




2025年3月13日,由何凯明和Yann LeCun领衔的论文Transformers without Normalization挂载Arxiv上,大佬论文必须读一下。本文就该论文进行一个简单总结。

1.论文解读
这份研究论文挑战了深度神经网络中标准化层(如 Layer Norm)的必要性。作者提出了一种名为 Dynamic Tanh (DyT) 的简单元素操作,可以有效地替代 Transformer 架构中的标准化层,并取得与标准化模型相当甚至更好的性能。
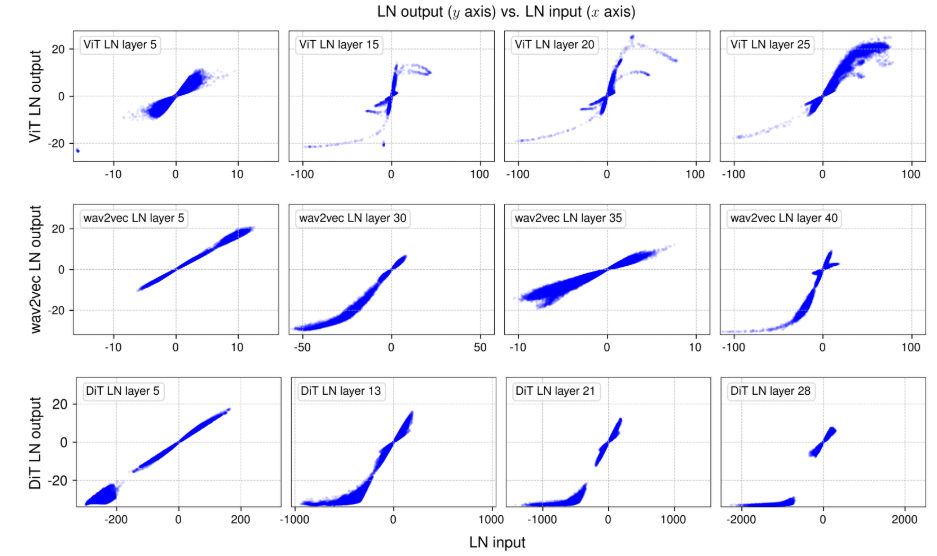
作者通过分析发现,标准化层(如 Layer Norm)的输出与 tanh 函数的 S 形曲线相似,即对输入进行缩放并压缩极端值。论文中的图2说明标准化层并非简单的线性变换,而是会对输入数据进行非线性压缩,特别是对极端值进行压缩。这种非线性压缩效果可能是标准化层对深度神经网络训练至关重要的原因之一。在模型的前几层 LN 层,输入输出关系接近直线,这是因为输入数据的范围较小,经过 LN 层处理后,变化幅度也较小。随着模型层数的增加,输入数据的范围变大,经过 LN 层处理后,极端值被压缩,使得输入输出关系更接近 S 形曲线。
作者提出的操作定义为 :DyT(x)=γ∗tanh(αx)+β\mathrm{DyT}(x)=\gamma*\mathrm{tanh}(\alpha x)+\betaDyT(x)=γ∗tanh(αx)+β
其中 α\alphaα 是一个可学习标量参数,γ\gammaγ和β\betaβ是同维度的矢量。DyT\mathrm{DyT}DyT 通过学习合适的缩放因子 α\alpha
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









