一. 前言
代码:https://github.com/stepfun-ai/Step1X-Edit
论文:https://arxiv.org/abs/2504.17761
近年来,图像编辑技术发展迅速,GPT- 4o、Gemini2 Flash等前沿多模态模型的推出,展现了图像编辑能力的巨大潜力。
这些模型展示了令人印象深刻的适应能力,能够满足绝大多数用户驱动的编辑需求,标志着图像处理领域取得了重大进展。然而,开源算法与这些闭源模型之间仍存在较大差距。为此,我们介绍了一种最先进的图像编辑模型——Step1X-Edit,旨在提供与GPT-4o和Gemini2 Flash等闭源模型相当的性能。
更具体地,我们采用多模态语言模型处理参考图像和用户的编辑指令,提取出潜在嵌入,并与扩散图像解码器结合,以获得目标图像。为了训练这个模型,我们构建了一个涵盖11项编辑任务的数据生成管道,以生成高质量的数据集。为了评估,我们开发了GEdit-Bench,这是一个基于真实用户指令的新颖基准测试。GEditBench上的实验结果表明,Step1X-Edit显著优于现有的开源基线,并接近领先专有模型的性能,从而对图像编辑领域做出了重要贡献。
主要贡献:
- 开源了Step1X-Edit模型,以减少开源和闭源图像编辑系统之间的性能差距,并促进图像编辑领域的进一步研究。
- 数据生成管道旨在生产高质量的图像编辑数据。它确保数据集多样化、具有代表性,并且质量足以支持有效图像编辑模型的开发。此类管道的可用性为从事类似项目的研究人员和开发者提供了宝贵的资源。
- 为了支持更真实、更全面的评估,开发了一个基于实际使用的新基准,名为GEdit-Bench。该基准经过精心策划,旨在反映实际用户编辑需求和广泛的编辑场景,从而能够对图像编辑模型进行更真实、更全面的评估。
二. 算法实现
1. 数据准备(有重要的参考价值)
- 从网络上爬取大量的图片,2000万张;
- 通过多模态大模型(SAM2、Qwen2.5-VL、 GPT-4o等)、传统深度学习模型(OCR)等对图片进行处理;
- 用算法处理后,用GPT4进行美学评分,最后再进行人工审查,最终保留了100万训练数据。
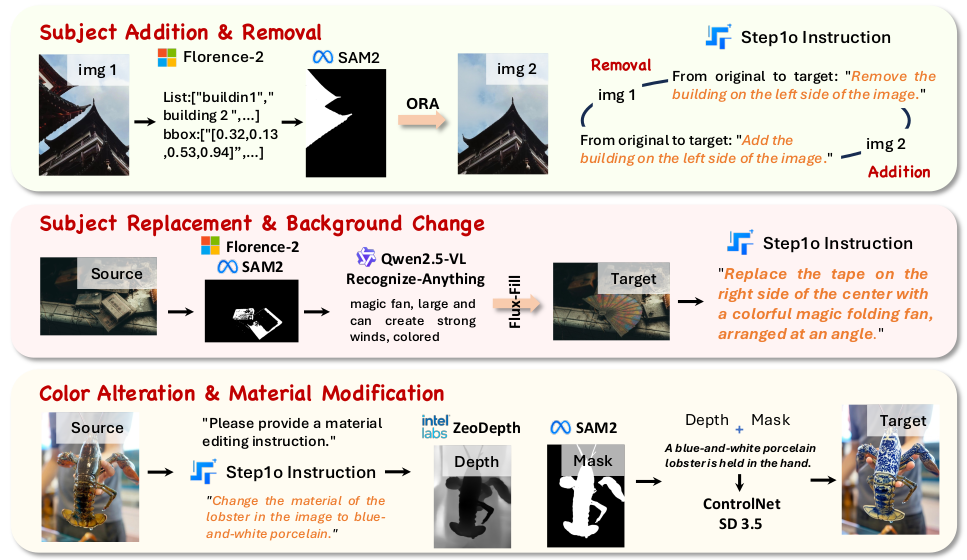
算法处理流程示例
获得的训练数据是一个三元组,包含:原始图片、编辑指令、修改后的图片。
2. 算法原理
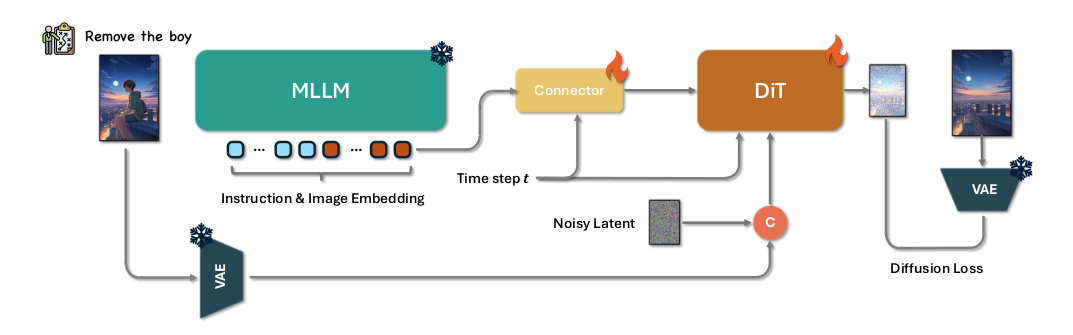
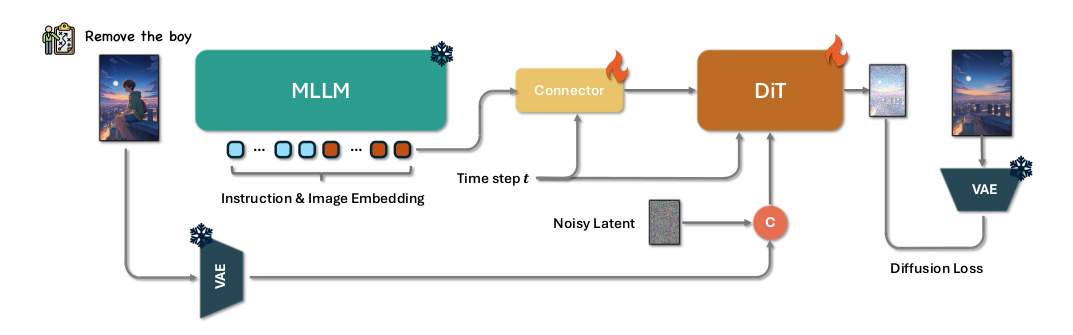
Step1X-Edit框架。Step1X-Edit利用MLLMs的图像理解能力来解析编辑指令并生成编辑标记,然后使用基于DiT的网络将这些标记解码为图像。
如上图所示,Step1X-Edit框架主要包含三个部分:**多模态大语言模型(MLLM)**、**连接模块(Connector)**、**扩散模型(DIT)**。
输入编辑指令及其参考图像首先被引入到MLLM(QwenVL)中,这些输入通过MLLM的一次前向传递共同处理,使模型能够捕捉指令与视觉内容之间的语义关系。为了隔离并强调与编辑任务相关的语义元素,我们选择性地丢弃了与前缀相关的词嵌入。这个过滤过程只保留与编辑信息直接对齐的标记嵌入,确保后续处理精确地关注编辑要求。
提取的嵌入向量随后被输入到一个轻量级连接模块,该模块将嵌入向量重组为更紧凑的多模态特征表示,之后作为下游DiT网络的多模态嵌入输入使用。
模型不仅保留了跨模态的理解能力,还增强了图像细节的提取。通过在一个统一框架内结合结构化的视觉语言指导、详细的视觉条件和强大的预训练骨干网络,该方法显著提升了系统执行高保真、语义对齐的图像编辑的能力,能够处理各种用户指令。在训练过程中,仅使用扩散损失联合优化连接器和下游的DiT。
### 3. 模型评估
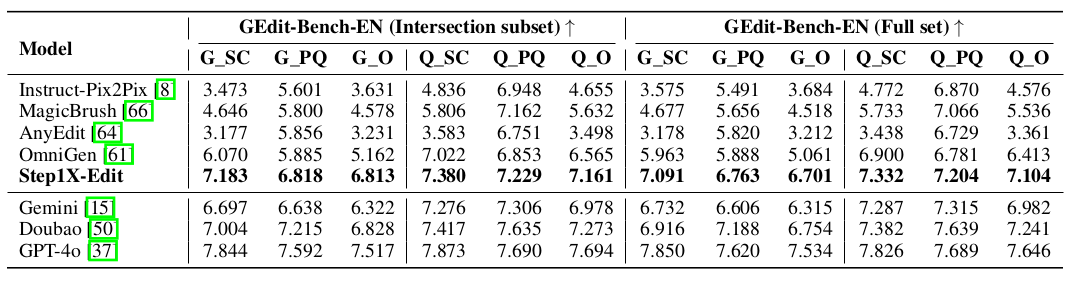
作者还建立了一套评估系统对模型进行了评估,评估结果达到开源的SOTA水平,接近闭源的Gemini和Doubao水平。如下表所示:
## 三. 效果与总结
### 1. 算法效果

### 2. 总结
作者介绍了一种新的通用图像编辑算法,称为Step1X-Edit,该算法将公开发布,以促进图像编辑社区内的进一步创新和研究。为了有效训练模型,作者提出了一种新的数据生成管道,能够生成大规模高质量的图像编辑三元组,每个三元组包含一张参考图像、一条编辑指令和一张相应的目标图像。基于收集的数据集,通过无缝集成强大的多模态大语言模型与基于扩散的图像解码器来训练Step1X-Edit模型。在收集的GEdit-Bench上的评估,该算法在性能上显著优于现有的开源图像编辑算法。
谢谢各位看官,如果喜欢,点赞+收藏~


























 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











