 区域-关键词跨模态对齐框架:解决多模态特征匹配问题
区域-关键词跨模态对齐框架:解决多模态特征匹配问题





 文章提出一种区域-关键词跨模态对齐框架,结合CLIP的图像和语言编码器,通过跨模态对准和多源驱动动态卷积,解决模态间语义信息不一致,以提升图像分割的准确性。
文章提出一种区域-关键词跨模态对齐框架,结合CLIP的图像和语言编码器,通过跨模态对准和多源驱动动态卷积,解决模态间语义信息不一致,以提升图像分割的准确性。
作者贡献
1.设计了一种区域-关键词跨模态对齐框架,用于参考图像分割解决了两种模态特征单元之间语义信息不一致的问题。
2.提出了一个跨模态混合模块,在融合早期实现不同模态之间更全面的信息交互。
3.提出了一种多源驱动的动态卷积算法,该算法基于文本特征、视觉特征和跨模态特征将区域关键词跨模态特征反向映射到分割掩码中。
框架介绍
下图显示了拟议AKCA的框架。首先,图像编码器和语言编码器分别提取图像和语言特征。然后用跨模态对准模块对两模态之间的关系进行建模。最后,多源驱动的动态卷积将跨模态特征转换为像素级预测。
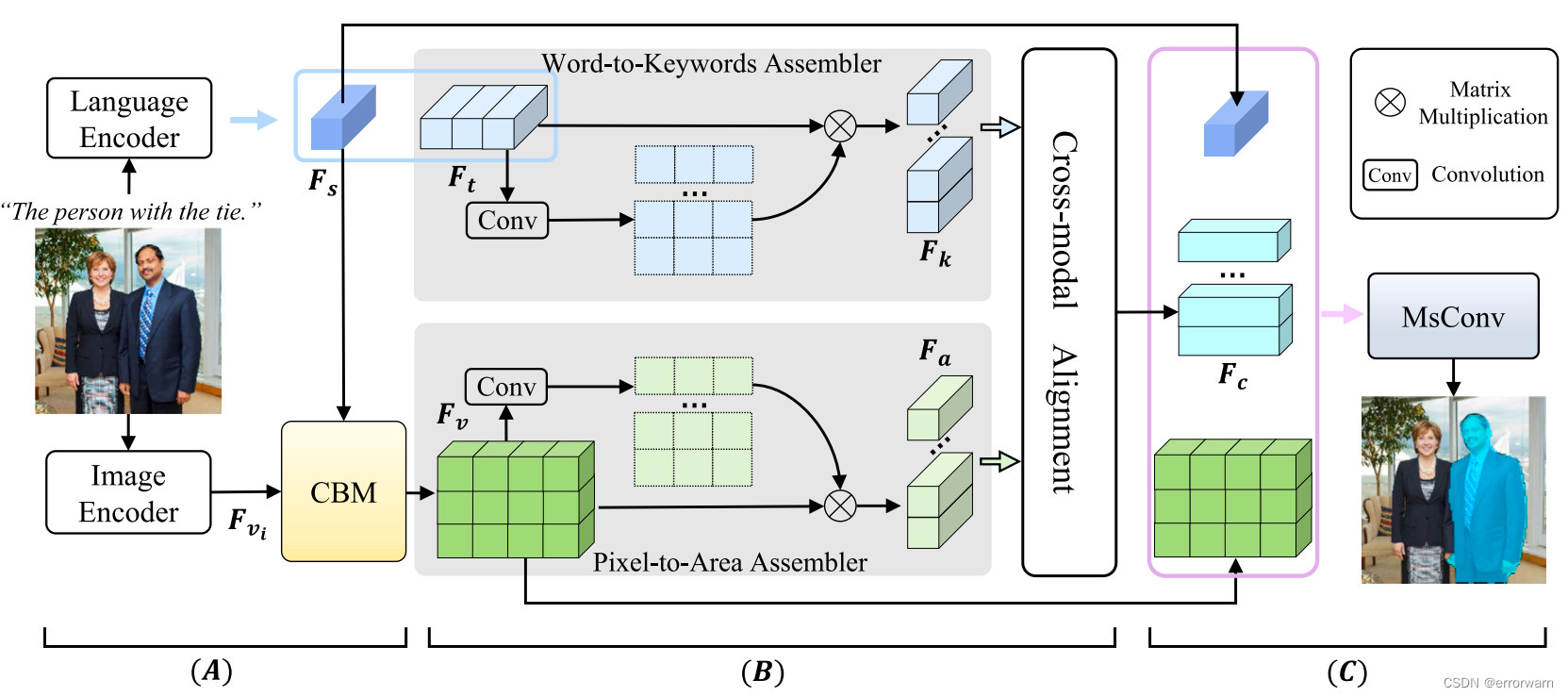
多模态编码器
AKCA采用CLIP的图像编码器和语言编码器来提取两种模态的特征。
文本编码器
输入表达式,CLIP编码后得到文本特征
,并且可以再CLIP的文本编码器中得到全局语义特征
。
图像编码器
输入图像,将ResNet的第2,3,4阶段的输出特征作为多层视觉特征,分别表示为
。
跨模态混合模块(CBM)
在编码器阶段的早期跨模态融合被证明对RIS是有效的。作者将多层视觉特征与全局文本特征融合。统合方式是通过将全局文本特征与视觉特征相乘。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 902
902





 到【灌水乐园】发言
到【灌水乐园】发言







