这些都是灵活可变的。
| 弹性深度 | 网络层数{2,3,4} |
|---|
| 弹性宽度 | 通道数{3,4,6} |
|---|
| 弹性核大小 | 卷积核尺寸{3,5,7} |
|---|
| 弹性分辨率 | 输入图像尺寸区间[128, 224] ,stride=4 |
|---|
作者将模型划分为一个unit序列,每个unit包含不同数量的层数,每一层包含不同的通道数,每个通道使用不同的卷积核。对于5个unit,最多能有((3×3)2×(3×3)3×(3×3)4)5≈2×1019((3 \times 3)^2 \times (3 \times 3)^3 \times (3 \times 3)^4)^5 \approx 2 \times 10^{19}((3×3)2×(3×3)3×(3×3)4)5≈2×1019个子网络,并且每个网络的输入都有224−1284+1=25\frac{224-128}{4} +1 = 254224−128+1=25种不同的分辨率可供选择。
Training
Progressive Shrinking
因为OFA的子网络数量太多,普通的训练方法的成本过高,所以作者提出了渐进式收缩(Progressive Shrinking)方法。
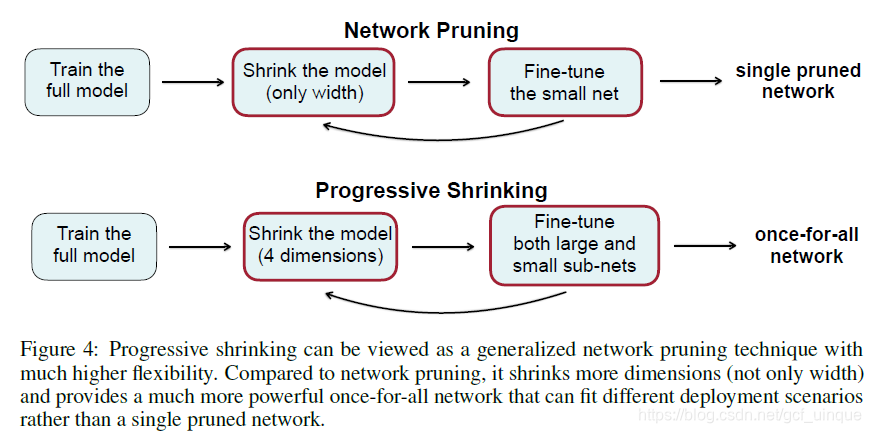
PS方法就是先训练大网络再训练小网络,如图3,先训练最大的网络(分辨率是可变的,其他三个都是最大的),然后逐步缩小kernel size、depth、width,小网络通过与大网络共享权重进行fine-tune,从而缩短训练时间。

PS与普通的剪枝区别如图4,整体来看二者还是很相似的,只是PS对4个维度进行收缩(实际上应该算3个),并且大、小网络均能进行fine-tune。
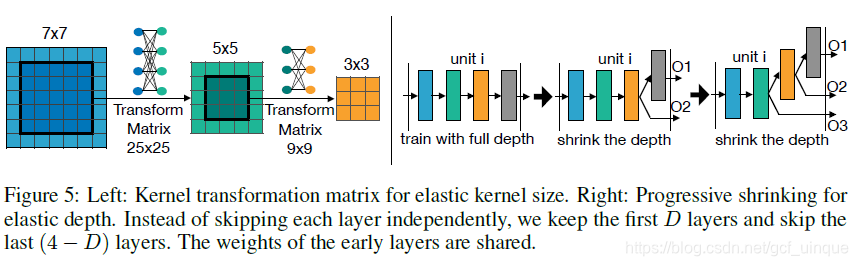
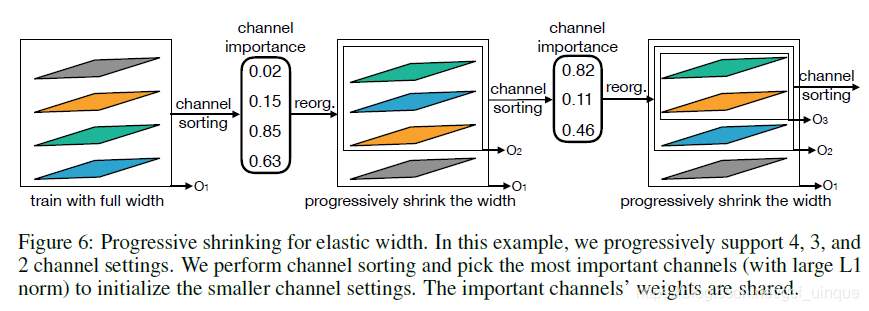
具体的细节如图5、6。
1. shrink the kernel size: 对于卷积核大小,可以将7×77 \times 77×7的卷积核的中心作为5×55 \times 55×5的卷积核。同理将5×55 \times 55×5的卷积核的中心作为3×33 \times 33×3的卷积核。为了避免共享核造成子网络性能下降,引入核变换矩阵,且和权重共享类似,不同层有不同的核变换矩阵,同一层的不同通道共享一个核变换矩阵,因此每一层只需25×25+9×9=70625 \times 25 + 9 \times 9 = 70625×25+9×9=706个额外的参数,可以忽略不记;
2. shrink the depth: 收缩depth时,保留前面D层,跳过最后一层。
3. shrink the width: 收缩width时,先训练最大宽度(6),然后计算每个channel的权重的L1范数,根据范数大小进行排序(从大到小,越大越重要),按顺序进行收缩。
Deployment
训练完模型后,就要把它部署到场景中,即搜索一个满足精度、延迟等约束的神经网络。因为OFA将模型训练和NAS解耦,所以这个阶段不需要训练成本。作者建立了neural-network-twins结构来预测精度和延迟。具体做法就是随机选取16K个子网络,测试了10K张从原始训练集抽样出来的图片,用来训练精度预测器,同时还建立了各种硬件的延迟查找表。最后利用基于neural-network-twins的进化算法进行搜索。
Experiments
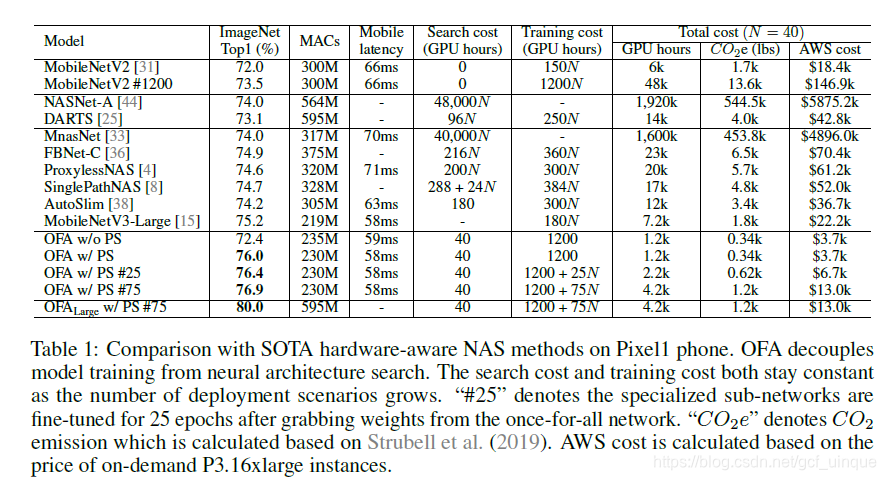
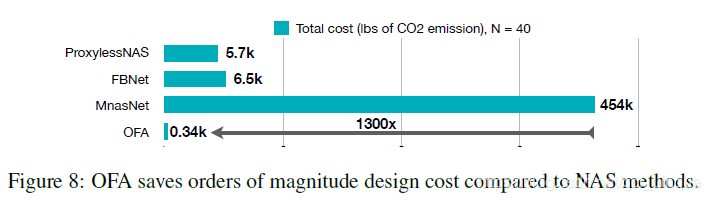
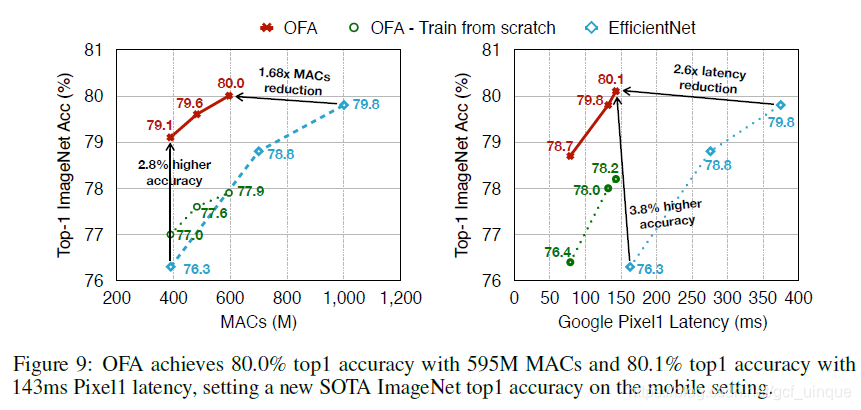
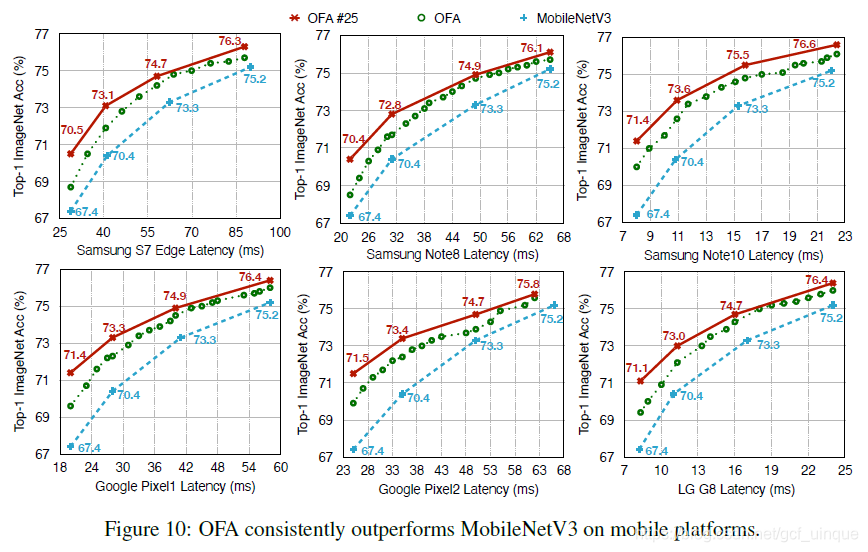
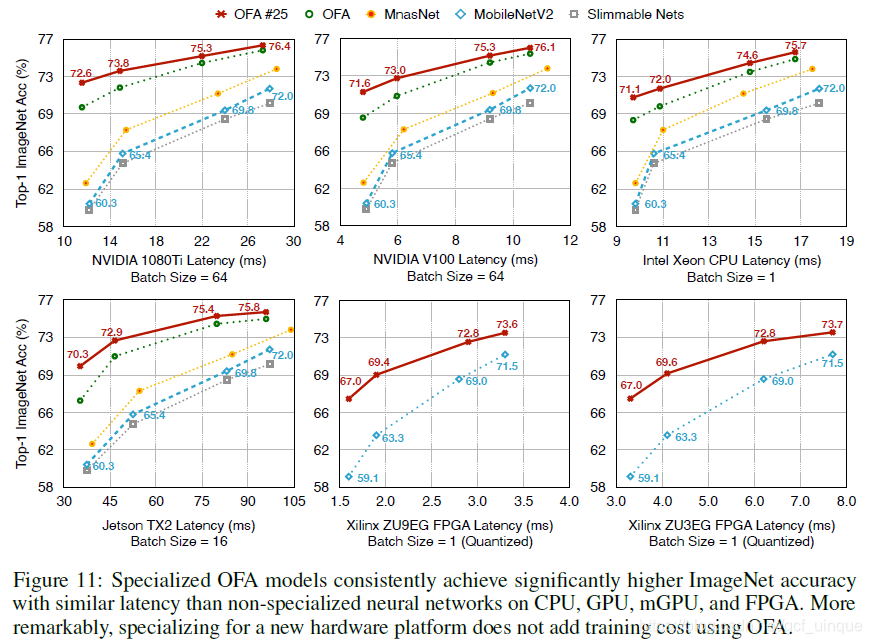
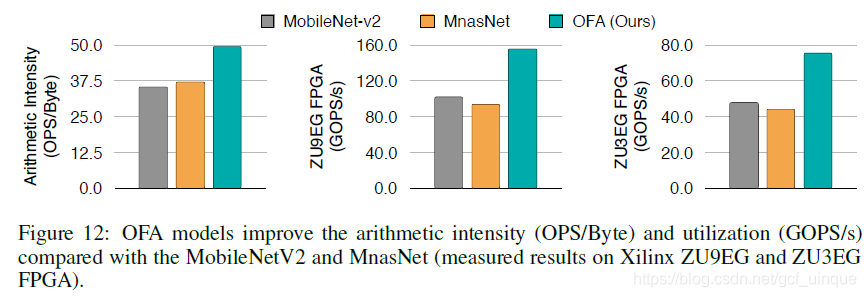

















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









