







Wang H, Chen Y, Ma C, et al. Multi-Modal Learning With Missing Modality via Shared-Specific Feature Modelling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 15878-15887.
【论文概述】
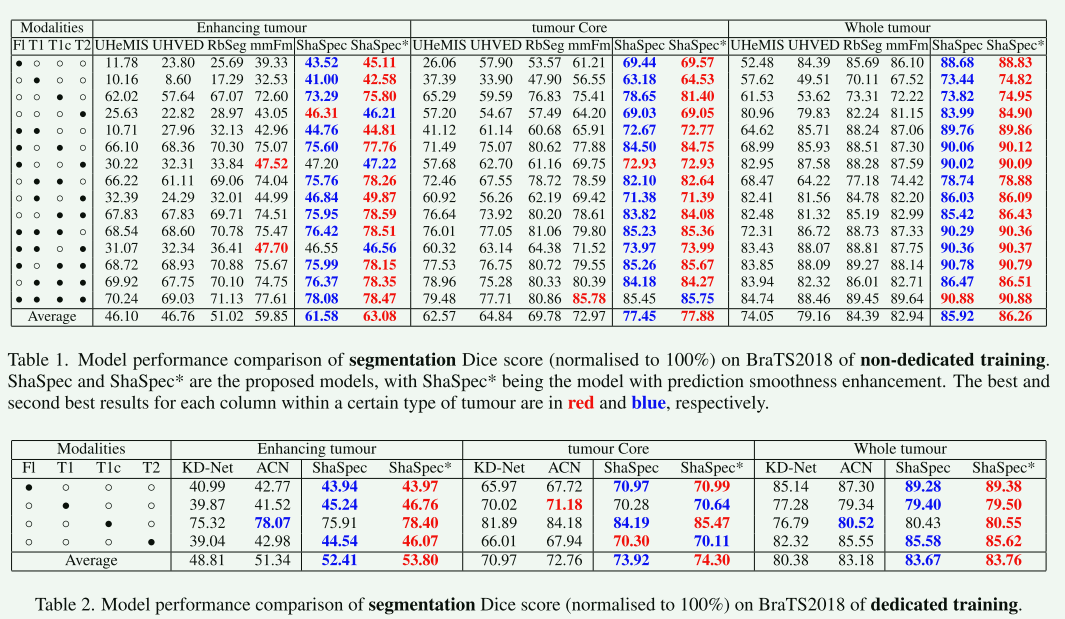
本文的核心思想是提出一种名为“共享-特定特征建模(ShaSpec)”的方法,用于处理多模态学习中的缺失模态问题。该方法在训练和评估期间利用所有可用的输入模态,通过学习共享和特定的特征来更好地表示输入数据。这是通过基于分布对齐和领域分类的辅助任务以及残差特征融合过程来实现的。ShaSpec的设计简单,易于适应多种任务,如分类和分割。实验结果表明,ShaSpec在医学图像分割和计算机视觉分类方面的表现优于竞争方法。例如,在BraTS2018数据集上,ShaSpec在增强肿瘤、肿瘤核心和整体肿瘤的分割精度上均有显著提高(ShaSpec在增强肿瘤的分割上提高了3%,在肿瘤核心上提高了5%,在整体肿瘤上提高了3%)。这项研究表明,ShaSpec通过其简单但有效的架构,在处理多模态学习中的缺失模态问题时,能够提供显著的性能提升。
本文整体结构简单,通过两个辅助任务,性能超越复杂模型,在缺失模态处理中算是一股清流,这可能也是中标CVPR2023的原因。
【提出的方法】
图1展示了ShaSpec方法在完整模态(full-modality)训练和评估的流程。这个流程包含了多个关键组成部分:
- 特定编码器(Specific Encoder)和共享编码器(Shared Encoder):特定编码器负责处理特定于某一模态的特征,而共享编码器则处理跨所有模态共享的特征。
- 跳跃连接(Skip Connection)和特征投影函数(fθproj):这些是网络的一部分,用于改进特征提取和融合过程。
- 分布对齐目标(Distribution Alignment Objective):这部分目标是为了减少不同模态间特征分布的差异,从而提高模型在处理多模态数据时的鲁棒性和准确性。
- 残差融合过程(Residual Fusion Procedure):这是ShaSpec的一个关键创新,它结合了来自不同模态的特征,以改善对缺失模态情况的处理能力。
- 预测目标(Prediction Objective):这是模型的最终目标,通过解码器(Decoder)对输入数据进行分类或其他任务的预测。
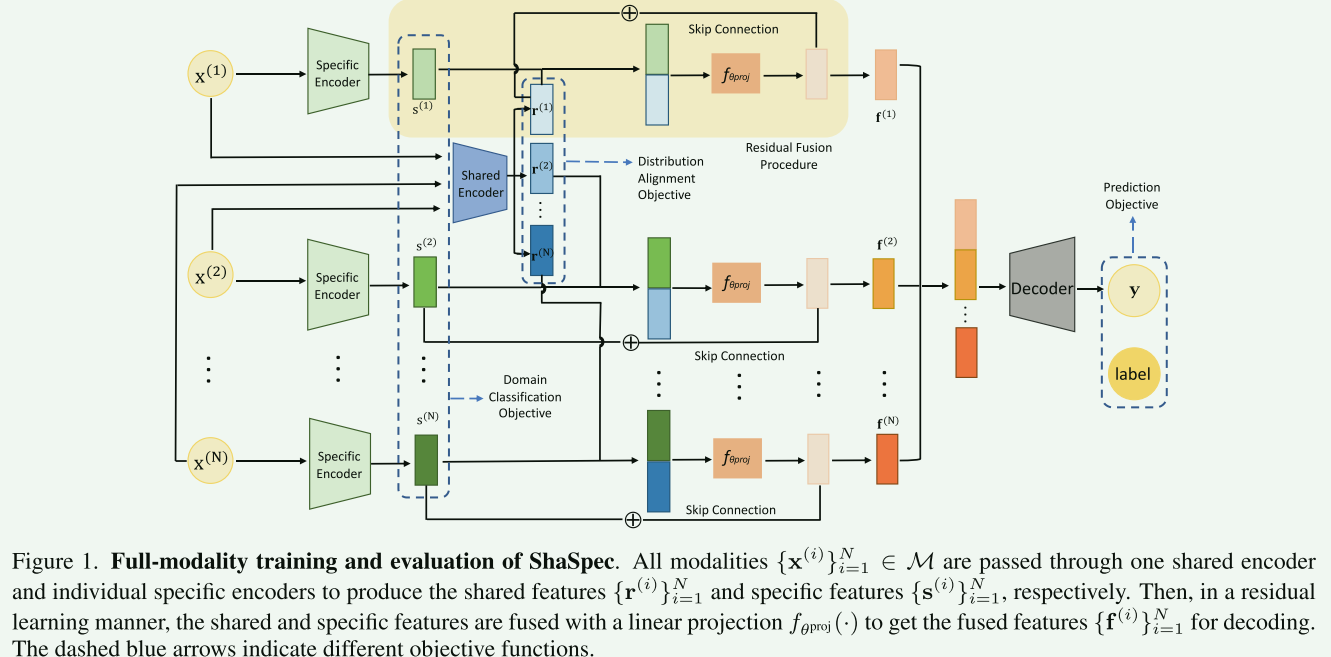
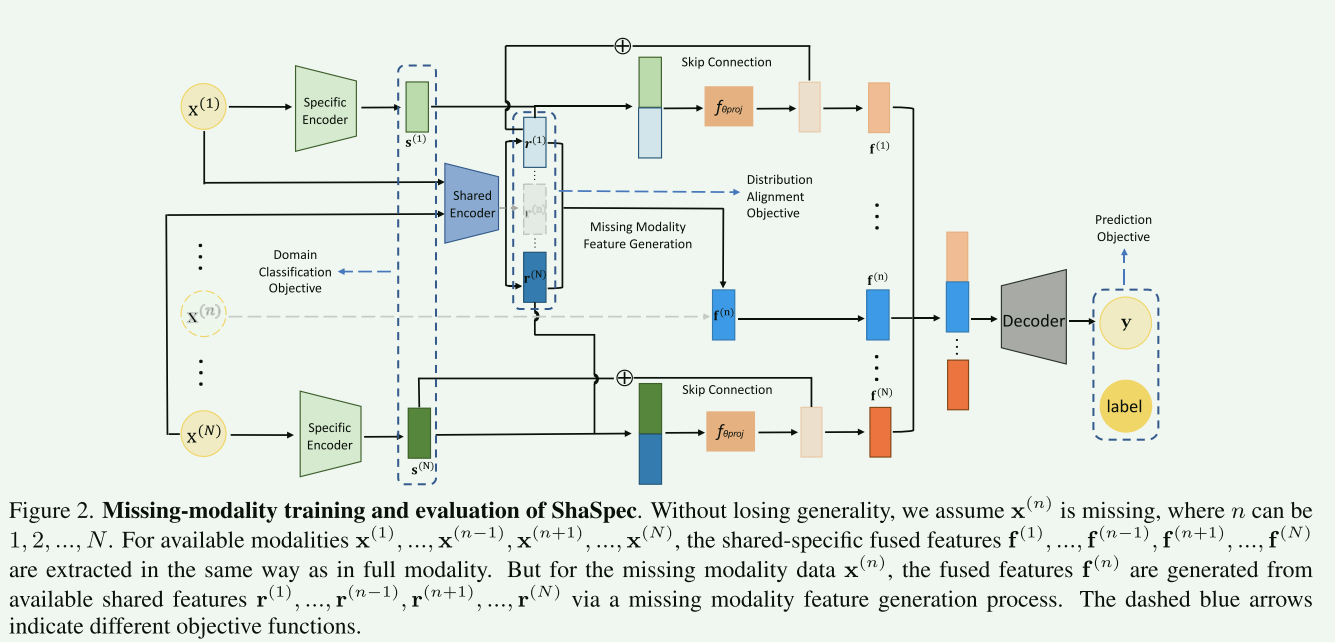
图2展示了ShaSpec方法在缺失模态(missing-modality)的情况下的训练和评估流程。此图说明了当一种或多种模态数据缺失时,ShaSpec如何适应和处理这种情况。在这个流程中,共享编码器同上,缺失模态的特定编码器结果,有存在模态特定编码器的平均得到,比较简单粗暴。
【训练目标】
引入了两个辅助任务:域分类和分布对齐,以优化特定和共享特征的学习。
- 域分类目标(Domain Classification Objective, DCO):这一目标的灵感来源于域适应技术,其核心思想是利用特定模态的特征来进行该模态的域分类。具体来说,作者提出采用DCO来学习特定模态的特征。例如,在脑肿瘤分割任务中,不同的MRI模态(如Flair, T1, T1 contrast-enhanced, T2)可以被视为不同的域。如果某一模态的特定特征可以被用来准确地分类其域,那么这些特征应该包含对该模态特有的重要信息。这意味着,通过DCO,模型可以更有效地学习和区分不同模态的特有特征,从而提高对多模态数据的处理能力。论文中使用交叉熵。
- 分布对齐任务:此部分专注于共享特征的学习,确保不同模态间特征分布的一致性,提高模型对不同模态数据的泛化能力。主要目的是通过最小化交叉熵(CE)损失来混淆域分类器,如果分类器不能够从共享特征中分类出具体的模态,认为共享特征比较鲁棒。这一目标的实现是为了确保模型在处理不同模态的共享特征时能够维持一致性,从而提高模型在多模态环境下的泛化能力和准确性。
【数据集和网络】
数据集采用了两个:BraTS2018、Audiovision-MNIST
硬件:3090TI*1
特征提取采用3D-UNet
【实验结果】

















 3488
3488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









