







 超级会员免费看
超级会员免费看
 本文全面综述了自动驾驶领域的多模态感知,特别是相机和激光雷达融合技术。研究了现有的融合方法,如前融合、深度融合、后融合和非对称融合,并探讨了数据对齐、信息丢失和语义鸿沟等问题。文章分析了不同融合阶段的特点,指出当前挑战,包括域偏差和数据分辨率不匹配,并引用了相关研究工作,为未来的研究方向提供了启示。
本文全面综述了自动驾驶领域的多模态感知,特别是相机和激光雷达融合技术。研究了现有的融合方法,如前融合、深度融合、后融合和非对称融合,并探讨了数据对齐、信息丢失和语义鸿沟等问题。文章分析了不同融合阶段的特点,指出当前挑战,包括域偏差和数据分辨率不匹配,并引用了相关研究工作,为未来的研究方向提供了启示。
数据集:
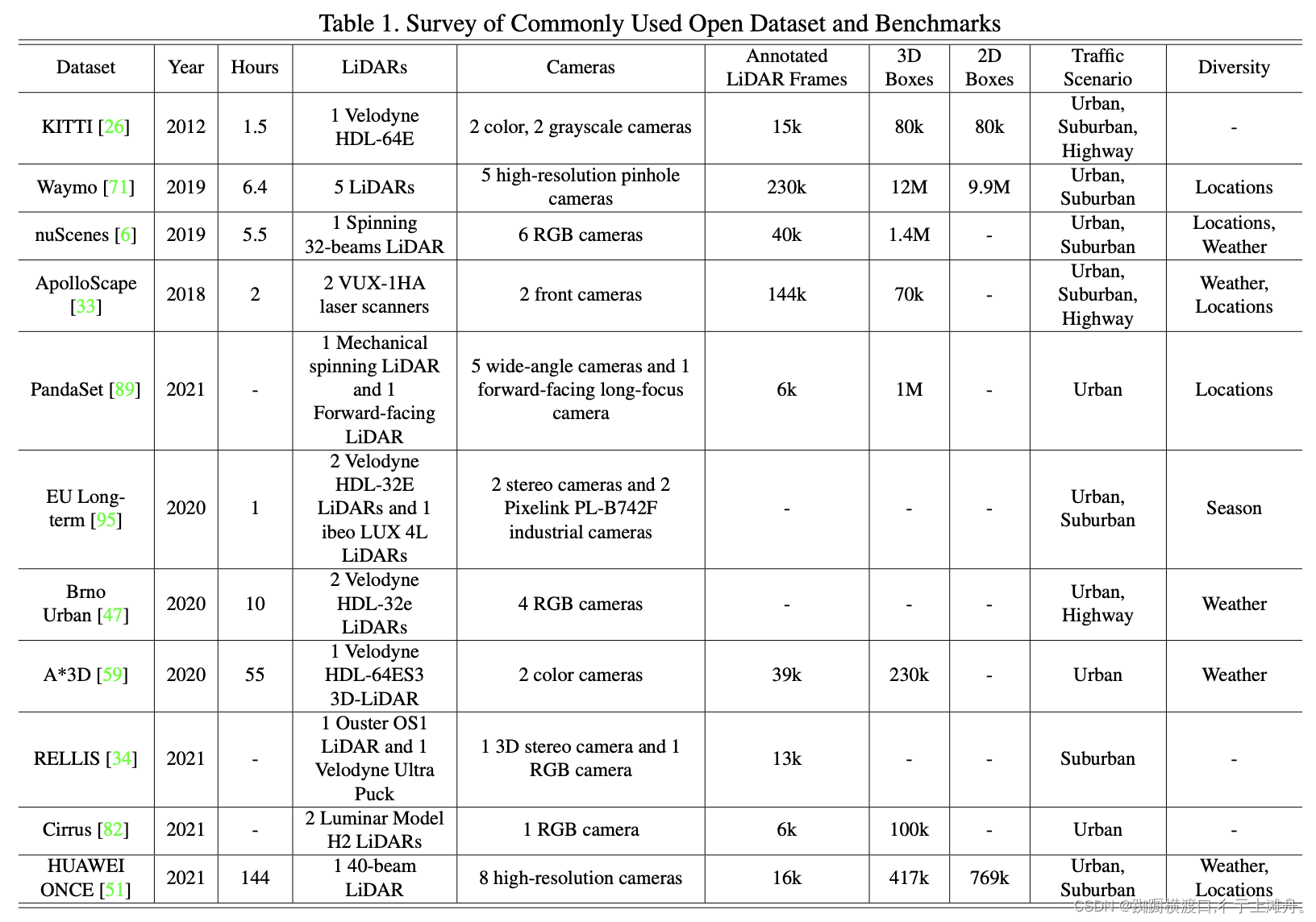
多模态融合是感知自动驾驶系统的一项基本任务,最近引起了许多研究人员的兴趣。然而,由于原始数据噪声大、信息利用率低以及多模态传感器的无对准,达到相当好的性能并非易事。本文对现有的基于多模态自动驾驶感知任务方法进行了文献综述。分析超过50篇论文,包括摄像头和激光雷达,试图解决目标检测和语义分割任务。与传统的融合模型分类方法不同,作者从融合阶段的角度,通过更合理的分类法将融合模型分为两大类,四小类。此外,研究了当前的融合方法,就潜在的研究机会展开讨论。
最近,用于自动驾驶感知任务的多模态融合方法发展迅速,其从跨模态特征表示和更可靠的模态传感器,到更复杂、更稳健的多模态融合深度学习模型和技术。然而,只有少数文献综述集中在多模态融合方法本身的方法论上,大多数文献都遵循传统规则,将其分为前融合、深度(特征)融合和后融合三大类,重点关注深度学习模型中融合特征的阶段,无论是数据级、特征级还是提议级。首先,这种分类法没有明确定义每个级别的特征表示。其次,它表明,激光雷达和摄像头这两个分支在处理过程中始终是对称的,模糊了激光雷达分支中融合提议级特征和摄像头分支中融合数据级特征的情况。综上所述,传统的分类法可能是直观的,但对于总结最近出现的越来越多的多模态融合方法来说却很落后,这使得研究人员无法从系统的角度对其进行研究和分析。
如图是自动驾驶感知任务的示意图:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2861
2861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











