



Redisson 详解
Redisson定义:
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
为什么使用Redission
普通锁何分布式锁的对比:
|
对比维度 |
普通锁(本地锁) |
分布式锁 |
|
作用范围 |
单个 JVM 进程内 |
多个 JVM / 多台服务器之间 |
|
典型实现 |
synchronized、ReentrantLock |
Redisson、ZooKeeper、etcd |
|
数据共享方式 |
内存(JVM堆) |
共享存储(如 Redis、数据库) |
|
适用场景 |
单机应用、单服务实例 |
分布式系统、微服务集群 |
|
是否跨进程 |
❌ 否 |
✅ 是 |
|
容错性 |
低(进程挂掉即失效) |
高(支持自动续期、故障恢复) |
|
并发控制 |
线程级 |
服务实例级 |
|
可重入 |
支持 |
Redisson 支持 |
|
自动续期 |
无 |
Redisson Watchdog 支持 |
|
容错性 |
差 |
好(有过期机制) |
|
性能 |
极高(纳秒级) |
较高(依赖网络) |
场景分析
|
场景 |
是否需要分布式锁 |
说明 |
|
单体应用部署一台服务器 |
❌ 不需要 |
用 synchronized 即可 |
|
订单服务部署在 3 台机器上 |
✅ 需要 |
防止重复下单、超卖 |
|
缓存重建防止雪崩 |
✅ 需要 |
只让一个节点重建缓存 |
|
定时任务避免重复执行 |
✅ 需要 |
使用分布式锁确保只有一个实例运行 |
在分布式的情况下,由于不同服务器之见不共享内存空间,所以普通锁难以保障线程安全。
因此就需要Redission,由于它是将Redis作为了中间件使用,因此不论是哪台服务器访问,由于它的底层机制,所以可以实现分布式情况下的锁,保障线程安全。
如何在Java中使用Redission
Tips: @Autowired 和 @Resource 的区别
|
特性 |
@Autowired |
@Resource |
|
来源 |
Spring 框架 |
Java 标准(JSR-250) |
|
默认注入方式 |
按类型(byType) |
按名称(byName) |
|
如何指定 Bean |
@Qualifier("name") |
@Resource(name="name") |
|
是否支持 required=false |
✅ 是 |
❌ 否(始终 required) |
|
容错性 |
多个同类型 Bean 会报错 |
名称优先,更精确 |
|
推荐使用场景 |
Spring 项目内部,构造器注入 |
需要精确控制 Bean 名称时 |
假设我们有两个 UserService 实现:
@Component("userServiceImplA")
public class UserServiceImplA implements UserService { }
@Component("userServiceImplB")
public class UserServiceImplB implements UserService { }
使用 @Autowired 必须加 @Qualifier
@Autowired
@Qualifier("userServiceImplA")
private UserService userService;
使用 @Resource 可直接指定 name
@Resource(name = "userServiceImplA")
private UserService userService;
或者字段名匹配即可:
@Resource
private UserService userServiceImplA; // 字段名 = Bean 名 → 自动注入
正文
- 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
- 配置 Redission客户端
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://你的服务器地址:端口号一般为6379")
.setPassword("你的redis密码");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
- 在项目中使用
@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{
//获取锁(可重入),指定锁的名称
RLock lock = redissonClient.getLock("anyLock");
//尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
boolean isLock = lock.tryLock(1,10,TimeUnit.SECONDS);
//判断获取锁成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
代码示例对比
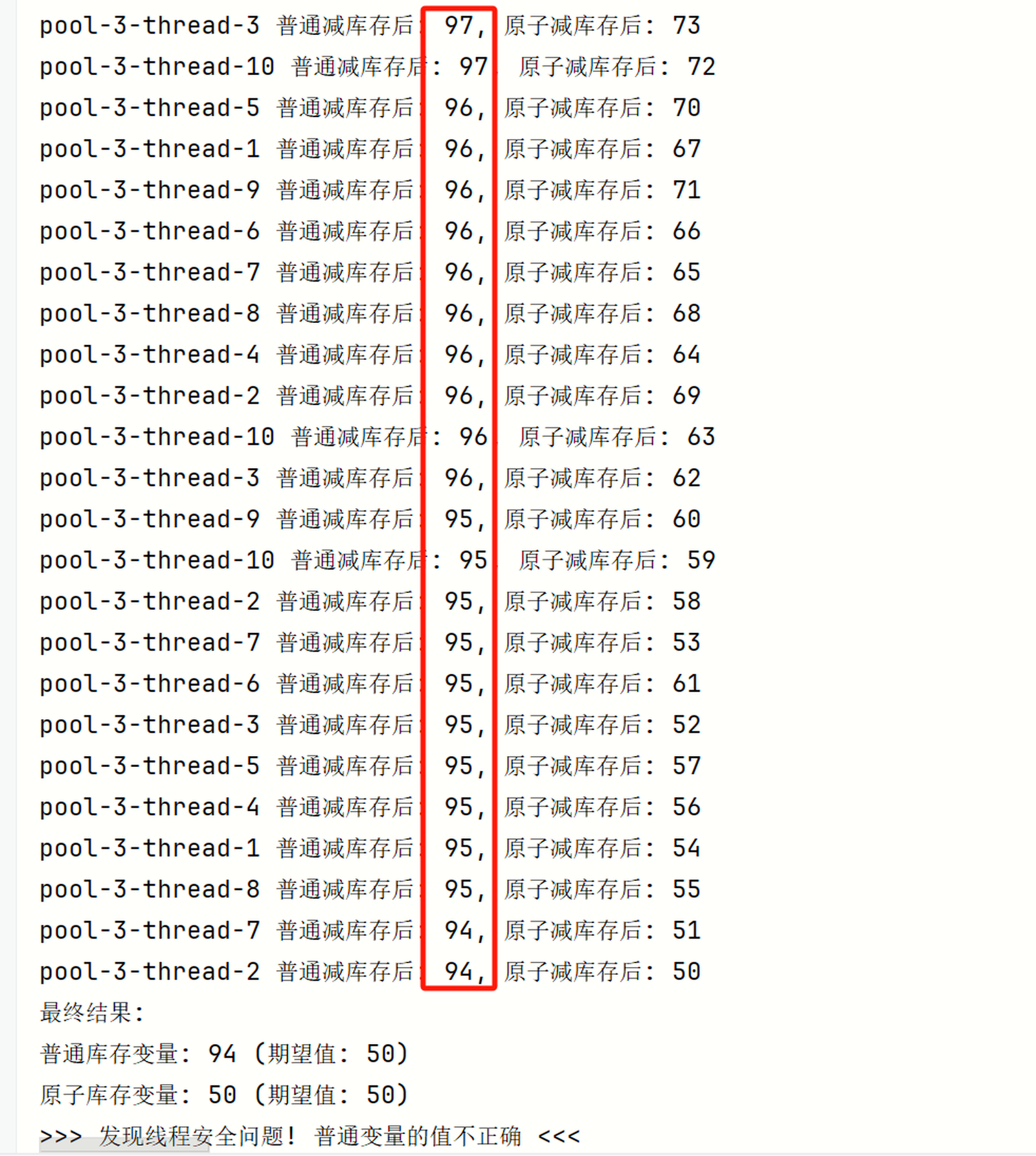
线程不安全,不加锁演示
/** * 演示线程不安全的操作 * 多个线程同时减库存,但没有加锁保护 */
public void demonstrateThreadSafetyIssue() throws InterruptedException {
System.out.println("=== 线程安全问题演示 ===");
System.out.println("初始库存: " + inventory);
// 定义线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(10);
// 10个线程同时尝试减库存 for (int i = 0; i < 10; i++) {
executor.submit(() -> {
try {
// 每个线程尝试减5个库存
for (int j = 0; j < 5; j++) {
// 错误示例:没有加锁保护的共享资源访问
int current = inventory;
Thread.sleep(1); // 模拟一些处理时间,增加并发冲突概率 inventory = current - 1;
// 正确示例:使用原子操作
int atomicCurrent = atomicInventory.decrementAndGet();
System.out.println(Thread.currentThread().getName() +
" 普通减库存后: " + inventory +
", 原子减库存后: " + atomicCurrent);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
latch.countDown();
}
});
}
// 等待所有线程执行完毕 latch.await();
executor.shutdown();
System.out.println("最终结果:");
System.out.println("普通库存变量: " + inventory + " (期望值: 50)");
System.out.println("原子库存变量: " + atomicInventory.get() + " (期望值: 50)");
if (inventory != 50) {
System.out.println(">>> 发现线程安全问题! 普通变量的值不正确 <<<");
}
}
加锁
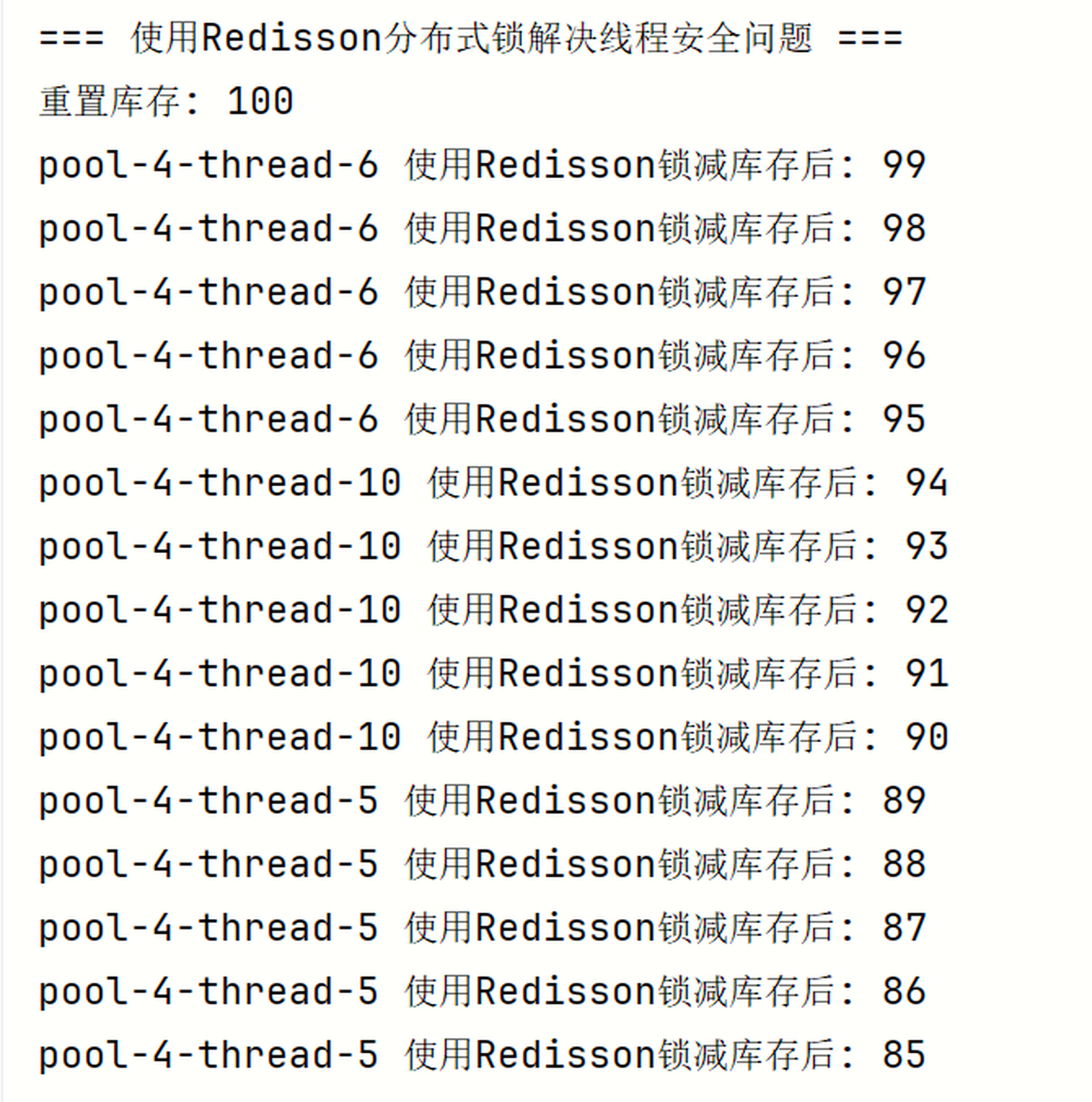
/** * 演示使用Redisson分布式锁解决线程安全问题 */
public void demonstrateRedissonSolution() throws InterruptedException {
System.out.println("\n=== 使用Redisson分布式锁解决线程安全问题 ===");
inventory = 100; // 重置库存 System.out.println("重置库存: " + inventory);
ExecutorService executor = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(10);
// 10个线程同时尝试减库存,但这次使用Redisson分布式锁
for (int i = 0; i < 10; i++) {
executor.submit(() -> {
try {
// 每个线程尝试减5个库存
for (int j = 0; j < 5; j++) {
// 使用Redisson分布式锁保护临界区 org.redisson.api.RLock lock = redissonClient.getLock("inventoryLock");
try {
// 尝试获取锁,最多等待3秒,持有锁10秒
if (lock.tryLock(3, 10, java.util.concurrent.TimeUnit.SECONDS)) {
try {
// 锁保护的临界区
int current = inventory;
Thread.sleep(1); // 模拟一些处理时间 inventory = current - 1;
System.out.println(Thread.currentThread().getName() +
" 使用Redisson锁减库存后: " + inventory);
} finally {
lock.unlock(); // 释放锁 }
} else {
System.out.println(Thread.currentThread().getName() + " 获取锁失败");
}
} catch (Exception e) {
e.printStackTrace();
}
}
} finally {
latch.countDown();
}
});
}
// 等待所有线程执行完毕 latch.await();
executor.shutdown();
System.out.println("使用Redisson锁保护后的最终库存: " + inventory + " (期望值: 50)");
if (inventory == 50) {
System.out.println(">>> 使用Redisson分布式锁成功解决了线程安全问题! <<<");
}
}
详解代码
ExecutorService executor = Executors.newFixedThreadPool(10);用于从线程池中获取十个线程对象
什么是线程池
很简单,简单看名字就知道是装有线程的池子,我们可以把要执行的多线程交给线程池来处理,和连接池的概念一样,通过维护一定数量的线程池来达到多个线程的复用。
线程池的好处:
我们知道不用线程池的话,每个线程都要通过 new Thread(xxRunnable).start()的方式来创建并运行一个线程,线程少的话这不会是问题,而真实环境可能会开启多个线程让系统和程序达到最佳效率,当线程数达到一定数量就会耗尽系统的CPU和内存资源,也会造成 GC频繁收集和停顿,因为每次创建和销毁一个线程都是要消耗系统资源的,如果为每个任务都创建线程这无疑是一个很大的性能瓶颈。所以,线程池中的线程复用极大节省了系统资源,当线程一段时间不再有任务处理时它也会自动销毁,而不会长驻内存。线程池核心类在java.util.concurrent 包中我们能找到线程池的定义,其中ThreadPoolExecutor 是我们线程池核心类,首先看看线程池类的主要参数有哪些。如何提交线程如可以 先 随 便 定 义 一 个 固 定 大 小 的 线 程池ExecutorService es =Executors.newFixedThreadPool(3);提交一个线程es.submit(xxRunnble);es.execute(xxRunnble);
submit 和 execute 分别有什么区别呢?
execute 没有返回值,如果不需要知道线程的结果就使用execute 方法,性能会好很多。submit 返回一个 Future 对象,如果想知道线程结果就使用submit 提交,而且它能在主线程中通过 Future 的 get 方法捕获线程中的异常。如何关闭线程池es.shutdown();不再接受新的任务,之前提交的任务等执行结束再关闭线程池。es.shutdownNow();不再接受新的任务,试图停止池中的任务再关闭线程池,返回所有未处理的线程list 列表
private static AtomicInteger atomicSharedResource = new AtomicInteger(0);
volatile
一个非常重要的问题,是每个学习、应用多线程的 Java 程序员都必须掌握的。理解 volatile关键字的作用的前提是要理解 Java 内存模型,这里就不讲Java 内存模型了,可以参见第31 点,volatile 关键字的作用主要有两个:
1、多线程主要围绕可见性和原子性两个特性而展开,使用volatile 关键字修饰的变量,保证了其在多线程之间的可见性,即每次读取到 volatile 变量,一定是最新的数据
2、代码底层执行不像我们看到的高级语言----Java 程序这么简单,它的执行是Java代码–>字节码–>根据字节码执行对应的 C/C++代码–>C/C++代码被编译成汇编语言–>和硬件电路交互,现实中,为了获取更好的性能 JVM可能会对指令进行重排序,多线程下可能会出现一些意想不到的问题。使用 volatile 则会对禁止语义重排序,当然这也一定程度上降低了代码执行效率从实践角度而言,volatile 的一个重要 作 用 就 是 和 CAS 结 合 , 保 证 了 原 子 性,详细的可以参见java.util.concurrent.atomic 包下的类,比如 AtomicInteger。
CAS算法
CAS,全称为 Compare and Swap,即比较-替换。假设有三个操作数:内存值V、旧的预期值 A、要修改的值 B,当且仅当预期值 A 和内存值V 相同时,才会将内存值修改为 B 并返回 true,否则什么都不做并返回 false。当然CAS 一定要volatile变量配合,这样才能保证每次拿到的变量是主内存中最新的那个值,否则旧的预期值 A 对某条线程来说,永远是一个不会变的值 A,只要某次CAS 操作失败,永远都不可能成功。java.util.concurrent.atomic 包下面的 Atom****类都有 CAS 算法的应用。
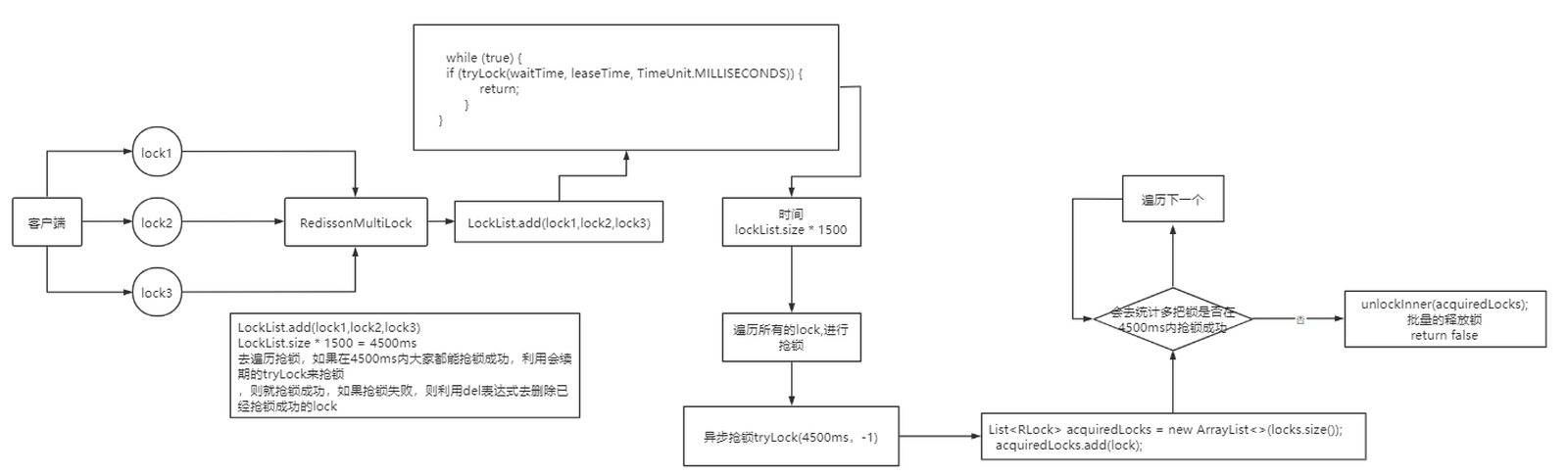
分布式锁-redission锁的MutiLock原理
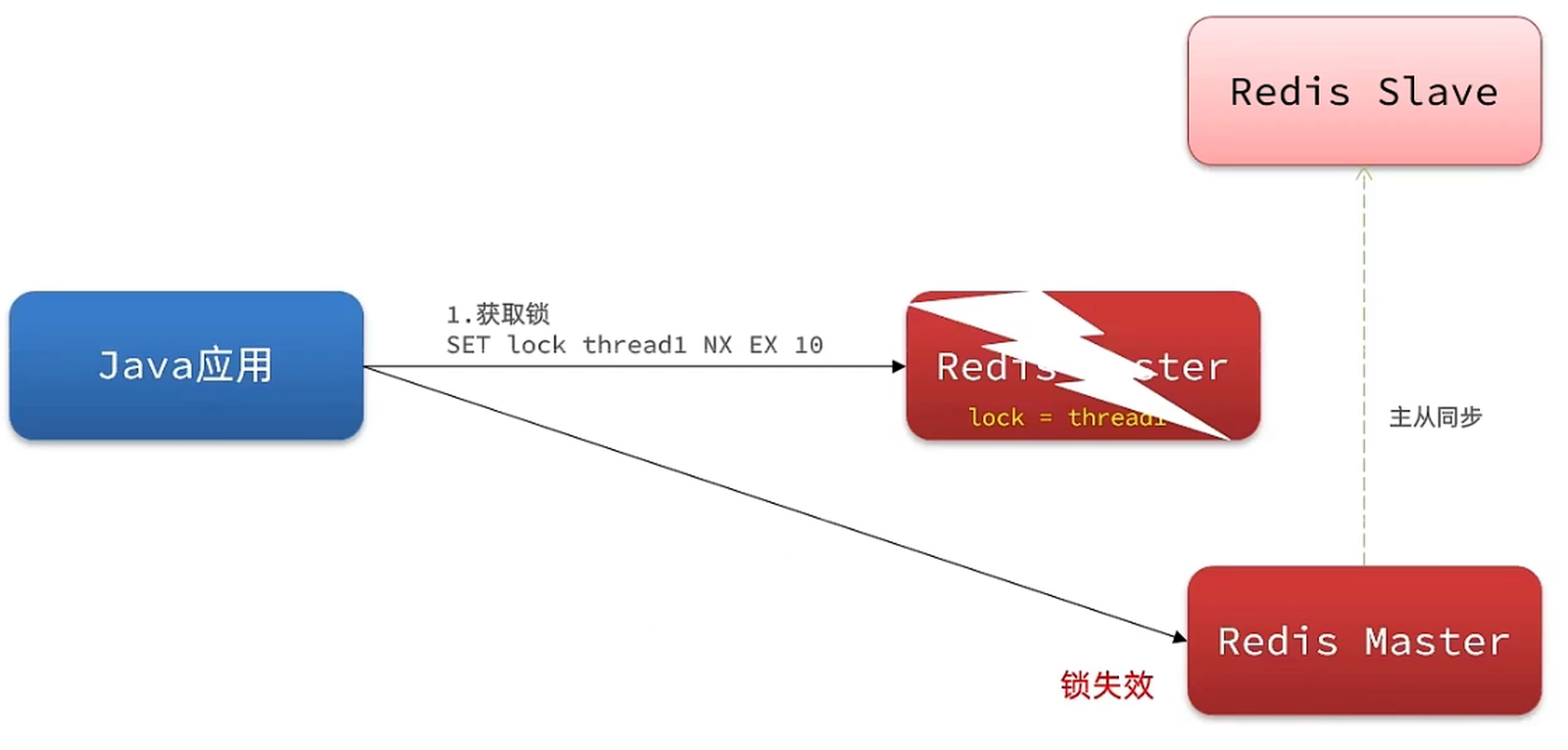
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
为了解决这个问题,redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
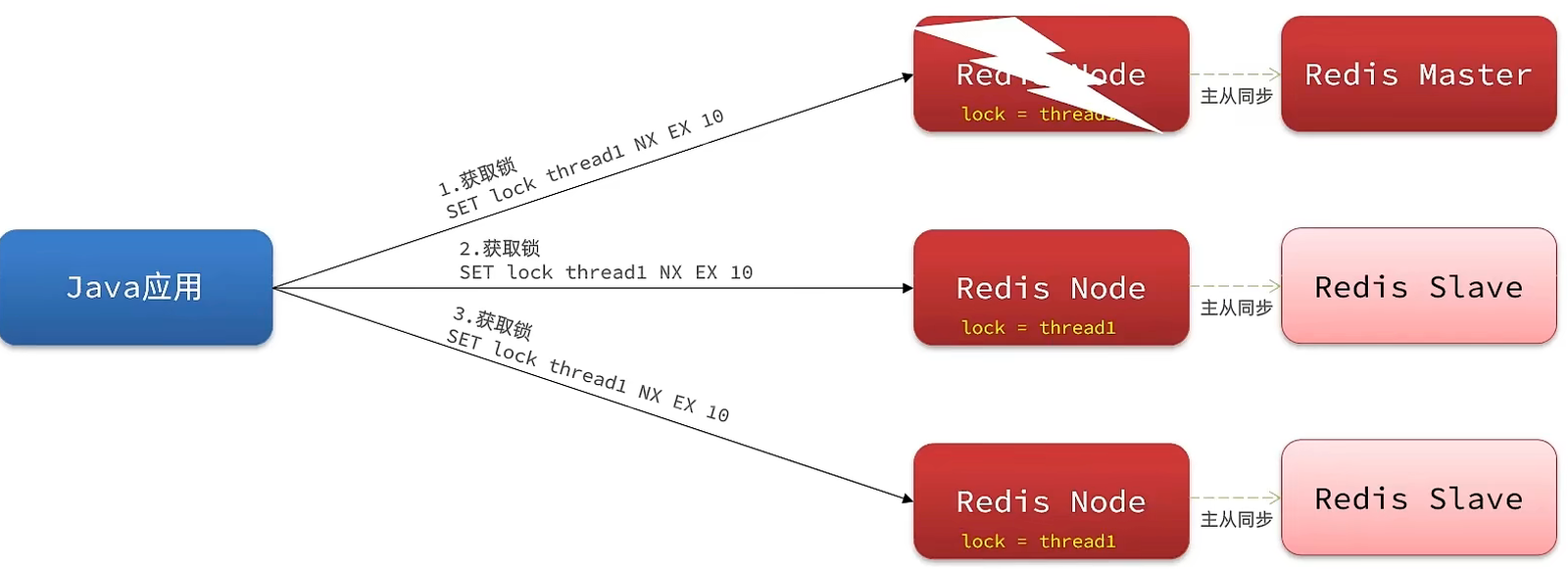
那么MutiLock 加锁原理是什么呢?笔者画了一幅图来说明
当我们去设置了多个锁时,redission会将多个锁添加到一个集合中,然后用while循环去不停去尝试拿锁,但是会有一个总共的加锁时间,这个时间是用需要加锁的个数 * 1500ms ,假设有3个锁,那么时间就是4500ms,假设在这4500ms内,所有的锁都加锁成功, 那么此时才算是加锁成功,如果在4500ms有线程加锁失败,则会再次去进行重试.


















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









