




解决的问题:
几乎所有现有的RIS方法都依赖于全监督学习方案来产生准确的结果,这需要耗时和劳动密集型的像素级注释.要设计具有更便宜的监督信号的RIS模型。
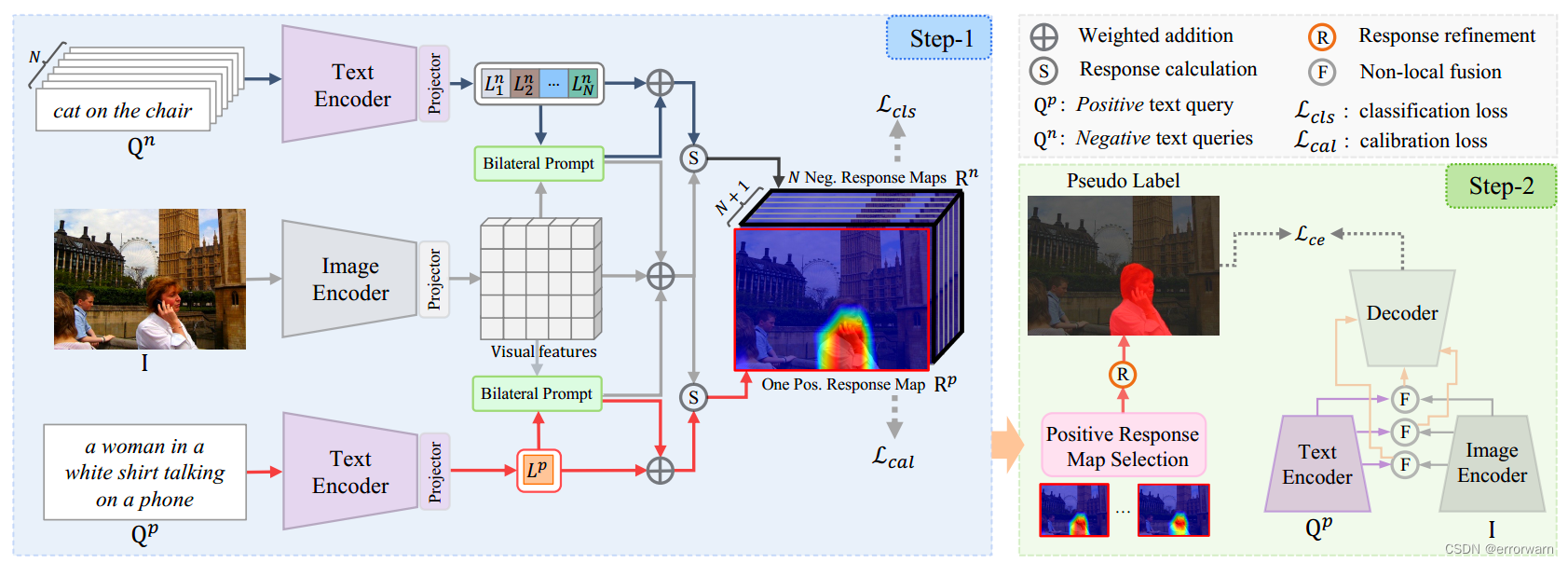
我的理解是,前半张图表示的内容是利用弱监督模型生成像素级伪标签,后半张图表述用以伪标签训练一个RIS模型。
解决方法:
(1)该框架只通过现有的参考文本监督,不需要额外的annotation信息
(2)我们提出了一种协调视觉和语言模态差异的双边提示方法。
(3)我们提出了一种校正方法来提高响应图定位的正确性。
(4)我们提出了一种响应图选择策略来生成高质量的伪标签,用于目标对象的分割。
(5)提出了一种新的定位精度评价指标。
网络结构:
(1)Text-to-Image Response Modeling :
编码器编码图片和参考文本,再映射到相同的通道上,根据Bilateral Prompt方法得到的提示特征分别与图片和文本特征残差连接,再将两种特征举矩阵相乘得到响应图。响应图中的像素反应当前像素与整个查询语句的响应值。
(2)Bilateral Prompt:
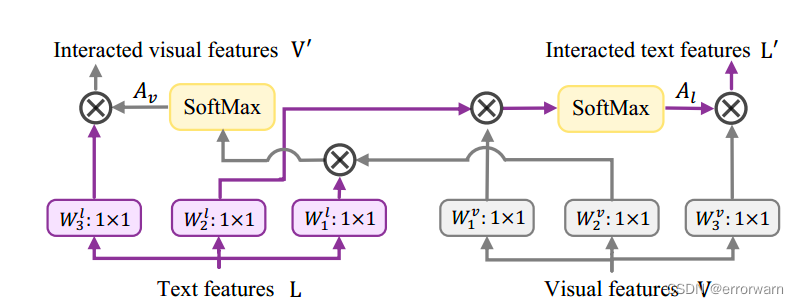
输入的图像和文本特征各自与可学习权重相乘得到Q,K,V 两边的Q,K相乘除以根号下通道数得到各自的注意力矩阵,再与对方的Value相乘得到双边提示特征。
(3)Localization via Text-to-Image Optimization:
首先做一个分类,让模型从一组积极和消
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4992
4992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









