






学习视频:
YOLOV7改进-添加基于注意力机制的目标检测头(DYHEAD)_哔哩哔哩_bilibili
代码地址:
objectdetection_script/yolov5-dyhead.py at master · z1069614715/objectdetection_script (github.com)
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmcv.cnn import build_activation_layer, build_norm_layer
from mmcv.ops.modulated_deform_conv import ModulatedDeformConv2d
from mmengine.model import constant_init, normal_init
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
class h_swish(nn.Module):
def __init__(self, inplace=False):
super(h_swish, self).__init__()
self.inplace = inplace
def forward(self, x):
return x * F.relu6(x + 3.0, inplace=self.inplace) / 6.0
class h_sigmoid(nn.Module):
def __init__(self, inplace=True, h_max=1):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
self.h_max = h_max
def forward(self, x):
return self.relu(x + 3) * self.h_max / 6
class DyReLU(nn.Module):
def __init__(self, inp, reduction=4, lambda_a=1.0, K2=True, use_bias=True, use_spatial=False,
init_a=[1.0, 0.0], init_b=[0.0, 0.0]):
super(DyReLU, self).__init__()
self.oup = inp
self.lambda_a = lambda_a * 2
self.K2 = K2
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.use_bias = use_bias
if K2:
self.exp = 4 if use_bias else 2
else:
self.exp = 2 if use_bias else 1
self.init_a = init_a
self.init_b = init_b
# determine squeeze
if reduction == 4:
squeeze = inp // reduction
else:
squeeze = _make_divisible(inp // reduction, 4)
# print('reduction: {}, squeeze: {}/{}'.format(reduction, inp, squeeze))
# print('init_a: {}, init_b: {}'.format(self.init_a, self.init_b))
self.fc = nn.Sequential(
nn.Linear(inp, squeeze),
nn.ReLU(inplace=True),
nn.Linear(squeeze, self.oup * self.exp),
h_sigmoid()
)
if use_spatial:
self.spa = nn.Sequential(
nn.Conv2d(inp, 1, kernel_size=1),
nn.BatchNorm2d(1),
)
else:
self.spa = None
def forward(self, x):
if isinstance(x, list):
x_in = x[0]
x_out = x[1]
else:
x_in = x
x_out = x
b, c, h, w = x_in.size()
y = self.avg_pool(x_in).view(b, c)
y = self.fc(y).view(b, self.oup * self.exp, 1, 1)
if self.exp == 4:
a1, b1, a2, b2 = torch.split(y, self.oup, dim=1)
a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0] # 1.0
a2 = (a2 - 0.5) * self.lambda_a + self.init_a[1]
b1 = b1 - 0.5 + self.init_b[0]
b2 = b2 - 0.5 + self.init_b[1]
out = torch.max(x_out * a1 + b1, x_out * a2 + b2)
elif self.exp == 2:
if self.use_bias: # bias but not PL
a1, b1 = torch.split(y, self.oup, dim=1)
a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0] # 1.0
b1 = b1 - 0.5 + self.init_b[0]
out = x_out * a1 + b1
else:
a1, a2 = torch.split(y, self.oup, dim=1)
a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0] # 1.0
a2 = (a2 - 0.5) * self.lambda_a + self.init_a[1]
out = torch.max(x_out * a1, x_out * a2)
elif self.exp == 1:
a1 = y
a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0] # 1.0
out = x_out * a1
if self.spa:
ys = self.spa(x_in).view(b, -1)
ys = F.softmax(ys, dim=1).view(b, 1, h, w) * h * w
ys = F.hardtanh(ys, 0, 3, inplace=True)/3
out = out * ys
return out
class DyDCNv2(nn.Module):
"""ModulatedDeformConv2d with normalization layer used in DyHead.
This module cannot be configured with `conv_cfg=dict(type='DCNv2')`
because DyHead calculates offset and mask from middle-level feature.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
stride (int | tuple[int], optional): Stride of the convolution.
Default: 1.
norm_cfg (dict, optional): Config dict for normalization layer.
Default: dict(type='GN', num_groups=16, requires_grad=True).
"""
def __init__(self,
in_channels,
out_channels,
stride=1,
norm_cfg=dict(type='GN', num_groups=16, requires_grad=True)):
super().__init__()
self.with_norm = norm_cfg is not None
bias = not self.with_norm
self.conv = ModulatedDeformConv2d(
in_channels, out_channels, 3, stride=stride, padding=1, bias=bias)
if self.with_norm:
self.norm = build_norm_layer(norm_cfg, out_channels)[1]
def forward(self, x, offset, mask):
"""Forward function."""
x = self.conv(x.contiguous(), offset, mask)
if self.with_norm:
x = self.norm(x)
return x
class DyHeadBlock(nn.Module):
"""DyHead Block with three types of attention.
HSigmoid arguments in default act_cfg follow official code, not paper.
https://github.com/microsoft/DynamicHead/blob/master/dyhead/dyrelu.py
"""
def __init__(self,
in_channels,
norm_type='GN',
zero_init_offset=True,
act_cfg=dict(type='HSigmoid', bias=3.0, divisor=6.0)):
super().__init__()
self.zero_init_offset = zero_init_offset
# (offset_x, offset_y, mask) * kernel_size_y * kernel_size_x
self.offset_and_mask_dim = 3 * 3 * 3
self.offset_dim = 2 * 3 * 3
if norm_type == 'GN':
norm_dict = dict(type='GN', num_groups=16, requires_grad=True)
elif norm_type == 'BN':
norm_dict = dict(type='BN', requires_grad=True)
self.spatial_conv_high = DyDCNv2(in_channels, in_channels, norm_cfg=norm_dict)
self.spatial_conv_mid = DyDCNv2(in_channels, in_channels)
self.spatial_conv_low = DyDCNv2(in_channels, in_channels, stride=2)
self.spatial_conv_offset = nn.Conv2d(
in_channels, self.offset_and_mask_dim, 3, padding=1)
self.scale_attn_module = nn.Sequential(
nn.AdaptiveAvgPool2d(1), nn.Conv2d(in_channels, 1, 1),
nn.ReLU(inplace=True), build_activation_layer(act_cfg))
self.task_attn_module = DyReLU(in_channels)
self._init_weights()
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
normal_init(m, 0, 0.01)
if self.zero_init_offset:
constant_init(self.spatial_conv_offset, 0)
def forward(self, x):
"""Forward function."""
outs = []
for level in range(len(x)):
# calculate offset and mask of DCNv2 from middle-level feature
offset_and_mask = self.spatial_conv_offset(x[level])
offset = offset_and_mask[:, :self.offset_dim, :, :]
mask = offset_and_mask[:, self.offset_dim:, :, :].sigmoid()
mid_feat = self.spatial_conv_mid(x[level], offset, mask)
sum_feat = mid_feat * self.scale_attn_module(mid_feat)
summed_levels = 1
if level > 0:
low_feat = self.spatial_conv_low(x[level - 1], offset, mask)
sum_feat += low_feat * self.scale_attn_module(low_feat)
summed_levels += 1
if level < len(x) - 1:
# this upsample order is weird, but faster than natural order
# https://github.com/microsoft/DynamicHead/issues/25
high_feat = F.interpolate(
self.spatial_conv_high(x[level + 1], offset, mask),
size=x[level].shape[-2:],
mode='bilinear',
align_corners=True)
sum_feat += high_feat * self.scale_attn_module(high_feat)
summed_levels += 1
outs.append(self.task_attn_module(sum_feat / summed_levels))
return outs
[17, 1, Conv, [128, 1, 1]],
[20, 1, Conv, [128, 1, 1]],
[23, 1, Conv, [128, 1, 1]],
[[24, 25, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
self.dyhead = nn.Sequential(*[DyHeadBlock(ch[0]) for i in range(2)])
for dyhead_layer in self.dyhead:
x = dyhead_layer(x)先安装需要的
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"然后将前228行代码复制,在models文件夹下新建一个dyhead.py文件粘贴进去
在yolo.py文件中导入
from models.dyhead import DyHeadBlock修改IDetect类
在这里
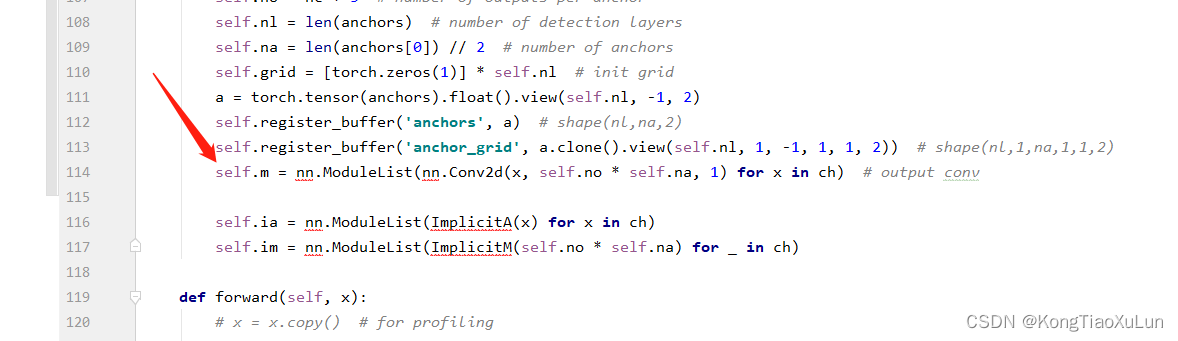 加上
加上
self.dyhead = nn.Sequential(*[DyHeadBlock(ch[0]) for i in range(2)])原论文中6是最好的,修改1,2,4,6自行实验
在这里
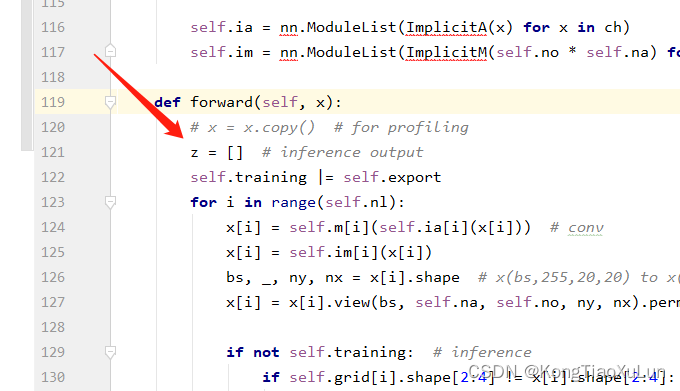
加上
for dyhead_layer in self.dyhead:
x = dyhead_layer(x)在yolov7.yaml文件中,IDetect前有三个RepConv
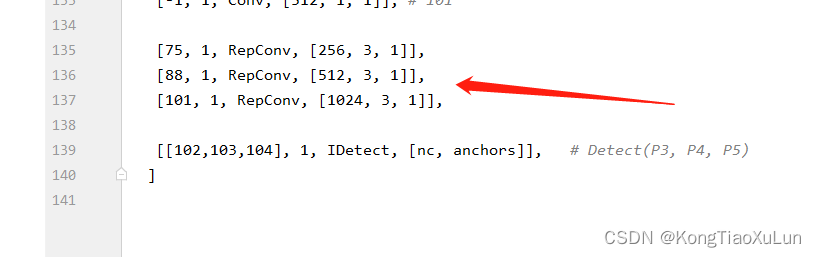
将三个层的通道数改为一致的,例如256,515,1024,可能调大了会跑不动

















 6102
6102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









