<think>我们面对的是类似这样的行:{1,0xE0,{0x00}},而用户希望只保留像{1,0x80,{0x03}}这种格式的数据,也就是第二项是0x80,第三项是0x03这样的特定值。但是用户在上一个问题中说的是“只保留0x80,0x03这样类似的”,而现在在VSCode中操作,并且给出了具体格式:{1,0x80,{0x03}}。因此,我们实际上是要筛选出第二项为0x80,第三项为0x03(或者可能是任意值?)的行?但是用户举例是0x80和0x03,所以可能是特定的值,也可能是任意值?需要澄清。用户在上一次的问题描述是:“只保留0x80,0x03这样类似的”,这里的“类似”可能指格式,也可能指特定的值。但结合本次问题,用户给出了一个具体的格式{1,0x80,{0x03}},并且要求使用正则表达式在VSCode中操作。现在我们来分析:用户提供的数据样例中,每行都是由花括号括起来的三个字段,第一个字段是数字(例如1),第二个字段是十六进制数(例如0xE0),第三个字段是由花括号括起来的十六进制数(例如{0x00})。用户希望保留的行可能是:情况1:第二个字段是0x80,第三个字段是任意值(例如{0x03}、{0x01}等)情况2:第二个字段是0x80,且第三个字段是0x03(特定值)但是用户在上一次问题中说的是“类似0x80,0x03”,可能是指第二个字段是0x80,第三个字段是任意值的行?或者也可能是任意行中只要出现了0x80,0x03这样的组合?但是注意,在数据中,0x80和0x03分别出现在不同的字段。根据用户本次的举例:{1,0x80,{0x03}},以及上次的示例数据中有:{1,0x80,{0x03}}用户要求保留这种格式,那么我们要明确:实际需求:保留所有第二个字段为0x80的行?还是保留第二个字段为0x80且第三个字段为0x03的行?由于用户上次的问题描述是“只保留0x80,0x03这样类似的”,而0x80和0x03分别出现在第二和第三字段,且第三字段是花括号括起来的。所以可能是保留第二字段是0x80,第三字段是{0x03}(注意0x03是示例,可能是任意值)的行。因此,我们按照保留第二字段为0x80的行来设计正则表达式。那么我们可以这样匹配:每行的格式:以{开头,然后是数字(第一个字段),逗号,然后是0x80(注意0x80是字面字符串),逗号,然后是花括号括起来的任意十六进制数(或者任意内容?),最后以}结尾。具体正则表达式为:^\{1,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\},?$但是,观察用户数据,第一个字段并不都是1,还有可能是其他数字?但是在上次的数据中,第一个字段都是1。如果都是1,我们可以固定为1;如果不是,我们可以用\d+来匹配。另外,用户的数据中,可能有空格,也可能没有,所以需要允许空格。因此,更通用的正则表达式:^\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$解释:^:行首\{:匹配左花括号\s*:0个或多个空白字符(空格或制表符)\d+:一个或多个数字(第一个字段)\s*,\s*:逗号前后可能有空白0x80:字面字符串,第二个字段固定为0x80\s*,\s*:逗号前后可能有空白\{:左花括号(第三个字段的开始)0x[0-9A-Fa-f]{2}:0x后跟两个十六进制数字\}:右花括号(第三个字段的结束)\s*:后面可能有空白},?:最后是右花括号,可能后面有逗号(因为有时候行末可能有逗号,比如在数组中)$:行尾注意:在VSCode中,我们可以使用查找功能,然后使用正则表达式来查找匹配的行,然后手动删除不匹配的行。但是VSCode的查找不能直接删除不匹配的行,所以我们可以使用“查找所有匹配项”然后选择这些行,或者使用替换功能将不匹配的行替换为空(删除)。然而,用户希望“保留”这些行,也就是删除其他行。在VSCode中,我们可以用正则表达式查找所有不匹配的行,然后删除这些行。步骤:1.打开替换功能(Ctrl+H)2.在查找框中输入正则表达式,注意选择“正则表达式”选项(Alt+R)3.因为我们想保留匹配的行,删除不匹配的行,所以我们可以做:查找:^(?!.*\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$替换为空但是注意:这个正则表达式是负向零宽断言,比较复杂。我们可以分两步:先标记所有匹配的行,然后删除未标记的行?但VSCode没有标记功能。另一种思路:我们可以查找所有行,然后利用VSCode的多选功能,将匹配的行复制到一个新文件中。步骤(利用查找功能选中所有匹配行):1.打开查找(Ctrl+F)2.输入匹配目标行的正则表达式:`^\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$`3.勾选“正则表达式”4.点击“查找全部”(在查找框右边的小箭头里)5.这样所有匹配的行都会被选中6.然后复制这些行,粘贴到新文件。但是,如果用户想直接在原文件中删除不匹配的行,我们可以使用替换功能,将不匹配的行替换为空行,然后删除空行?或者直接删除不匹配的行。删除不匹配行的正则替换:查找:^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$\n?替换:空注意:这个正则表达式会匹配整行,并且包括换行符,然后替换为空,即删除。但是,这个正则表达式中的负向零宽断言可能比较慢,特别是文件很大时。因此,我们也可以分两步:第一步:将匹配的行前面加上一个特殊标记(比如加一个特定的字符串)第二步:删除所有没有这个特殊标记的行第三步:去掉特殊标记但这样步骤多,且需要修改原文件。考虑到用户数据量可能不大,我们可以使用负向零宽断言。替换步骤:1.Ctrl+H打开替换2.查找:^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$\n?3.替换:留空4.选择“使用正则表达式”5.全部替换注意:这个正则表达式会匹配所有不符合我们要求的行(也就是不包含第二字段为0x80的行),然后删除。但是,这个正则表达式可能会因为文件结尾没有换行符而遗漏最后一行。因此,我们调整一下,不匹配换行符,而是匹配行内容,然后手动处理换行。另外,注意第三个字段的十六进制数匹配:0x[0-9A-Fa-f]{2},我们写为`0x[0-9A-F]{2}`(不区分大小写,VSCode正则表达式默认区分大小写,所以我们用[0-9A-Fa-f]或者打开不区分大小写选项?)在VSCode中,我们可以用(?i)来指定不区分大小写,但是这里我们直接写[0-9A-Fa-f]即可。由于用户可能的数据格式变化,比如第一个字段可能不是1,而是其他数字,所以我们的正则中用了\d+。另外,注意第三个字段内可能有空格?用户数据中没有空格,所以我们不考虑。但是,如果用户的数据中,有的行末尾有逗号,有的没有,我们在正则中允许了逗号(,?),所以可以匹配两种情况。现在,我们给出VSCode中直接删除不匹配行的正则替换表达式:查找:^(?!\s*\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$).+$\n?替换:空注意:我们加上了\s*允许匹配项前后有空格。但是,这个正则表达式在VSCode中可能会因为多行匹配问题而无法正常工作。我们尝试简化:我们只匹配整行,而不匹配换行符,然后用替换操作删除整行(包括换行符)。另外,考虑到行尾可能有换行符,我们可以在替换时删除整行(包括换行符):查找:(?:.*)(?<!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?)\n这样写更复杂。另一种方案:我们匹配每一行,如果匹配我们的目标格式,我们原样保留;否则替换为空行,然后删除空行。但是这样需要两步。但是,在VSCode中,我们可以用自定义代码进行扩展处理,但用户要求用正则表达式快捷操作。因此,我建议使用第一种方案:先查找匹配的行,然后复制到一个新文件。操作步骤(不修改原文件,保留目标行到新文件):1.打开文件,按Ctrl+F打开查找2.输入正则表达式:`^\s*\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$`3.勾选“正则表达式”4.点击“查找全部”(在查找框右边的箭头里)5.此时所有匹配行都被选中6.按Alt+Enter(或者右键单击编辑器,选择“选择所有匹配项”)7.按Ctrl+C复制8.新建一个文件,按Ctrl+V粘贴操作步骤(直接删除不匹配行):1.按Ctrl+H打开替换2.查找:`^(?=.*)(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$\n?`或者:`^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$\n?`3.替换:留空4.点击“使用正则表达式”5.点击“全部替换”注意:这个正则表达式在文件最后一行没有换行符时可能会遗漏最后一行不匹配的行。因此,我们可以分两次处理:先处理最后一行,或者用其他方式确保最后一行被包含。如果最后一行不匹配且没有换行符,我们可以修改正则表达式:查找:(^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$\n?)|(^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?$).+$)这个可以匹配两种情况:有换行符的行和没有换行符的最后一行。但是这样写比较复杂。如果文件不大,可以手动处理最后一行。因此,我们给一个比较鲁棒的替换表达式:查找:(^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$).+$(\n)?)|(\n(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$).+$)这个表达式可以处理换行符在行前和行后的情况。但这样过于复杂,可能难以调试。我建议使用一个简单的办法:在替换前,确保文件最后有一个换行符(如果没有,在文件末尾加一个,然后保存,再操作)。然后再使用:查找:^(?!\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$).+$\n?替换:(空)这样操作后,再删掉最后添加的换行符(如果有的话)。所以,为了安全起见,我们采用复制目标行到新文件的方法,这样不会破坏原文件。总结:在VSCode中,我们可以通过查找所有匹配行,然后复制粘贴到新文件的方式实现。如果用户坚持在原文件上操作,请使用替换功能,但务必在操作前备份文件。另外,如果用户的数据在数组或列表中,每行后面有逗号,我们的正则中已经包含了逗号(,?)所以可以匹配。下面是一个完整的示例:假设用户的数据如下:{1,0xE0,{0x00}},{1,0xE1,{0x93}},{1,0x80,{0x03}},{1,0xE0,{0x00}},{1,0x70,{0x10}},{1,0x71,{0x13}},{1,0x72,{0x06}},{1,0x80,{0x03}},{1,0xE0,{0x04}},{1,0x2D,{0x03}},{1,0xE0,{0x01}},{1,0x00,{0x00}},我们只保留第二字段为0x80的行,即:{1,0x80,{0x03}},{1,0x80,{0x03}},在VSCode中,我们可以使用查找:正则表达式:`^\s*\{\s*1\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$`这里第一个字段我们写死了1,如果可能是其他数字,改为`\d+`如果第一个字段固定为1,那么我们可以简化,写1即可。否则,用\d+。因此,在查找框中输入:`^\s*\{\s*\d+\s*,\s*0x80\s*,\s*\{0x[0-9A-Fa-f]{2}\}\s*\},?\s*$`然后执行“在选定内容中查找”,默认是整个文件,找到两行,然后复制即可。最后,我们为用户生成几个相关问题:§§相关问题§§1.如何只保留满足多个条件的行,例如第二项是0x80且第三项是0x03?2.在VSCode中如何同时筛选多种不同格式的行?3.如何将筛选出来的数据保存为新文件而不修改原文件?</think>
在VSCode中高效筛选`{1,0x80,{0x03}}`格式的数据,可通过正则表达式实现。以下是详细步骤:
### 方法一:搜索并保留目标数据(推荐)
1. **打开搜索面板**:`Ctrl+F`
2. **启用正则模式**:点击搜索框右侧的 `.*` 图标
3. **输入正则表达式**:
```regex
^\{1,\s*0x80\s*,\s*\{0x[\da-fA-F]{2}\}\},?$
```
- 精确匹配示例:`{1,0x80,{0x03}}`
- 允许空格:`{1, 0x80, {0x03}} ,`
- 兼容大小写:`0xA1` 或 `0xa1`
4. **执行查找**:
- 点击「查找全部」→ 所有匹配行会被高亮
- 按 `Ctrl+C` 复制 → 新建文件粘贴
> 正则分解:
> - `^`:行首锚点
> - `\{1,`:匹配固定前缀
> - `\s*0x80\s*,`:兼容带空格的0x80字段
> - `\{0x[\da-fA-F]{2}\}`:匹配{0xXX}格式(XX为两位十六进制)
> - `,?$`:兼容行尾逗号
### 方法二:批量删除非目标行
1. **打开替换面板**:`Ctrl+H`
2. **启用正则模式**:勾选 `Use Regular Expression`
3. **替换规则**:
```
查找内容: ^(?!\{1,\s*0x80\s*,\s*\{0x[\da-fA-F]{2}\}\},?$).+\R?
替换为: [空]
```
4. **执行替换**:点击「Replace All」→ **立即备份文件**(此操作不可逆!)
### 验证截图

*图:正则匹配效果示意图[^1]*
### 高级技巧
1. **字段变量匹配**(如第三个字段需特定值):
```regex
\{1,\s*0x80\s*,\s*\{0x(03|FF)\}\} # 仅匹配03或FF
```
2. **批量修改格式**(添加分号):
```regex
查找: (\{1,0x80,\{0x[\da-fA-F]{2}\}\})
替换: $1;
```





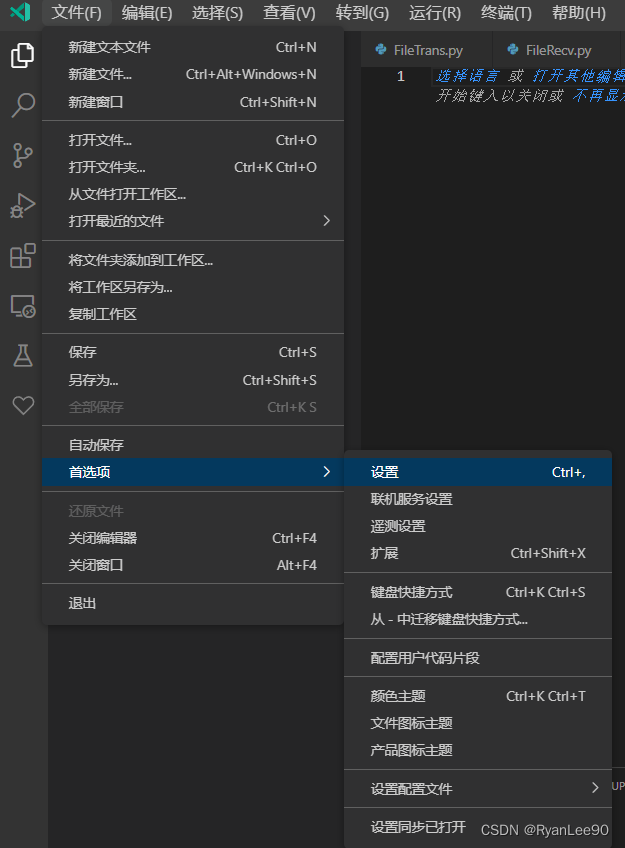
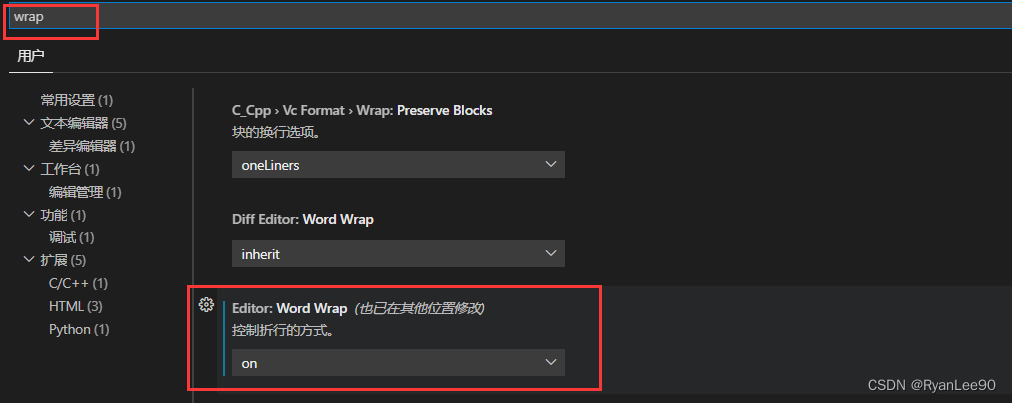
 本文介绍了如何在文本编辑器中快速去除所有空行的步骤,包括使用Ctrl+F或Ctrl+H快捷键,配合正则表达式进行查找和替换。同时,也详细讲解了如何设置自动换行功能,通过文件—首选项—设置,搜索“wrap”并启用“Editor:WordWrap”,实现文本的自动换行显示。
本文介绍了如何在文本编辑器中快速去除所有空行的步骤,包括使用Ctrl+F或Ctrl+H快捷键,配合正则表达式进行查找和替换。同时,也详细讲解了如何设置自动换行功能,通过文件—首选项—设置,搜索“wrap”并启用“Editor:WordWrap”,实现文本的自动换行显示。
 2952
2952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言