




引言:网上关于大模型的文章也很多,但是都不太容易看懂。小枣君今天试着写一篇,争取做到通俗易懂。
废话不多说,我们直入主题。
█ 什么是大模型?
大模型,英文名叫Large Model,大型模型。早期的时候,也叫Foundation Model,基础模型。
大模型是一个简称。完整的叫法,应该是“人工智能预训练大模型”。预训练,是一项技术,我们后面再解释。
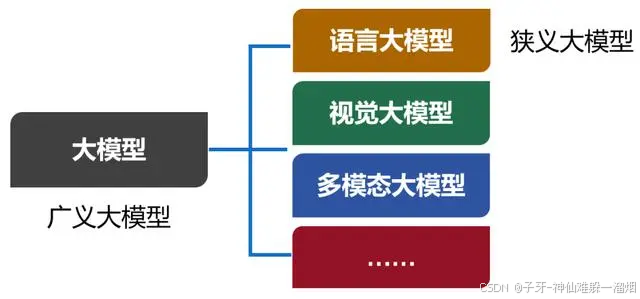
我们现在口头上常说的大模型,实际上特指大模型的其中一类,也是用得最多的一类——语言大模型(Large Language Model,也叫大语言模型,简称LLM)。
除了语言大模型之外,还有视觉大模型、多模态大模型等。现在,包括所有类别在内的大模型合集,被称为广义的大模型。而语言大模型,被称为狭义的大模型。
从本质来说,大模型,是包含超大规模参数(通常在十亿个以上)的神经网络模型。
之前给大家科普人工智能(链接)的时候,小枣君介绍过,神经网络是人工智能领域目前最基础的计算模型。它通过模拟大脑中神经元的连接方式,能够从输入数据中学习并生成有用的输出。
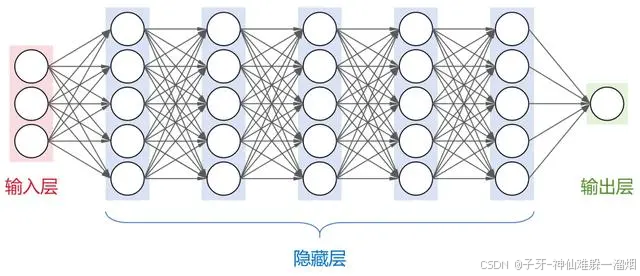
这是一个全连接神经网络(每层神经元与下一层的所有神经元都有连接),包括1个输入层,N个隐藏层,1个输出层。
大名鼎鼎的卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)以及transformer架构,都属于神经网络模型。
目前,业界大部分的大模型,都采用了transformer架构。
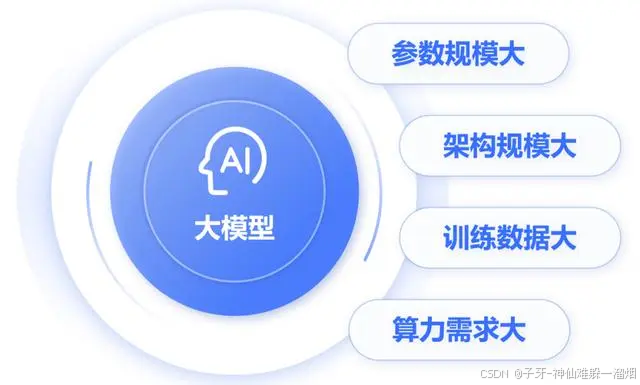
刚才提到,大模型包含了超大规模参数。实际上,大模型的“大”,不仅是参数规模大,还包括:架构规模大、训练数据大、算力需求大。
以OpenAI公司的GPT-3为例。这个大模型的隐藏层一共有96层,每层的神经元数量达到2048个。
整个架构的规模就很大(我可画不出来),神经元节点数量很多。
大模型的参数数量和神经元节点数有一定的关系。简单来说,神经元节点数越多,参数也就越多。例如,GPT-3的参数数量,大约是1750亿。
大模型的训练数据,也是非常庞大的。
同样以GPT-3为例,采用了45TB的文本数据进行训练。即便是清洗之后,也有570GB。具体来说,包括CC数据集(4千亿词)+WebText2(190亿词)+BookCorpus(670亿词)+维基百科(30亿词),绝对堪称海量。
最后是算力需求。
这个大家应该都听说过,训练大模型,需要大量的GPU算卡资源。而且,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









