




GroupMamba解析
Shaker A, Wasim S T, Khan S, et al. GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model[J]. arXiv preprint arXiv:2407.13772, 2024.
1.论文解析
本文核心思想:VMamba四向扫描和SeNet注意力机制结合,结构参考Swin-Transformer方式。
初衷是解决基于状态空间模型(SSMs)在计算机视觉任务中的稳定性和效率问题。通过创新的调制组 Mamba 层、通道亲和调制算子和蒸馏训练目标,在多个视觉任务上取得了优异性能。
1.1 研究背景与动机
- 状态空间模型在处理长程依赖方面有潜力,但在计算机视觉任务中,基于 SSMs 的模型面临稳定性和性能优化挑战。例如 Mamba 模型在图像分类等任务中,当参数规模扩大时不稳定,且其 VSS 块在通道维度上的参数和计算复杂度较高。
- 卷积神经网络、视觉 Transformer 等方法在计算机视觉领域不断发展,但仍存在改进空间,促使研究人员探索新的模型结构。
1.2 相关工作
- 卷积神经网络(ConvNets)经历了多次架构演进,ConvNeXt 等变体在性能上不断提升。
- 视觉 Transformer(ViT)及其衍生模型对计算机视觉任务产生了重要影响,同时也引发了对注意力机制复杂度的研究,推动了高效变体的发展。
- 状态空间模型(SSMs)逐渐成为 ViT 的替代方案,如 S4、Mamba 等模型被提出,在视觉领域也有了多种应用,但仍需解决一些固有问题。
1.3 方法
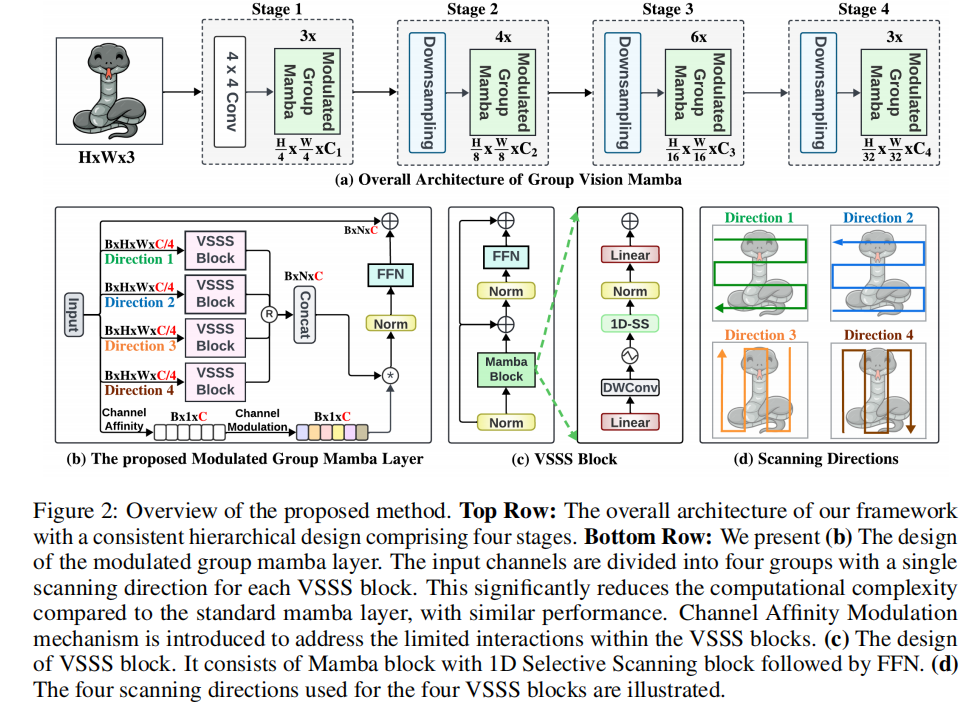
- 整体架构:采用类似 Swin Transformer 的分层架构,分为四个阶段。输入图像先经过 Patch Embedding 层划分为不重叠的补丁并嵌入特征向量,然后依次通过多个调制组 Mamba 块和下采样层进行处理。
- 调制组 Mamba 层
- VSSS 块:基于 Mamba 算子的令牌和通道混合器,包含 Mamba 操作和前馈网络(FFN),对输入令牌序列进行处理。
- 分组 Mamba 操作:受分组卷积启发,将输入通道分为四组,每组应用独立的 VSSS 块,并在四个不同方向进行扫描,以更好地建模空间依赖关系,最后将结果拼接。(就是VMama,从代码上也是)
- 通道亲和调制(CAM):为解决分组操作导致的通道间信息交换有限问题,通过平均池化计算通道统计信息,经亲和计算后重新校准分组 Mamba 算子的输出。(本质就是SENET,换了个名字)
- 蒸馏损失函数:针对 Mamba 训练在大模型时不稳定的问题,采用蒸馏目标与标准交叉熵目标相结合的方式。通过最小化学生模型与教师模型(RegNetY - 16G)的分类损失和蒸馏损失之和来训练模型,稳定训练过程并提升性能。
1.4 实验结果
-
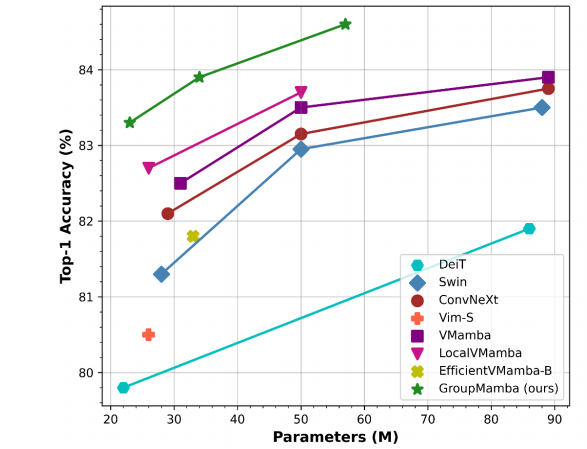
图像分类:在 ImageNet-1K 数据集上,GroupMamba-T、-S、-B 模型分别在不同参数规模下取得了较高的准确率,如 GroupMamba-T 以 2300 万参数和 4.5 GFLOPs 实现了 83.3% 的 top - 1 准确率,优于 ConvNeXt-T、Swin-T 等模型,且相比同类 SSM 模型 VMamba-T 参数减少 26%。
-
对象检测和实例分割:在 MS - COCO 2017 数据集上,基于 Mask-RCNN 框架,GroupMamb-T 模型的 box AP 为 47.6,mask AP 为 42.9,超越了 ResNet-50、Swin-T 等模型,且参数比 VMamba-T 少 20%。
-
语义分割:在 ADE20K 数据集上,GroupMamba-T 模型在单尺度和多尺度评估下的 mIoU 分别为 48.6 和 49.2,以 4900 万参数和 955G FLOPs 超越了 ResNet-50、Swin-T 等模型及相关 SSM 方法。
-
消融研究:实验表明 CAM 模块和蒸馏损失函数均对模型性能有提升作用,如 GroupMamba - T 在加入 CAM 模块后准确率提升 0.3%,加入蒸馏损失函数且不增加通道数时,相比 VMamba - T 性能提升 0.8% 且参数减少 26%。
2.源码解析
2.1 GroupMamba.py
核心代码在models/groupmamba.py
FFN类
就是一个普通的FC-GeLu-FC模块
class FFN(nn.Module):
def __init__(self, in_features, hidden_features):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, in_features)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return x
PVT2FFN
就是一个FC-分组卷积-GELU-FC模块
class PVT2FFN(nn.Module):
def __init__(self, in_features, hidden_features):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, in_features)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.fc2(x)
return x
GroupMambaLayer
这是论文的核心模块,实现的就是下图,类似于SE和Mamba结合。输入进来后分为三个并行分支,每个分支输入相同,分支1输入沿通道切分为四份,分别经过不同的Mamba沿着不同方向扫描处理后合并;分支2就是SE Net;分支1和分之2完成注意力加权;分支3是残差连接。
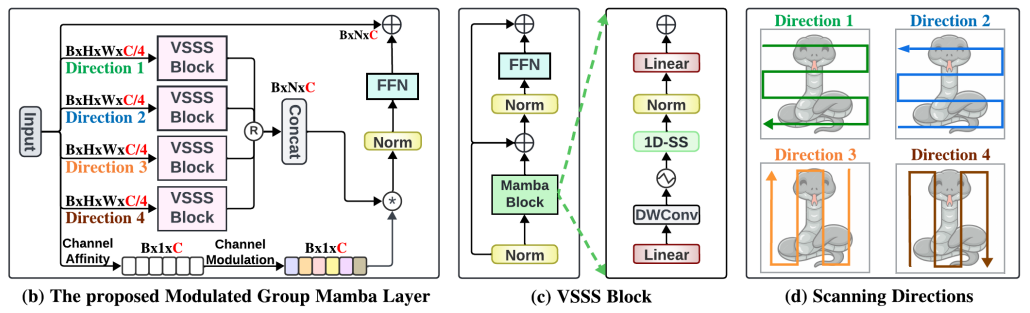
class GroupMambaLayer(nn.Module):
def __init__(self, input_dim, output_dim, d_state=1, d_conv=3, expand=1, reduction=16):
super().__init__()
# 计算降维后的通道数
num_channels_reduced = input_dim // reduction
# 定义第一个全连接层,将输入维度映射到降维后的通道数,包含偏置
self.fc1 = nn.Linear(input_dim, num_channels_reduced, bias=True)
# 定义第二个全连接层,将降维后的通道数映射回输出维度,包含偏置
self.fc2 = nn.Linear(num_channels_reduced, output_dim, bias=True)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
# 保存输入和输出维度
self.input_dim = input_dim
self.output_dim = output_dim
# 定义层归一化,应用于输入维度
self.norm = nn.LayerNorm(input_dim)
# 定义四个 SS2D 模块,每个模块维度为输入维度的四分之一
self.mamba_g1 = SS2D(
d_model=input_dim // 4,
d_state=d_state,
ssm_ratio=expand,
d_conv=d_conv
)
self.mamba_g2 = SS2D(
d_model=input_dim // 4,
d_state=d_state,
ssm_ratio=expand,
d_conv=d_conv
)
self.mamba_g3 = SS2D(
d_model=input_dim // 4,
d_state=d_state,
ssm_ratio=expand,
d_conv=d_conv
)
self.mamba_g4 = SS2D(
d_model=input_dim // 4,
d_state=d_state,
ssm_ratio=expand,
d_conv=d_conv
)
# 定义投影层,将输入维度映射到输出维度
self.proj = nn.Linear(input_dim, output_dim)
# 定义一个可训练的跳跃连接缩放参数,初始值为1
self.skip_scale = nn.Parameter(torch.ones(1))
def forward(self, x, H, W):
# 如果输入张量的数据类型是 float16,则转换为 float32
if x.dtype == torch.float16:
x = x.type(torch.float32)
# 获取输入张量的批量大小 B、序列长度 N 和通道数 C
B, N, C = x.shape
# 对输入张量进行层归一化
x = self.norm(x)
# Channel Affinity
# [B, N, C] -> [B, C, N]->[B,C]
# 将输入张量 [B, N, C] 转换为 [B, C, N],
# 然后在序列维度上取均值,得到 [B, C]
z = x.permute(0, 2, 1).mean(dim=2)
# [B, C]->[B,output_dim]
# 通过第一个全连接层,并应用 ReLU 激活,得到 [B, output_dim]
fc_out_1 = self.relu(self.fc1(z))
# 通过第二个全连接层,并应用 Sigmoid 激活,得到 [B, output_dim]
fc_out_2 = self.sigmoid(self.fc2(fc_out_1))
# 将输入张量重新排列为 [B, H, W, C]
x = rearrange(x, 'b (h w) c -> b h w c', b=B, h=H, w=W, c=C)
# 将通道维度均分为四部分,分别赋值给 x1, x2, x3, x4
x1, x2, x3, x4 = torch.chunk(x, 4, dim=-1)
# 对四个不同方向应用四个 SS2D 扫描,每个扫描应用于 N/4 个通道
x_mamba1 = self.mamba_g1(x1, CrossScan=CrossScan_1, CrossMerge=CrossMerge_1)
x_mamba2 = self.mamba_g2(x2, CrossScan=CrossScan_2, CrossMerge=CrossMerge_2)
x_mamba3 = self.mamba_g3(x3, CrossScan=CrossScan_3, CrossMerge=CrossMerge_3)
x_mamba4 = self.mamba_g4(x4, CrossScan=CrossScan_4, CrossMerge=CrossMerge_4)
# 将所有特征图在通道维度上拼接,并乘以跳跃连接缩放参数和原始输入 x
x_mamba = torch.cat([x_mamba1, x_mamba2, x_mamba3, x_mamba4], dim=-1) * self.skip_scale * x
# 将拼接后的特征图重新排列回 [B, N, C]
x_mamba = rearrange(x_mamba, 'b h w c -> b (h w) c', b=B, h=H, w=W, c=C)
# Channel Modulation
# x_mamba:[B,N,C] fc_out_2.unsqueeze:[B,1,C]
# 将 x_mamba 与 fc_out_2 在通道维度上相乘,
# fc_out_2 通过 unsqueeze 扩展维度后变为 [B, 1, C]
x_mamba = x_mamba * fc_out_2.unsqueeze(1)
# 对调制后的特征图进行层归一化
x_mamba = self.norm(x_mamba)
# 通过投影层,将特征图映射到输出维度
x_mamba = self.proj(x_mamba)
# 返回最终输出
return x_mamba
上面代码中的CrossScan_1, CrossScan_2, CrossScan_3, CrossScan_4,CrossMerge_1, CrossMerge_2, CrossMerge_3, CrossMerge_4在csms6s.py中定义,见2.2
ClassBlock
类别token处理
class ClassBlock(nn.Module):
def __init__(self, dim, mlp_ratio, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.attn = GroupMambaLayer(dim, dim)
self.mlp = FFN(dim, int(dim * mlp_ratio))
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









