



基于神经网络的最优低动态范围图像生成方法
摘要
本文提出了一种基于神经网络的方法,通过单幅低动态范围(LDR)图像生成具有不同曝光的多幅图像,以改善高动态范围(HDR)成像。所提算法包含三个步骤:i)二维直方图估计,ii)基于神经网络的LDR图像估计,iii)生成一组最优的不同曝光图像。该方法首先通过估计基于图像块的二维直方图来生成图像特征。提取的特征用于神经网络的输入层,以选择最优的LDR图像集。利用基于曲率的对比度增强方法生成一组LDR图像。实验结果表明,所提出的方法能够利用神经网络生成最优的LDR图像集,并获得更优的HDR图像。此外,该方法可作为大多数现有HDR框架中的预处理步骤。所提出的HDR方法是一种单输入方法,其性能几乎与基于多幅图像的HDR方法相当。
关键词 —高动态范围图像,HDR算法,多曝光融合,单幅图像HDR,神经网络,二维直方图,对比度增强。
I. 引言
尽管人类视觉系统能够感知高动态范围,但数字设备由于传感器特性和量化过程而具有有限动态范围。此外,大气中的光散射、逆光以及低光照条件也会导致输入图像具有低对比度比。传统高动态范围(HDR)成像通过融合在极短时间间隔内以不同曝光条件获取的图像集来实现。
然而,物体运动和手抖会引入重影效应等不希望的伪影,从而降低高动态范围图像的质量。为了获取具有不同曝光的更优多幅输入图像,文献中已提出了许多HDR成像方法。
HDR算法可分为两类:i) 基于多曝光图像的方法,以及 ii) 基于单幅图像的方法。基于多曝光图像的方法通过融合在同一场景下以不同曝光条件获取的多幅低动态范围(LDR)图像来生成HDR图像[1]‐[3]。Mertens等人提出了一种使用多曝光图像和权重图的高动态范围成像方法,权重图分别根据对比度、饱和度和良好曝光进行估计[1]。
对比度权重通过将拉普拉斯滤波的结果与多曝光图像结合而生成。为了避免亮区的饱和,饱和度权重通过计算红(R)、绿(G)和蓝(B)像素之间的变化获得。当像素强度接近整个范围内的0.5或中间值时,良好曝光权重被设为较高值,反之则较低,其作用是避免欠曝或过曝。
Paul等人使用了多曝光图像的亮度和色度通道。由于欠曝光区域的梯度幅度较低,因此通过将梯度与权重图[2]融合来对亮度通道进行补偿。权重图的估计方法是:梯度幅度越高,赋予的权重越大,反之亦然。另一方面,色度通道则使用权重图进行融合,该权重图的估计方式与Mertens等人的良好曝光权重估计方法相同。
Ma等人提出了一种基于结构化块分解的改进的图像融合方法[3]。该方法将每个多曝光图像分解为多个图像块,并将分解后的图像块分为三个组成部分:信号强度、信号结构和平均强度。信号强度由分解后图像块之间的最高强度值确定,信号结构由图像块的‐范数确定,而平均强度则通过图像块的强度值与0.5的接近程度来计算。
另一方面,基于单幅图像的方法通过调整单幅输入图像来生成一组低动态范围图像亮度[4][5]。在基于单幅图像的高动态范围成像方面,Wang的方法利用单幅输入图像的亮度通道,通过三种不同方式生成一组图像:对数变换、伽马校正和广义非锐化掩模(GUM)[4]。通过生成的图像集和权重图获得高动态范围图像,从而保证强度值接近0.5。
Im的方法使用局部直方图拉伸[5]生成了过曝、正常曝光和欠曝图像。此外,该方法在亮区执行空间自适应噪声抑制,以减少局部直方图拉伸所放大的噪声。最后,进行基于权重图的图像融合。
Lim等人使用映射函数生成多个低动态范围图像,并通过自适应选择空间变化曝光(SVE)模式[6]来重建高动态范围图像。Celebi等人使用自适应直方图分离算法生成多个低动态范围图像,并利用基于模糊逻辑的算法[7]融合生成的低动态范围图像。
本文中,使用神经网络从单幅输入图像生成一组最优低动态范围图像。所提出的方法包括三个步骤:i)估计二维直方图,ii)使用神经网络估计最优LDR图像集,以及iii)生成最优LDR图像集。为了提取有意义的特征,所提方法利用邻近像素间的强度差[8]来估计输入图像的二维直方图。由于估计的二维直方图表示细节分布,因此所提出的神经网络被训练用于生成一组在高动态范围成像中保留细节的低动态范围图像。神经网络提供适当的曝光水平以模拟低动态范围图像。使用基于曲率的对比度增强方法生成一组低动态范围图像。
本文结构如下。第2节分三个步骤解释所提算法。第3节比较现有融合方法与使用所提算法进行融合的结果,第4节总结全文。
II. 使用神经网络生成最优LDR图像集
A. 二维直方图的估计
高动态范围成像旨在通过保留暗区和亮区的细节,来增强一张或多张低动态范围图像的动态范围。由于所提出的方法学习了输入低动态范围图像细节之间的关系,分析输入低动态范围图像的细节非常重要。为了将这些细节用作神经网络中的特征形式,所提出的方法估算了输入低动态范围图像在YCbCr颜色空间中亮度通道的二维直方图。
通过计算具有强度值p和q的邻域像素的数量,来计算图像的二维直方图:
$$
݄_{2D}(, ݍ) = \left| { (ݔ, ݕ) | ݃(ݔ, ݕ) = , ݃(ݔ + ݅, ݕ + ݆) = ݍ, , ݍ ∈ [0, 255], ≠ ݍ, (݅, ݆) ∈ ܰ_4 } \right|,
$$
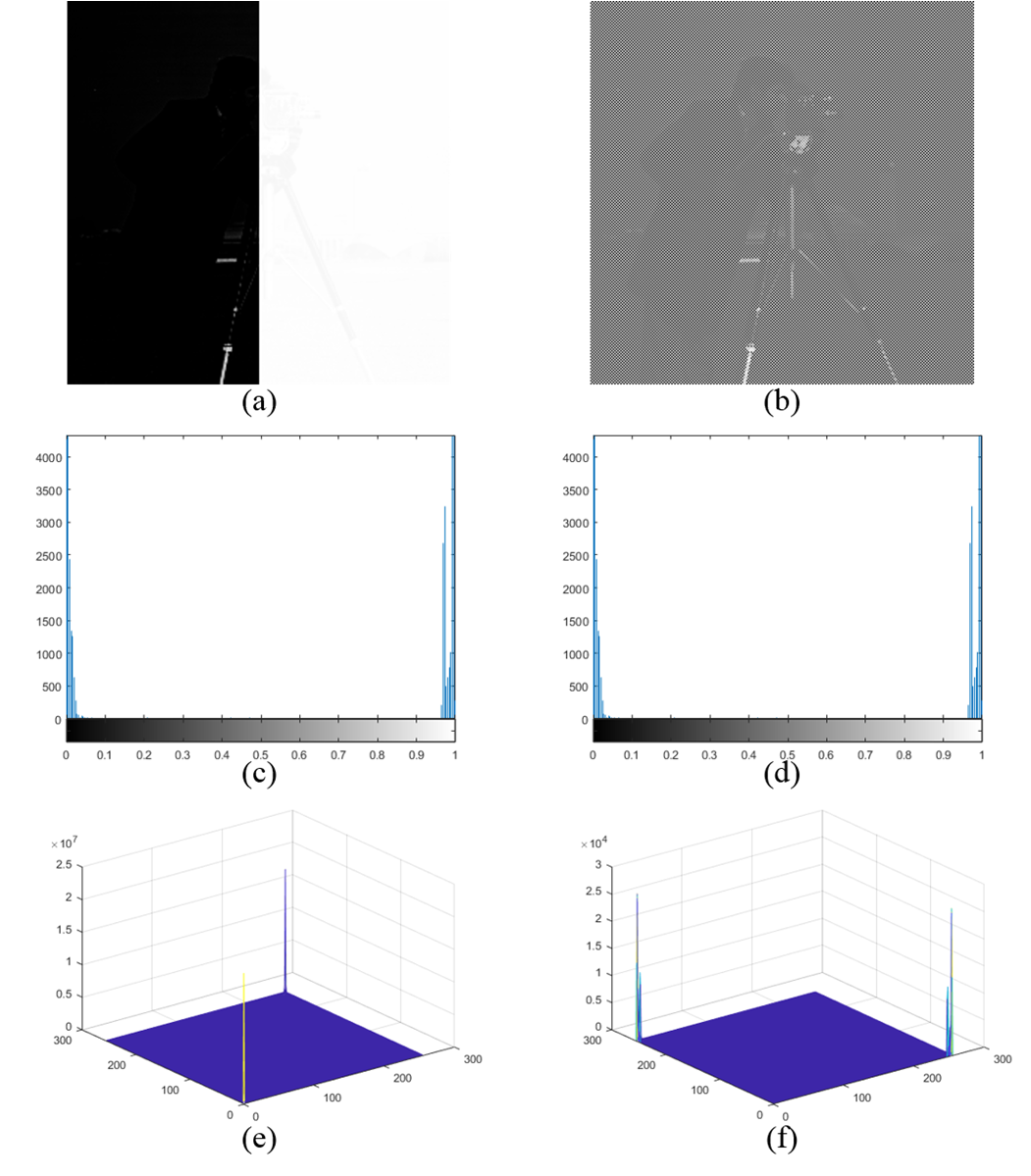
其中,基数运算$|\cdot|$表示集合的元素个数,$݃(ݔ, ݕ)$为输入低动态范围图像的亮度通道,$ܰ 4$为四邻域,$݄ {2D}(, ݍ)$为指定区域内的二维直方图。由于二维直方图是通过除具有相同强度的像素外的邻域像素估计得到的,因此二维直方图的分布包含了边缘和纹理区域的信息,如图2所示。
为了比较一维和二维直方图的特性,我们使用了两种不同模拟的LDR图像。图2(a)是通过分别调整测试图像一半区域的亮度生成的。图2(b)显示了以逐像素方式调整亮度后生成的模拟LDR图像。如图2(c)和图2(d)所示,一维直方图仅提供所有像素的强度分布。另一方面,图2(e)和图2(f)展示了LDR区域中细节的分布,因为二维直方图排除了具有相同强度值的像素。
在所提出的方法中,利用估计的二维直方图来为神经网络提取特征。由于二维直方图表示输入低动态范围图像中细节区域的直方图,因此所提出的方法在神经网络的输入层估计二维直方图特征。输入低动态范围图像中的细节特征被提取为:
$$
ܦ(݇) = \frac{1}{ܥ} \sum_{݅=0}^{݊} \sum_{݆=0}^{݉} ݄_{2D}( + ݅, ݍ + ݆),
$$
其中,$݇ ∈ [1, 64]$表示强度等级,$ܦ(݇)$表示二维直方图中大小为$݉×݊$的图像块的均值,$ܥ$为归一化常数。
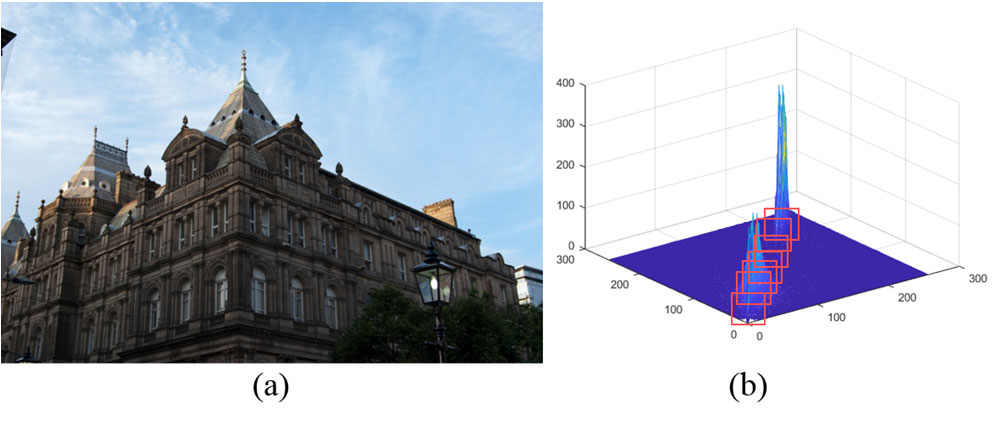
$ܦ(݇)$表示强度等级݇中大量细节的数量。图3展示了使用二维直方图在真实图像中提取的特征。所提出的神经网络通过利用提取的特征选择最优LDR图像集,用于高动态范围成像以保留细节。

B. 基于神经网络的低动态范围图像估计
给定单个输入低动态范围图像,所提出的方法使用神经网络估计一组低动态范围图像。尽管神经网络通常在计算机视觉中用作分类器,但它也可用于图像处理领域以提升图像质量。Park等人使用神经网络[9]估计了分割图像的轮廓,而Dinh等人则使用前馈神经网络[10]在超级视频家用系统(S-VHS)中恢复模糊的亮度图像。
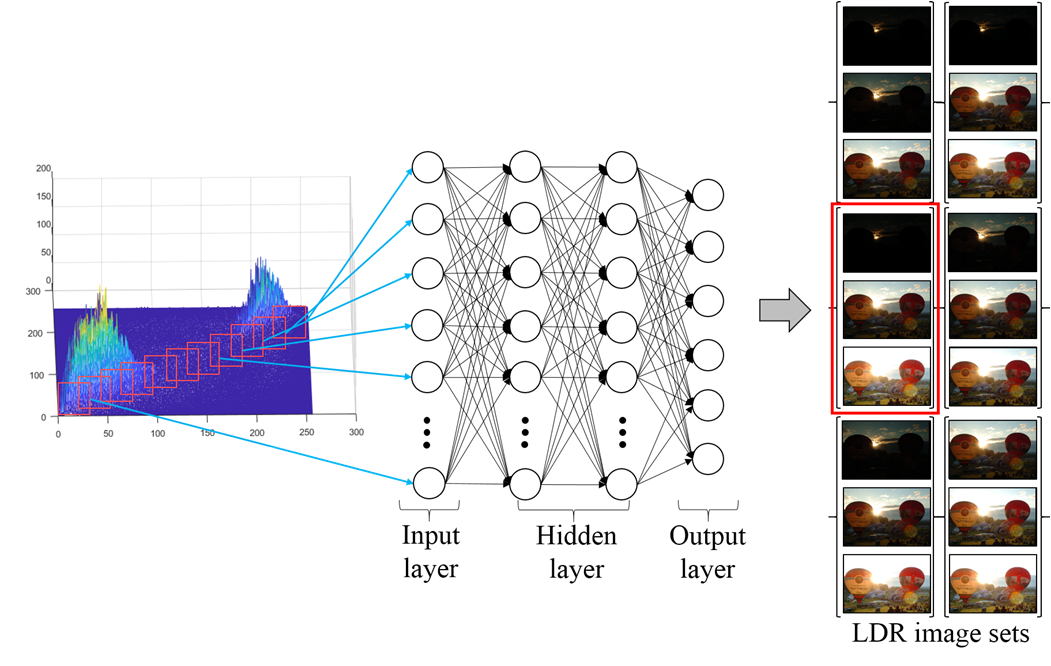
在此步骤中,从输入低动态范围图像的二维直方图中提取的特征$ܦ(݇)$被用作神经网络的输入。所提出的神经网络通过多组低动态范围图像进行训练,以更好地恢复并保留细节的低动态范围图像。图4展示了神经网络模型,该模型由两个隐含层组成。
所提算法使用了在[11][12]中使用的前馈神经网络模型。一个通用的网络由神经元组成,这些神经元接收多个输入,并对加权输入进行求和以产生输出:
$$
ݕ = ߮\left(\sum ݓ_i ݔ_i\right),
$$
其中$ݔ_i$表示多个输入,$ݕ$表示神经元的输出,$ݓ_i$表示每个输入的权重,$߮$表示激活函数。这些神经元构成一层,多层共同构成一个神经网络。在学习过程中,每个神经元的权重沿最小化预设代价函数的方向进行更新。所提出的神经网络的代价函数由逻辑回归和正则化项组成:
$$
ܬ(ߠ) = -\frac{1}{݉} \sum_{݅=1}^{݉} \sum_{݊=1}^{ܰ} ܴ
n^i(ߠ) + \frac{\lambda}{2݉} \sum
{݈=1}^{ܮ-1} \sum_{݅=1}^{ݏ_݈} \sum_{݆=1}^{ݏ_{݈+1}} \left(ߠ_{݆݅}^݈\right)^2,
$$
其中
$$
ܴ_n^i(ߠ) = ݕ_n^i \log\left(݄_ߠ\left(ݔ_n^i\right)\right) - \left(1 - ݕ_n^i\right) \log\left(1 - ݄_ߠ\left(ݔ_n^i\right)\right),
$$
$ܰ$表示训练图像的数量,$ܮ$表示层数,$ݏ_݈$表示第݈层的单元数量,݉表示训练集的数量。$ݔ_n^i$是第݊个训练集的第݅个输入,$ݕ_n^i$是第݊个训练集的第݅个目标输出,$ߠ_{݆݅}^݈$是第$(݈ - 1)$层第݅个单元与第݈层第݆个单元之间的权重。$݄_ߠ(ݔ_n^i)$是双曲正切函数,用于计算输入代入后的结果。使用逻辑回归$ܴ_n^i(ߠ)$作为拟合函数以减小目标输出与结果输出之间的误差,并使用正则化项避免过拟合。权重被迭代更新,以使输出结果与目标一致。
给定一组5张训练用低动态范围图像,如果选择其中包含一张0EV的3张低动态范围图像,则所提神经网络的输出层有6个单元。为简化起见,此处省略对偏置单元的说明。
输出层中的每个单元代表一组低动态范围图像,如图4所示。例如,当输出层的第݇个单元具有最高值时,即选择第݇组低动态范围图像(݇_1 EV、݇_2 EV和݇_3 EV)。通过更新权重来获取细节与一组最优低动态范围图像之间的关系。
C. 最优低动态范围图像生成
为了利用通过训练所提出的神经网络获得的曝光水平来生成一组最优低动态范围图像,所提出的方法引入了一种基于曲率的强度传递函数。通常情况下,通过增强亮度通道以保留输入图像的颜色信息来改善低动态范围图像。
然而,由于在低光条件下R、G和B通道之间的差异极小,色度通道的值也非常低,导致结果图像丢失颜色信息。为了在提高输入低动态范围图像亮度的同时恢复颜色分量,所提出的方法使用基于曲率的强度传递函数增加颜色通道之间的差异。
为了生成亮度值与其伽马校正版本相近且突出颜色分量的输入低动态范围图像,所提出的方法采用了伽马校正后的亮度通道和圆方程的一般形式。所提出的强度传递函数定义为生成更亮的图像,对于$0 \leq \gamma \leq 1$,
$$
݂
ܿ = -\sqrt{2ܽ^2 - (݃
ܿ + ܽ)^2} + ܽ,
$$
其中
$$
ܽ = \frac{݃_ݕ^{2\gamma} + ݃_ݕ^2}{2(݃_ݕ^\gamma - ݃_ݕ)}.
$$
另一方面,生成更暗的图像的传递函数定义为,对于$1 \leq \gamma \leq \infty$,
$$
݂
ܿ = \sqrt{2ܽ^2 - (݃
ܿ - ܽ - 1)^2} + 1 - ܽ,
$$
其中
$$
ܽ = \frac{(݃_ݕ^\gamma - 1)^2 + (݃_ݕ - 1)^2}{2(݃_ݕ - ݃_ݕ^\gamma)},
$$
$݃ ܿ$表示输入图像,$݂ ܿ$表示结果图像,$݃_ݕ$表示输入图像的亮度通道,$݃_ݕ^\gamma$表示使用伽马校正增强的亮度,$ܿ \in {R, G, B}$。在RGB颜色空间中的强度值被映射到通过伽马曲线上对应点的圆上,以形成较大的间隔。当生成更亮的图像时,亮区的曲率设为较小,反之亦然。另一方面,当生成更暗的图像时,从亮区到暗区的曲率应逐渐变小。
因此,所提出的强度传递模型利用亮度通道的强度值来控制圆的半径,从而根据强度值自适应地设置曲率。图5展示了仅使用伽马校正和所提出的方法的结果。图中还给出了伽马校正和所提出的模型的映射函数。
在图5中,$\gamma = 0.3$被使用了。尽管图5(a)和5(b)具有相似的亮度,但所提出的方法的结果中的颜色数量远高于仅使用伽马校正的结果。图5(c)显示当输入较大时,所提出的模型变为线性。它还表明,与伽马校正相比,所提出的方法在R、G和B之间存在更大的差异。
 伽马校正的结果,(b) 所提出的方法的结果,以及 (c) 伽马校正和所提出方法的图形)
伽马校正的结果,(b) 所提出的方法的结果,以及 (c) 伽马校正和所提出方法的图形)
III. 实验结果
为了评估性能,将所提出的方法作为预处理步骤应用于传统的单幅和基于多幅图像的HDR方法中。采用Mantiuk的[13]和Hautiere的[14]方法进行客观质量评估,并测量处理时间。实验使用配备3.2GHz CPU和8GB内存的个人计算机进行。图6显示了测试所用的一组输入低动态范围图像。

A. 训练条件
所提出的神经网络使用包含830张具有不同动态范围级别的高动态范围图像([15]‐[17])的HDR数据集进行训练。该数据集被划分为70%用于训练,15%用于验证,15%用于测试。为了训练神经网络,所提出的方法生成了6类低动态范围图像,如图4所示。神经网络的训练算法如下:i)选择单张低动态范围图像作为神经网络的输入;ii)使用在[3]中提出的算法,为相应选定的低动态范围图像生成6张高动态范围图像作为真实值;iii)利用选定的低动态范围图像集和真实值高动态范围图像集训练神经网络。所提出的神经网络包含4层:一个输入层、两个隐含层和一个输出层。第二、第三(隐含)和第四(输出)层的单元数量分别设置为32、16和6。
B. 与其他分类器的比较
本小节将所提出的神经网络与其他神经网络模型的性能进行了比较。定量评估使用了[18]中的准确率进行评价:
$$
\text{Accuracy} = \frac{\sum_{i=1}^{n} \text{TP}
i}{\sum
{i=1}^{n} (\text{TP}_i + \text{FP}_i)},
$$
其中,TP表示正确分类的低动态范围图像,FP表示错误分类的低动态范围图像,$i$表示图4中6张低动态范围图像的索引。前馈神经网络和径向基函数神经网络在使用双曲正切函数时的准确率分别为90.2%和88.0%。另一方面,支持向量机(SVM)和决策树(DT)的准确率分别为74.8%和46.6%。由于支持向量机(SVM)和决策树(DT)是二分类器,因此与基于神经网络的多类分类器相比,其准确率较低是合理的。
我们还评估了多种激活函数的准确率,包括双曲正切函数、修正线性单元(ReLU)和sigmoid函数。在实验中,这三种函数的准确率分别为90.2%、88.7%和89.4%。根据对比实验,使用前馈神经网络和双曲正切函数的所提出的方法在端到端映射方面,比其他方法表现更好。
C. 基于多曝光融合的高动态范围成像比较
本小节展示了所提出的方法用于在高动态范围成像中选择一组低动态范围图像作为预处理步骤。在实验中,使用所提出的方法生成了一组低动态范围图像,并采用现有的基于多曝光融合的高动态范围成像方法进行图像融合,例如Mertens方法[1]、Paul方法[2]、Ma方法[3]、Shen方法[19]和Vonikakis方法[20]。图7–9比较了使用与不使用所提出方法的高动态范围成像结果。
在图7–9中,第一列显示了使用现有HDR方法生成的图像。图7–9的第二列和第三列显示了使用相同的现有HDR成像方法,并结合所提出的方法作为预处理步骤,分别基于3张和5张低动态范围图像生成的图像。
如图7所示,第一列图像的对比度与第二列图像的对比度相似,而第三列的对比度优于第一列。尽管第二列图像仅使用了三张低动态范围图像进行处理,但所提出的方法生成的最优LDR图像集可以使用较少数量的低动态范围图像来提高高动态范围图像的质量。
如第三列所示,通过所提出的方法生成的五幅低动态范围图像所得到的高动态范围结果,明显优于现有方法的结果,因为所提出的神经网络和基于曲率的增强提供了一个最优低动态范围输入集合。
图8展示了在低光条件下高动态范围成像生成的图像。如图8的第二列所示,在相同的高动态范围成像条件下,使用所提出的方法生成的3张低动态范围图像得到的高动态范围生成图像,其质量优于第一列中使用5张低动态范围图像得到的结果。图9展示了所提出的神经网络性能的对比。在该实验中,所提出的方法仅选择最优LDR图像集以提供最佳的高动态范围成像性能。
给定一组低动态范围图像,所提出的方法选择包含0EV参考图像的低动态范围图像。



D. 基于单幅图像的高动态范围成像比较
在本小节中,使用现有的基于单幅低动态范围图像的高动态范围成像方法(如Wang的方法[4]和Im的方法[5])对所提出的方法进行了性能评估。图10展示了基于单幅低动态范围图像的高动态范围成像方法生成图像的比较结果。由于Wang的方法旨在增强逆光图像,因此图10(b)显示的结果图像没有亮度饱和现象。Im的方法因采用局部直方图拉伸生成一组低动态范围图像,导致生成的高动态范围图像出现亮度饱和。另一方面,图10(d)展示了所提出的方法利用最优集合的3张低动态范围图像,并结合与图10(b)和图10(c)中类似的图像融合方法得到的结果。如图10(d)所示,所提出的方法能够提供改进的高动态范围图像,在保留亮区的同时恢复了颜色信息。

E. 基于对比度度量的客观评估
本小节介绍了使用Mantiuk的[13]和Hautiere的[14]方法进行的客观评估。Mantiuk的方法(HDR-VDP-2)基于视觉模型,在所有亮度条件下同时估计图像的质量和可见性。尽管Hautiere的方法提供了用于边缘保持和对比度增强比的盲评方法,但高动态范围图像的图像质量仅通过对比度增强比(∑)进行评估。较高的HDR-VDP-2值和∑表示高动态范围图像的质量更好。表I总结了使用测试低动态范围图像进行的客观图像质量评估,如图6所示。
表I显示,使用所提出的方法生成的5张低动态范围图像集融合得到的高动态范围图像具有更高的HDR-VDP-2和∑值。在表I中,情况I是指未使用所提出的方法进行5张低动态范围图像集的融合;情况II和情况III分别是使用所提出的方法生成的三张和五张低动态范围图像集的融合。表I表明,情况II相比原始低动态范围图像集获得了更高的质量评估结果。这表明,所提出的方法能够通过从单个输入LDR图像生成最优LDR图像集作为预处理步骤,成功提升高动态范围图像的质量。此外,所提出的神经网络模型可以作为一种良好的预测器,用于从一组多曝光图像中选择最优的LDR图像集,以获得高质量HDR图像。
F. 处理时间对比
表II显示了使用和不使用所提出的方法对如图6所示的单个低动态范围图像进行测试时,高动态范围成像过程的处理时间对比。如表I和表II总结所示,通过融合一组三幅低动态范围图像生成高动态范围图像,能够在最短的处理时间内获得高质量的图像。另一方面,使用一组五幅低动态范围图像进行高动态范围成像虽然提供了相似的处理时间,但所提出的方法能够以低计算成本生成低动态范围图像的最优集合。
所提出的方法融合一组大小为1024 × 682的LDR图像时,各步骤的处理时间如表III所示。使用Mertens方法[1]对一组LDR图像进行了融合。在表III中,情况I仅执行了由第II.C节中所提出的方法生成的五幅LDR图像的融合。另一方面,在情况II和情况III中,所提出的方法估计了二维直方图,利用神经网络预测最优LDR图像集,并在1秒内生成LDR图像。这意味着所提出的方法提供一组LDR图像的速度快于融合步骤的处理时间。
此外,由于所提出的方法中的低动态范围图像生成步骤可以并行化,因为如第II.C节所述,一组低动态范围图像可以以逐元素方式生成。另外,Kim等人提出了用于移动应用的神经网络加速方法[21]。因此,所提出的方法可以嵌入到消费类设备的硬件中。
| 表I 使用HDR-VDP-2和∑的客观评估比较 | ||||||
|---|---|---|---|---|---|---|
| 方法 | 图像 | 情况I | 情况II | 情况III | ||
| [13] | [14] | [13] | [14] | [13] | ||
| [1] | 图6(a) | 71.36 | 1.90 | 70.79 | 1.93 | 74.50 |
| 图6(b) | 22.36 | 2.29 | 21.77 | 2.29 | 24.53 | |
| 图6(c) | 36.93 | 4.03 | 36.02 | 4.28 | 38.31 | |
| [2] | 图6(a) | 66.11 | 1.64 | 66.49 | 1.69 | 66.08 |
| 图6(b) | 26.76 | 2.27 | 31.92 | 2.50 | 30.98 | |
| 图6(c) | 35.78 | 3.09 | 35.36 | 3.79 | 37.68 | |
| [3] | 图6(a) | 71.41 | 2.08 | 70.27 | 2.03 | 71.72 |
| 图6(b) | 19.26 | 2.26 | 19.64 | 2.27 | 21.75 | |
| 图6(c) | 29.92 | 4.74 | 31.33 | 4.26 | 33.73 | |
| [4] | 图6(a) | 79.66 | 2.13 | 83.33 | 2.17 | 85.63 |
| 图6(b) | 30.37 | 3.10 | 36.46 | 3.26 | 32.33 | |
| [5] | 图6(a) | 67.73 | 1.67 | 69.32 | 1.75 | 69.51 |
| 图6(b) | 18.16 | 2.12 | 21.36 | 2.29 | 23.17 |
| 表II 处理时间比较(秒) | ||||
|---|---|---|---|---|
| 方法 | 图像 | 情况I | 情况II | 情况III |
| [1] | 图6(a) | 4.62 | 2.86 | 4.53 |
| 图6(b) | 13.65 | 8.43 | 13.31 | |
| 图6(c) | 5.70 | 3.90 | 5.94 | |
| [2] | 图6(a) | 3.18 | 2.18 | 2.99 |
| 图6(b) | 8.31 | 6.87 | 8.35 | |
| 图6(c) | 6.81 | 5.64 | 6.92 | |
| [3] | 图6(a) | 17.36 | 1035 | 16.85 |
| 图6(b) | 49.79 | 32.04 | 49.48 | |
| 图6(c) | 42.99 | 27.63 | 42.23 | |
| [4] | 图6(a) | 1379.91 | 836.31 | 1319.18 |
| 图6(b) | 2696.40 | 2068.70 | 2701.4 | |
| [5] | 图6(a) | 3.93 | 2.40 | 3.85 |
| 图6(b) | 11.14 | 6.95 | 10.88 |
| 表III 各处理时间比较(秒) | 2D直方图 | 神经网络 | 低动态范围图像生成 | 融合 | 总计 |
|---|---|---|---|---|---|
| 情况I | – | 0.75 | 3.87 | 4.62 | 4.62 |
| 情况II | 0.09 | 0.01 | 0.47 | 2.29 | 2.86 |
| 情况III | 0.09 | 0.01 | 0.75 | 3.76 | 4.53 |
IV. 结论
本文提出了一种新颖的高动态范围(HDR)预处理方法,用于生成最优的低动态范围(LDR)图像集,以提升现有最先进的HDR方法的性能。所提出的方法通过估计二维直方图中图像块的归一化值来提取特征。由于提取的特征能够反映图像细节的数量和位置信息,因此所提出的神经网络模型可以据此学习并确定最优的亮度传递级别。
此外,所提出的基于曲率的强度传递函数在恢复颜色信息的同时对强度进行调整。实验结果表明,该方法能够在低计算成本下改进现有的基于单幅和多幅图像的HDR成像。
因此,该方法可用于数码相机和手机等消费类应用领域,在预处理步骤中提供高质量HDR图像。

















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









