



目录
AdderNet作者团队:北京大学&华为诺亚方舟实验室等 发表在CVPR2020
论文链接:https://arxiv.org/abs/1912.13200v3
github开源链接:GitHub - huawei-noah/AdderNet: Code for paper " AdderNet: Do We Really Need Multiplications in Deep Learning?"
1.AdderNet是什么?
主要是以提供性能为目的提出的。
卷积神经网络中的卷积操作充满了大量的浮点值乘法运算,因此相比加法运算,乘法运算复杂度更高,加法网络(AdderNets)交换了深度神经网络中的大规模乘法,获得了更低的计算成本,以其能够便携的搭载在移动设备应用场景。
核心在于用L1距离代替欧式距离,即![]()
代替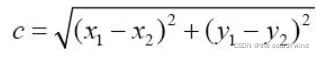 ,在加法器网络中,作者以滤波器与输入特征之间的L1范数距离作为输出响应,分析了这种新的相似性度量对神经网络优化的影响。为了获得更好的性能,通过研究全精度梯度开发一种特殊的反向传播方法。然后作者还提出了一种自适应学习率策略,根据每个神经元梯度的大小来增强加法网络的训练过程。
,在加法器网络中,作者以滤波器与输入特征之间的L1范数距离作为输出响应,分析了这种新的相似性度量对神经网络优化的影响。为了获得更好的性能,通过研究全精度梯度开发一种特殊的反向传播方法。然后作者还提出了一种自适应学习率策略,根据每个神经元梯度的大小来增强加法网络的训练过程。
L1范数和L2范数充当正则项以及损失函数的介绍:(40条消息) L1,L2,Lp,L∞范数,曼哈顿距离,欧式距离,切比雪夫距离,闵可夫斯基距离以及损失函数和正则项的应用_小莫の咕哒君-优快云博客_l无穷范数 https://blog.youkuaiyun.com/qq_44766883/article/details/111416264
https://blog.youkuaiyun.com/qq_44766883/article/details/111416264
(有一个切比雪夫距离的算法题可以空闲时刷一下,TJOI2013 松鼠聚会: 切比雪夫距离 - zjjws - 博客园 (cnblogs.com),我看着还蛮有趣的,emm)
AdderNet是属于神经网络优化的一块,此外相关工作还有Network Pruning和Knowledge Distillation
2.AdderNet主要做了什么?
AdderNet网络及优化
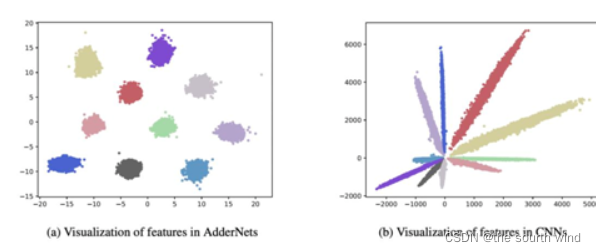
不同类别的CNN特征按其角度来划分,由于AdderNet使用L1范数来区分不同的类,因此AdderNet的特征倾向于聚集到不同的类中心。
对于CNN中的卷积运算,假定输入X,filter表示为F,卷积后输出的是二者的相似性度量
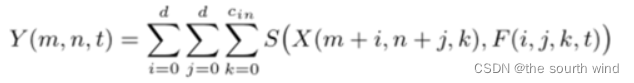
神经网络利用反向传播来计算滤波器中的梯度和随机梯度下降来更新参数。在CNN中,其输入特征Y相对于F的偏导数被计算为:
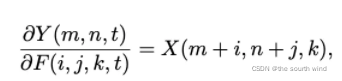
实际上二者的相似性度量可以有多种途径,但都涉及到大量的乘法运算,这就增加了计算开销,因此作者通过计算L1距离完成输入和filter之间的相似性度量。而L1距离仅涉及到两个向量差的绝对值,这样输出就变成了如下:

上式AdderNet计算偏导数(输入特征Y相对于滤波器F的偏导数计算)的公式:
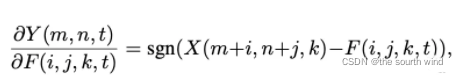
其中sgn代表符号函数,它让我们求得的梯度只能取三种值:-1,0,1。
由此进行优化的方法叫做符号SGD(signSGD)。但是,signSGD几乎永远不会沿着最陡的下降方向,并且方向性只会随着维数的增长而变差。因此要使用另一种形式的梯度:
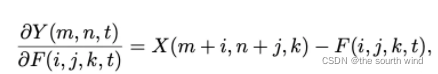
此外,如果使用full-precision gradient的更新方法,由于涉及到前层的梯度值很容易导致梯度爆炸,因此AdderNet还通过使用HardTanh将输出限定在【-1,1】范围内:
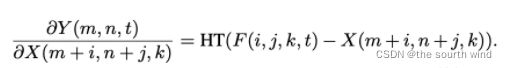
其中HT是HardTanh函数:
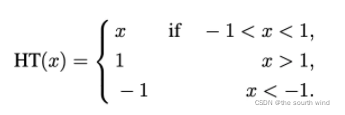
注意到使用互相关运算还是L1距离都可以完成相似性度量,但二者输出结果还是有一些差别的,通过卷积核完成输入特征图谱的加权和计算,结果可正可负。但adder filter输出的结果恒为负,为此作者引入了batch normalization将结果归一化到一定范围区间内从而保证传统CNN使用的激活函数在此依旧可以正常使用。虽然BN的引入也有乘法操作但计算复杂度已远低于常规卷积层。conv和BN的计算复杂度分别如下
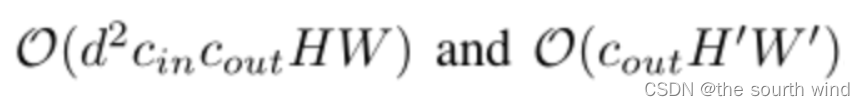
自适应学习率
在传统的CNN中,假设权重和输入特征是独立的,服从正态分布,输出的方差大致可以估计为:
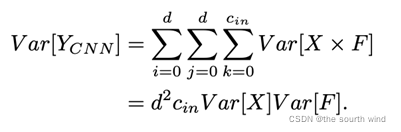
对于AdderNet,输出的方差可以近似为:
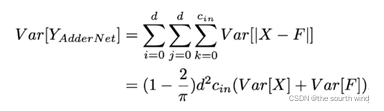
AdderNet的输出具有较大的方差,在更新时根据常规的链式法则会导致梯度比常规CNN更小,从而导致参数更新过慢,因此自然而然想到通过引入自适应学习率调整参数的更新learningrate组成。
![]()
包括神经网络的全局学习率和本地学习率,其中本地学习率表示为:
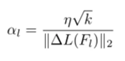
这样可以保证每层更新的幅度一致,最终AdderNet的训练过程表述为:

3.AdderNet效果怎么样?
AdderNet的作者使用的实验平台和框架是: v100 Pytorch
作者在MNIST、CIFAR和ImageNet数据集上验证了AdderNet的有效性,随后进行了消融实验及以及对提取的特征进行可视化。
图片分类结果:
CIFAR-10和CIFAR-100 datasets分类结果:
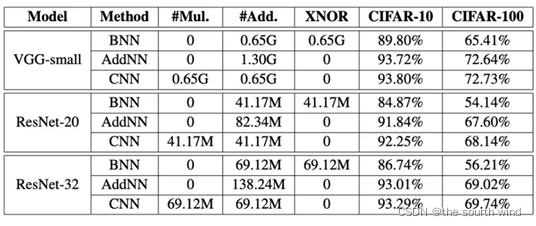
BNN是二值神经网络,从上面我们能看到AddNN识别精度相比BNN提高了很多,但是与CNN仍然有点差距。
在ImageNet的分类结果:
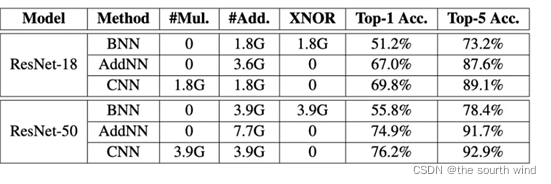
个人感觉作者这样实验不太合理,AddNN主要是为了提高网络的性能,但是作者的实验只强调了识别精度,并没有推理和训练速度上的对比,不免让人感到文不对题。作者在公布的代码项目主页中提到他是用加法过滤器实现的,因此推理速度比较慢,需要用CUDA编写才能提高速度,这与作者希望提高神经网络运算速度的初衷还有一段距离。其实也可能是现在各种专用AI芯片、FPGA都对深度学习任务做了优化,算浮点乘法并不一定与加法小号资源相差太大。
华为诺亚在21年提出了AdderNet的专用和通用硬件加速器,并在FPGA上部署了量化的ADDerNet,与CNN相比速度、功耗、占用的硬件资源都得到了提升,详情可以看以下这个网址:
华为诺亚提出:AdderNet及其极简硬件设计 - 知乎 (zhihu.com)
特征提取验证
AdderNet使用L1距离来度量输入与filter之间的关系而不是使用卷积的互相关,因此需要探究一些AdderNet与CNN特征空间上的差异。因此就在MNIST数据集上搭建了LeNet++:6conv+1fc,每层神经元数目依次为:32,32,64,64,128,128,2。同样其中的Conv层用add filter替换可视化结果如图a所示,CNN的可视化为图b,相似度通过cosin计算得到,因此分类通过角度进行的分类。从AdderNet的可视化结果中可以看到AdderNet不同种类的聚类中心不同,这也验证了AdderNet具有同CNN相似的辨别能力。从而可以看出虽然AdderNet和CNN用的度量矩阵不同,但都具有特征提取的能力。
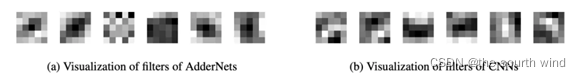
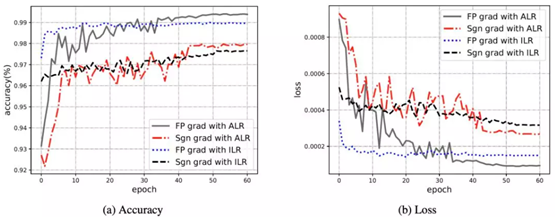
addernet使用不同优化方案的学习曲线
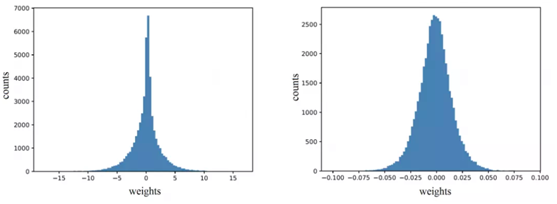
对LeNet-5-BN的第三层进行可视化,AdderNet权重更接近Laplace分布,CNN的权重近似高斯分布,分别对应L1-norm和L2-norm。


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









