




FPGA教程系列-Vivado Aurora 8B/10B IP核设置
Aurora 8B/10B 是 Xilinx 开发的一种轻量级、链路层的高速串行通信协议。它比单纯的 GT(Transceiver)收发器更高级(因为它帮你处理了对齐、绑定、甚至流控),但比以太网或 PCIe 更简单、延迟更低。
手册看的脑袋疼,还是实操一下看看如何使用吧,可能很多部分都是官方写好的,不需要自己去弄,而实际使用可能就是修改一些参数就行了。

1. Physical Layer (物理层设置)
这一部分直接决定了底层的硬件连接和电气特性,必须严格按照板卡设计和对端设备来配置。
Lane Width (Bytes) [通道宽度]: 2 或 4。决定了用户逻辑接口(AXI-Stream)的数据位宽,也直接影响 user_clk 的频率。
- 2 Bytes:AXI 接口位宽为 16-bit。
user_clk = 线速率 / 20。 - 4 Bytes:AXI 接口位宽为 32-bit。
user_clk = 线速率 / 40。
如果线速率很高(比如 > 5Gbps),建议选 4 字节,这样可以让 FPGA 内部逻辑时钟(user_clk)跑慢一点,更容易满足时序。如果是 3.125G 这种中低速,选 2 字节即可。
Line Rate (Gbps) [线速率] :光纤或铜线上实际跑的比特率。
取决于 SFP 模块能力、PCB 走线质量以及对端设备的速度。3.125 Gbps,是 Aurora 的一个经典速率(也是 XAUI 的标准速率)。
GT Refclk (MHz) [GT 参考时钟] :FPGA 外部输入的差分参考时钟频率。
必须与你 PCB 板子上连接到 FPGA GT Bank 的那个晶振频率完全一致。如果填错了,PLL 锁不住,整个核都起不来。
INIT clk (MHz) [初始化时钟] :用于驱动复位逻辑和初始化状态机的辅助时钟。在上电初始化阶段,可以使用该时钟来驱动一些逻辑。默认值:50Mhz。
通常给 50MHz 到 100MHz 之间的稳定时钟即可。这个时钟对抖动要求不高,可以用普通的逻辑时钟。
DRP Clk (in MHz) [动态重配置时钟] :用于驱动 DRP(Dynamic Reconfiguration Port)接口的时钟,允许你在运行时修改 GT 的参数。通常和 INIT clk 共用一个时钟源。动态重配置,一般没用,默认值:50Mhz(通常一个内部模块需要进行配置,使用两种方法:端口控制和配置参数控制。一个常见的应用就是线速率切换。这时候就需要利用DRP端口来调整部分参数的值,然后复位GTX,使GTX工作在不同的线速率下。)。
Tip:关于时钟
上面这三个时钟,是IP核工作所需要的时钟,也是我们需要提供给IP核的。此外,还有一个时钟是IP核提供给我们的:user_clk。这个时钟,是IP核根据设置的线速率及Lane的位宽计算出来的用户时钟,用户需要传输的数据必须是该时钟域下的数据,否则会存在亚稳态风险。
2. Link Layer (链路层设置)
这一部分决定了数据如何打包、如何握手。通信双方(TX 和 RX)的配置必须完全一致。
Dataflow Mode [数据流模式]:
- Duplex (双工) :最常用,同时收发。
- TX-only / RX-only (单工) :只发或只收。
- Simplex (单工) :类似单工,但有特殊的边带信号处理。
Interface [用户接口类型] —— ⭐️ 非常重要
Framing (帧模式) :
- 有“包”的概念。AXI 接口上有
tlast信号,用来指示一个数据包的结束。 - 发送类似以太网包、命令包等非连续、有边界的数据。Aurora 会自动处理两帧之间的空闲填充。
Streaming (流模式) :
- 特点:像一根水管,没有“包”的概念,也没有
tlast信号。数据源源不断。 - 适用:发送 ADC 采样数据、视频流等连续数据。传输效率最高,因为没有帧头帧尾的开销。
Flow Control [流控]
- None:不使用流控(最常用,也最简单)。
- UFC (User Flow Control) :用户发命令来插队。
- NFC (Native Flow Control) :核心自动根据接收端缓冲区的满/空状态,给发送端发暂停信号(反压)。
初学者建议选 None。如果你需要防止接收端 FIFO 溢出,可以选 NFC。
Back Channel [回传通道]
-
Sidebands:通常用于单工模式,利用额外的 GPIO 线来告诉发送端“我准备好了”。在双工模式下通常不需要太关注这个。
-
Scrambler/Descrambler [加扰/解扰]
在发送前把数据打散(伪随机化),接收后还原。避免数据中出现长时间的连 0 或连 1,减少电磁干扰 (EMI),有利于时钟恢复。
-
Little Endian Support [小端序支持]
决定多字节数据的传输顺序。Aurora 默认是大端序(网络字节序)。除非你的处理器是强小端序且你不想在软件里倒腾字节,否则保持默认(不勾选)。小段模式对应[31:0]这种书写习惯,大端模式对应的是[0:31]这种书写习惯
3. Error Detection (错误检测)
CRC [循环冗余校验]: 在每一帧数据后面自动加一个校验码。
如果选了 Framing 模式,建议勾选。这样接收端收到数据时,如果发现 CRC 不对,会报错,保证数据完整性。如果是 Streaming 模式,通常不加 CRC。
4. Debug and Control (调试与控制)
Vivado Lab Tools
在 IP 核里自动插入 ILA(逻辑分析仪)。
调试阶段建议勾选。它会把 Aurora 的状态机、lane_up、channel_up 等关键信号抓出来,如果不通,你能看到卡在哪一步。量产时关掉以节省资源。
配置总结 & 避坑指南:
- 时钟计算:
按照图中的配置:3.125 Gbps / 2 Bytes (16 bits) / 10 (8B/10B编码效率) = 156.25 MHz。
user_clk 是 156.25 MHz。所有 AXI 接口逻辑(读写 FIFO、状态机)都必须在这个时钟频率下工作。 - 两端一致性:
FPGA A 和 FPGA B 通信,它们的 Line Rate、Lane Width、Scrambler、Interface (Framing/Streaming) 必须一模一样,否则channel_up永远起不来。 - Refclk 必须准:
如果板子上的晶振是 156.25MHz,这里就必须填 156.25,不能填 125。 - 复位顺序:
Aurora 也是基于 GT 的,对复位非常敏感。通常建议使用 IP 核自带的reset_pb (信号) 或者按照官方 Example Design 的复位序列来操作。上电后,先gt_reset,再reset。
第二页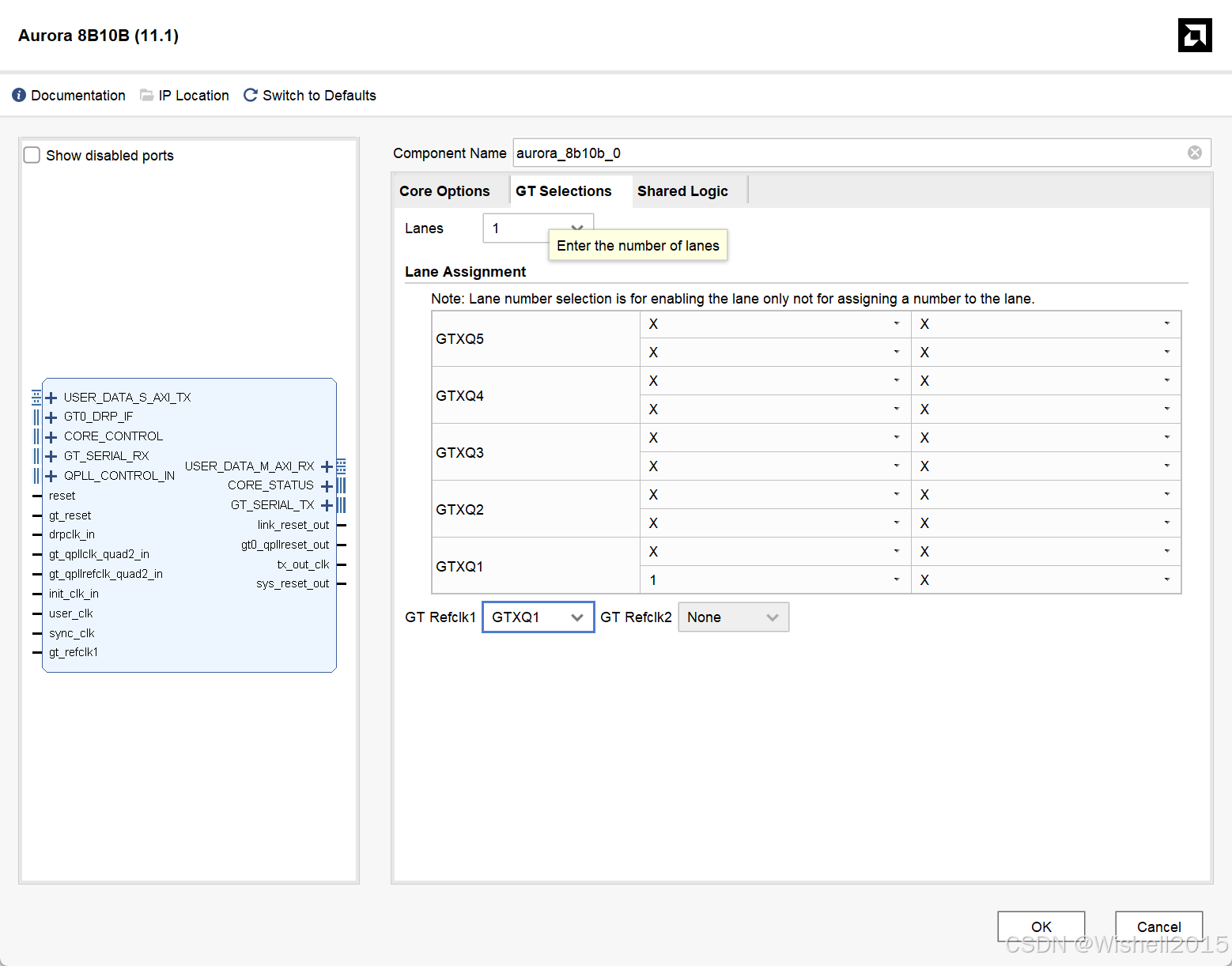
如果说上一页 “Core Options” 决定了“我们要传多快、传什么格式”,那么这一页则是决定 “这套协议要在 FPGA 的哪几根物理引脚上跑” 。
这是一个纯物理层的配置界面,必须结合 PCB 原理图 和 FPGA 芯片手册 来设置。
1. Lanes (通道数量)
Aurora 链路包含几条物理通道。
如果需要更高的带宽,可以将多条 Lane 绑定在一起(Bonding)。例如选 4,那么带宽就是单条 Lane 的 4 倍,且 Aurora 会自动处理通道间的对齐。
必须与原理图一致:如果你板子上只画了 1 对线连到光模块,这里就只能选 1。
2. Lane Assignment (通道分配表)
这是最容易晕的地方。这个表格代表了 FPGA 内部 GT (Gigabit Transceiver) 资源的物理位置分布。
-
结构解析:
-
左侧列 (GTXQ1, GTXQ2…) :代表 Quad。Xilinx 的高速收发器是每 4 个一组,称为一个 Quad。
-
GTXQ1通常指物理位置最靠下的那个 Quad(或者编号最小的)。
-
-
右侧网格:代表每个 Quad 里的 4 个具体收发器通道 (Channel 0 - Channel 3)。
-
下拉菜单 (X 或 数字) :
- X:表示这个物理通道不被当前的 Aurora 核使用。
- 1, 2, 3… :表示将 Aurora 的第几条逻辑通道映射到这个物理位置。
-
-
如何设置(关键步骤) :
- 打开原理图:查看你的 SFP 光口或 SMA 接口连接到了 FPGA 的哪个 Bank,哪对引脚(例如
MGTHTXP_115)。 - 查找映射:去查 Xilinx 的封装文件(Package File)或在 Vivado 的 “I/O Planning” 视图里看,确定那对引脚属于哪个 Quad 以及该 Quad 里的第几个 Channel(例如 X0Y0, X0Y1)。
- 在表中勾选:找到对应的位置,选上编号。
- 注意:这里的图形化界面只是一个生成网表的向导。最稳妥的做法是这里大概选对 Quad,然后在 XDC 约束文件 中通过
set_property LOC GTXE2_CHANNEL_X0Y0 [get_cells ...]来进行精确的物理约束。
- 打开原理图:查看你的 SFP 光口或 SMA 接口连接到了 FPGA 的哪个 Bank,哪对引脚(例如
3. GT Refclk1 / GT Refclk2 (参考时钟选择)
GT 收发器需要一个非常高质量的差分参考时钟(MGTREFCLK)才能工作。决定 Aurora 核使用板子上的哪一个差分晶振输入作为参考时钟。
如何设置:
- 看原理图:你的 125MHz(或 156.25MHz)差分晶振连接到了 FPGA 的哪两个引脚?(例如
MGTREFCLK0P_115 /MGTREFCLK0N_115)。 - 确认 Quad:确定这两个引脚属于哪个 Quad。
- 选择:在下拉菜单中选择对应的 Quad。
重要规则(时钟路由) :通常建议参考时钟和你的数据通道在同一个 Quad,或者在相邻的 Quad(North/South)。如果距离太远,时钟抖动会变大,Vivado 可能会报错。
避坑提示:
如果你实在搞不清具体的物理坐标(X0Y?, X0Y?),可以在这里先随便选一个(比如都选在 Q1),生成 IP。但是在写 .xdc 约束文件 时,必须严格加上 package_pin 约束和 LOC 约束,Vivado 会以 XDC 文件为准,强行把逻辑“拽”到正确的物理引脚上。如果这里选的和 XDC 冲突太大(比如跨了太多 Bank 导致时钟够不着),Implementation 阶段会报错。
第三页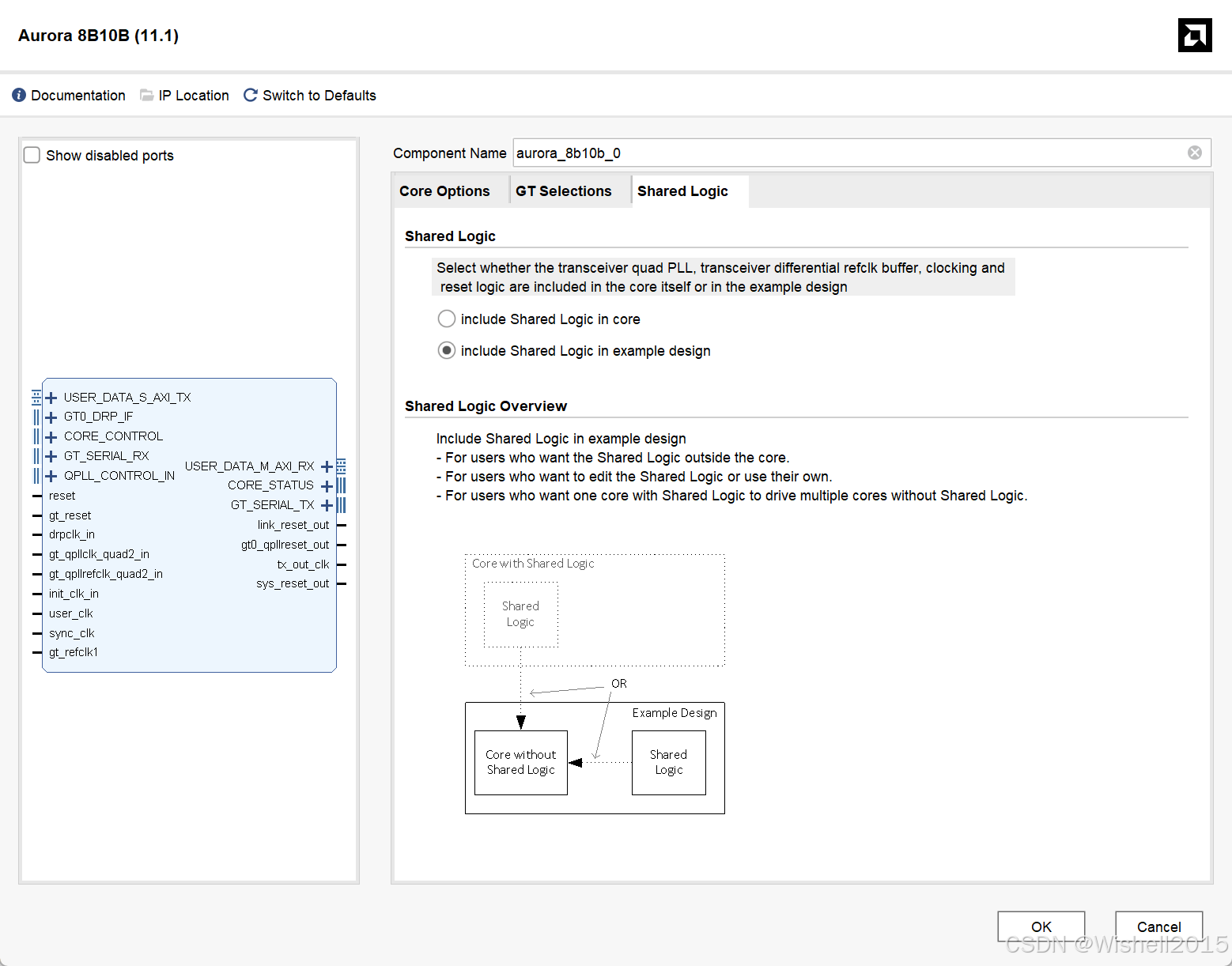
简单来说,这一页是在问: “在这个 IP 核内部,我要不要自带时钟发生器(PLL)和差分时钟缓冲器(IBUFDS)?”
什么是“Shared Logic”?
在 Xilinx FPGA 的高速收发器(GT)架构中,4 个通道(Channel)组成一个 Quad。这 4 个通道共享一些公共资源,最主要的就是 PLL(锁相环) 和 参考时钟输入缓冲(Diff Refclk Buffer) 。
- PLL:负责将参考时钟倍频,生成高速串行时钟。
- Buffer:负责将板子上的差分时钟引入芯片内部。
1. Include Shared Logic in core (包含在核内) —— “我是房东”
这个 IP 核会把 PLL、参考时钟缓冲、复位逻辑全部包含在自己肚子里。它是全功能、自给自足的。生成的 IP 核对外接口比较简单,直接接板级引脚(refclk)即可。
什么时候选:
- 工程里 只有一个 Aurora 核。
- 或者,在一个 Quad 里有多个 Aurora 核,这是第一个(主核)。它负责产生时钟,分给别人用。
2. Include Shared Logic in example design (包含在示例工程中/核外) —— “我是租客”
这个 IP 核内部 不包含 PLL 和时钟缓冲。它是一个“空壳”或“从核”。它必须依赖外部送进来的 PLL 时钟信号才能工作。生成的 IP 核会多出一堆输入端口(如 gt_pll_clk、gt_refclk_out 等),你需要把别的核产生的时钟连进去。
为什么叫“在示例工程中” :
如果你生成了 Example Design,Vivado 会把那些公共逻辑(PLL等)放在 IP 核外面的顶层文件中。这样方便你修改或者将其去驱动其他的 IP 核。
什么时候选:
- 多核复用:当你在同一个 Quad 里放了第 2、3、4 个 Aurora 核时。因为 PLL 只有一个,已经被第 1 个核(房东)占用了,剩下的核(租客)只能借用第 1 个核输出的时钟。
- 高级共享:当你有一个以太网核和一个 Aurora 核共用同一个 Quad 的 PLL 时。
Core with Shared Logic:
虚线框是 IP 核的边界。可以看到 Shared Logic(PLL 等)是在虚线框里面的。独立,但也独占资源。
Example Design:
虚线框是 IP 核的边界。可以看到 Core without Shared Logic 在里面,而 Shared Logic 被挪到了外面(Example Design 层级)。
特点:
- For users who want to edit… :如果你想自己手写 PLL 的复位逻辑,选这个。
- Drive multiple cores… :这是最常用的场景。外部的 Shared Logic 产生一次时钟,箭头指向
Core without Shared Logic(也就是当前这个 IP),同时还可以引出箭头去驱动其他的 IP 核。
场景 A:最简单的情况(新手推荐)
- 情况:你的设计里只需要 1 个 Aurora 接口,或者虽然有多个接口但它们分布在完全不同的 Quad 里(比如一个在 Bank 115,一个在 Bank 117)。
- 设置:选择
Include Shared Logic in core。 - 理由:最省事,不需要处理复杂的时钟互连,开箱即用。
场景 B:同一个 Quad 里有多个通道
-
情况:你的板子上光口是 4 路的(QSFP),你想跑 4 个独立的 Aurora 单工/双工链路,它们都在同一个 Quad 里。
-
设置:
- 第 1 个 IP 核:选择
Include Shared Logic in core。(它是 Master,负责开启 PLL)。 - 第 2、3、4 个 IP 核:选择
Include Shared Logic in example design。(它们是 Slave)。 - 连线:在顶层 Verilog 中,把第 1 个核输出的
gt_pll_out等时钟信号,连到后面 3 个核的对应输入端口上。
- 第 1 个 IP 核:选择
场景 C:你想完全掌控时钟
- 情况:你有非常复杂的时钟需求,或者你想在顶层自己实例化
IBUFDS_GTE 和GT_COMMON原语。 - 设置:选择
Include Shared Logic in example design。这样 IP 核就是纯净的数据通路,时钟全靠你喂。

















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









