






 本文探讨了机器学习的三种主要方法,包括参数估计、非线性方法和统计学习理论,重点介绍了支持向量机(SVM)的基本原理、泛化能力和与神经网络的对比。讨论了SVM如何通过最小化经验风险和置信风险来提升模型的泛化能力。
本文探讨了机器学习的三种主要方法,包括参数估计、非线性方法和统计学习理论,重点介绍了支持向量机(SVM)的基本原理、泛化能力和与神经网络的对比。讨论了SVM如何通过最小化经验风险和置信风险来提升模型的泛化能力。
引言
机器学习三种方法:
1、经典的参数估计方法
局限性是需要样本的先验分布
2、非线性方法,如ann
局限性是全靠经验,缺少理论
3、统计学习理论针对小样本
误差:
1、一般误差
真实误差
2、经验误差
来自样本
机器学习的目标是最小化一般误差,但是实际都是最小化经验误差

支持向量机同时最小化经验风险和置信风险。
vc维大,则拟合函数的维度高。
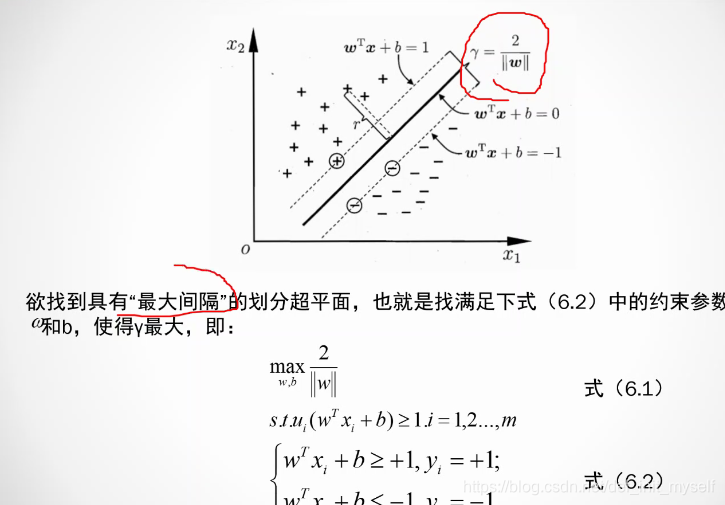
svm
基本型

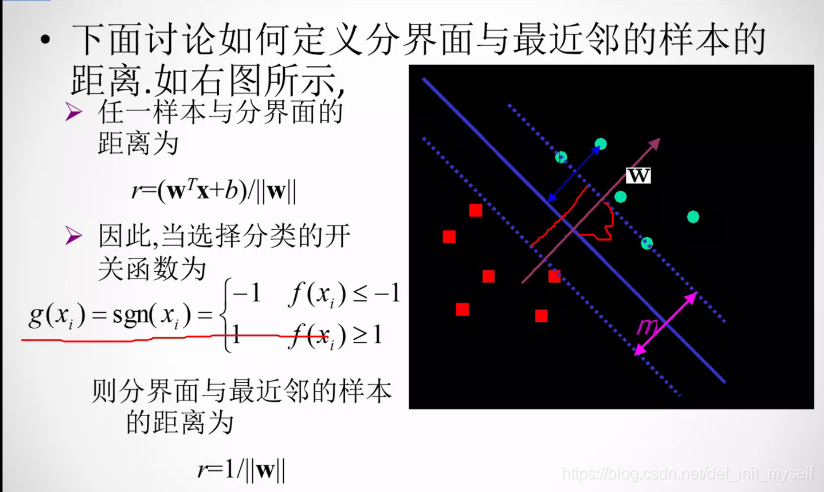
这里的泛化能力最大就是说,正负类间隔最大。

对偶问题

变成求aerfa。
解决不可分问题
映射

但是样本原来就是高维的怎么办?
因此引出了核

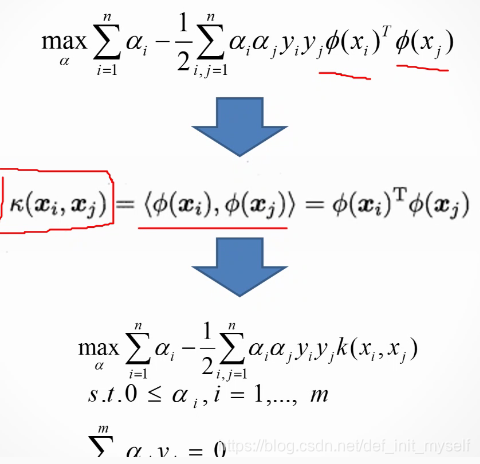
常用的核

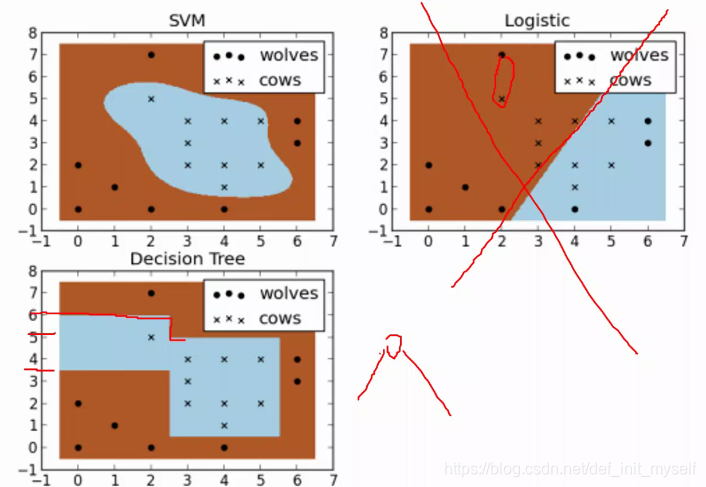
效果
泛化问题
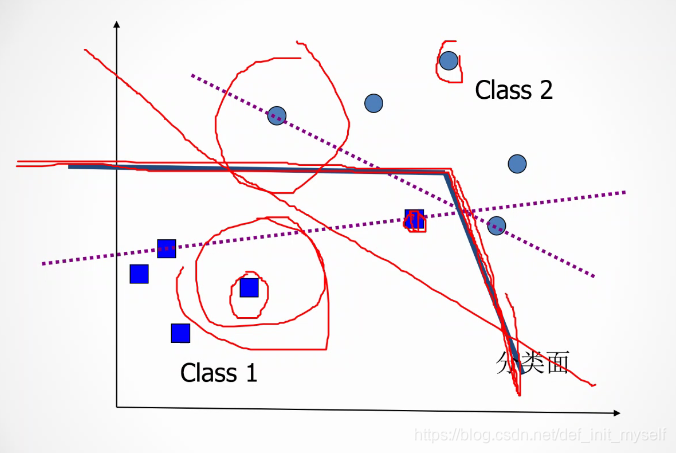
为了追求泛化能力强,可以容忍一个半个的样本错误。
被错分的样本离分解面的距离为kesai,然后把这些松弛变量的和最小。

与神经网络相比
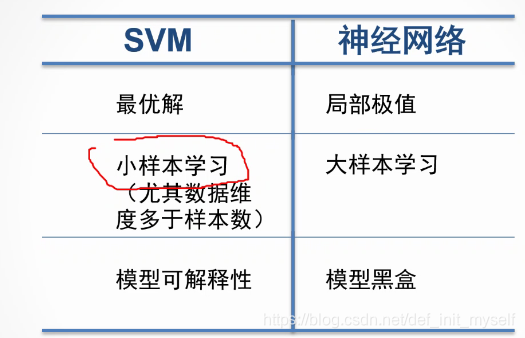
神经网络的模型黑盒导致很多严谨的地方不能用。比如航天。同时,比如dropout的存在让可复现性差。

















 4797
4797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









