



- 人工智能,机器学习,深度学习的关系

- 构成模型的三个关键要素:模型假设、评价函数(损失/优化目标)和优化算法
评价:对已知观测数据上的拟合效果好 - 机器学习
拟合一个大公式

- 深度学习
4.1神经网络的基本概念
4.2深度学习的发展历程
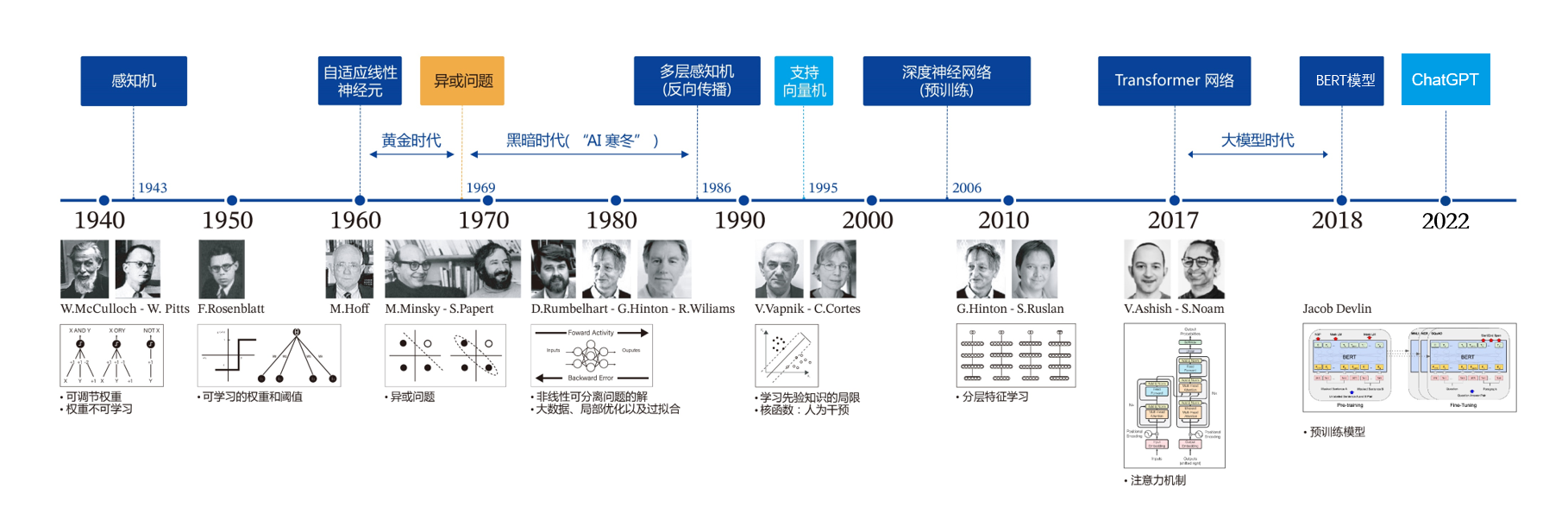
1940年代:首次提出神经元的结构,但权重是不可学的。
50-60年代:提出权重学习理论,神经元结构趋于完善,开启了神经网络的第一个黄金时代。
1969年:提出异或问题(人们惊讶的发现神经网络模型连简单的异或问题也无法解决,对其的期望从云端跌落到谷底),神经网络模型进入了被束之高阁的黑暗时代。
1986年:新提出的多层神经网络解决了异或问题,但随着90年代后理论更完备并且实践效果更好的SVM等机器学习模型的兴起,神经网络并未得到重视。
2010年左右:深度学习进入真正兴起时期。随着神经网络模型改进的技术在语音和计算机视觉任务上大放异彩,也逐渐被证明在更多的任务,如自然语言处理以及海量数据的任务上更加有效。至此,神经网络模型重新焕发生机,并有了一个更加响亮的名字:深度学习。
2017年-2021年:2017年,基于多头注意力机制的序列到序列模型Transformer在论文《Attention is all you need》中被提出。Transformer是一个具有里程碑意义的模型,它的提出催生了众多基于Transformer网络结构的模型,特别是在2018年预训练模型BERT(Bidirectional Encoder Representations from Transformers)的提出,其在多项NLP任务上均取得了突破性的进展。自此,不管是学术界,还是工业界均掀起了基于Transformer的预训练模型研究和应用的热潮,并且逐渐从NLP领域延伸到CV、语音等多项领域。
2022年之后:2022年Open AI的ChatGPT正式发布,2023年百度的文心一言正式发布,使得生成式大规模语言模型正式破圈,人工智能开始被千行百业了解,进入应用爆发时代。
备注:什么叫异或问题
线性不可分问题
(0,0)=1;(1,1)=1;(0,1)=0;(1,0)=0
用一条直线 将 0,0 和 1,1 分在一面,将 0,1和1,0 分在一面;是否能够做到;结论是做不到
深度学习学习笔记
最新推荐文章于 2025-12-25 16:43:46 发布

















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









