




引言
作者认为在RIS任务中,抽象知识来源于对自然语言对目标的抽象描述,具体知识来源于特定的图像,例如下图:对于同一个句子“the cat on the sofa.”,对应的猫可能会有不同的外观与不同的输入图像。我们把猫在不同形象中的具体表象作为具体知识
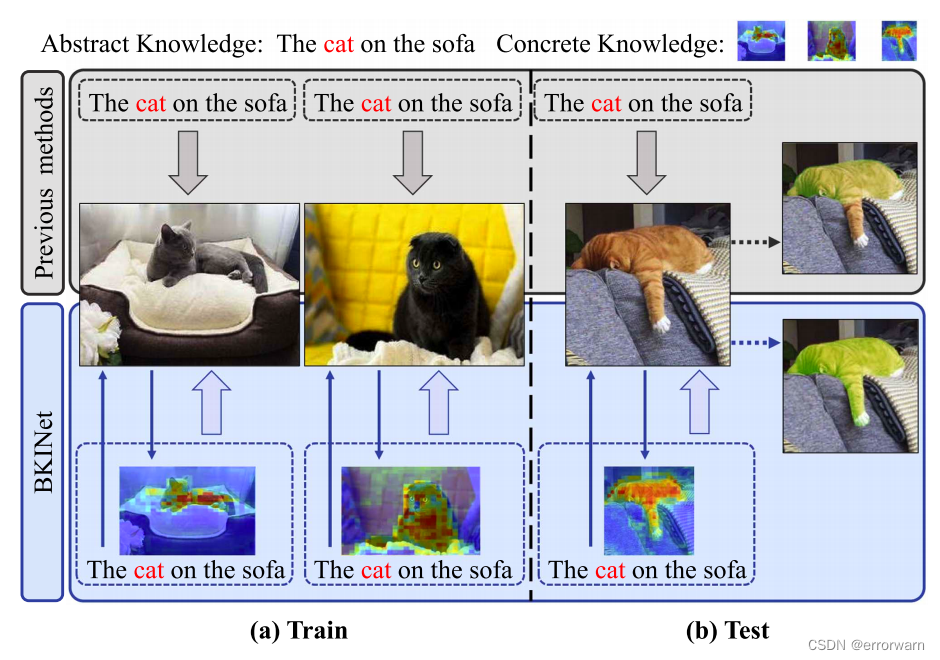
作者认为以往的方法都是基于抽象知识直接分割出最相关的区域,由于缺乏与目标物体各区域的正确对应关系,无法得到准确的分割。因此,提出了BKINet网络:BKINet的主要原理是捕获图像中目标对象的具体知识,并将文本中的抽象知识与具体知识相结合,将目标对象从图像中分割出来。
BKINet网络概述
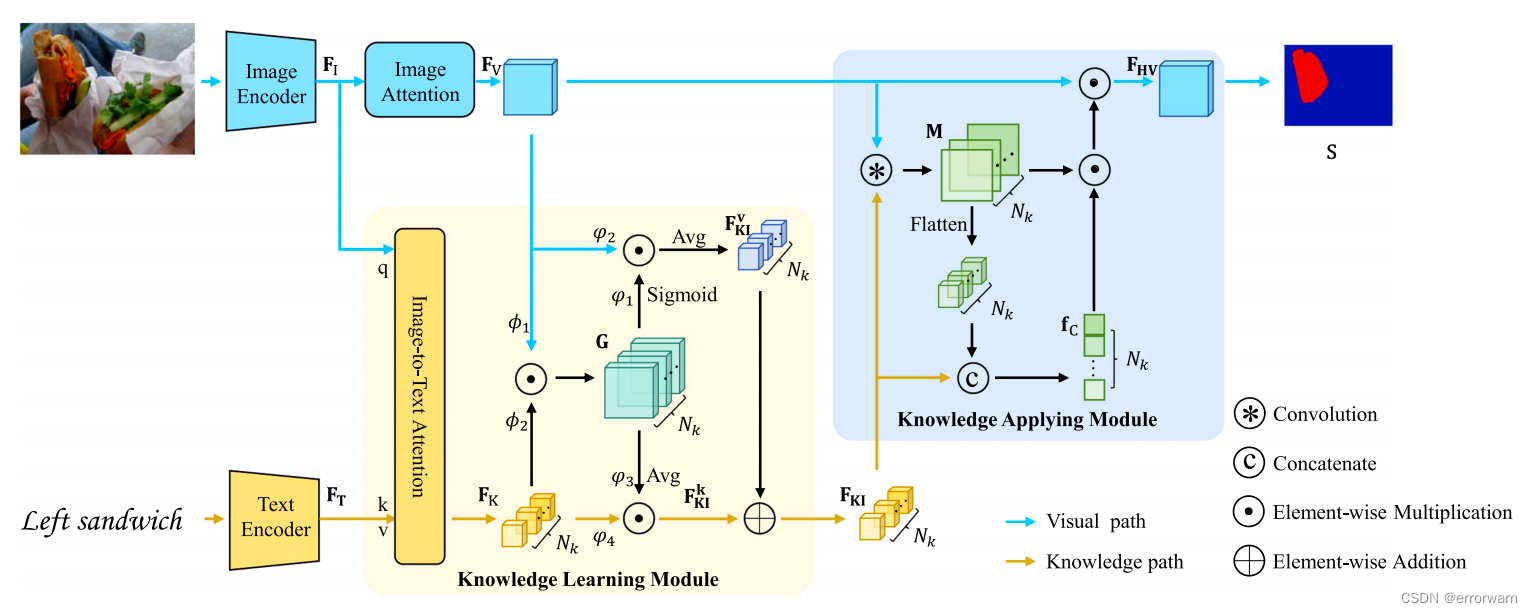
BKINet由知识学习模块(KLM)和知识应用模块(KAM)组成,实现双方的知识交互。具体而言,KLM通过一种由粗到精的策略,通过聚合与目标对象最相关的视觉信息来增强文本特征,该策略将对象的具体知识补充到文本的抽象知识中,从而生成包含参考信息的KI核。然后,KAM应用包含具体和抽象知识的KI核来突出视觉特征。然后,利用突出的视觉特征通过卷积层预测准确的分割掩码。
具体实现
特征提取
文本的提取使用了CLIP的文本特征提取方法得到了语言特征和全局文本特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1651
1651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









