






本文来源公众号“码科智能”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/jVbc_jvSj5gc4uGOBDRvLg

给定第一帧的目标框,大模型实现跟踪任务
视觉理解正在走向大一统,就是一个模型充当多面手,可以完成多个基础任务!之前文章中介绍的 SAM3 希望一个模型搞定视觉识别,Rex-Omini则是在一个模型中能支持十余种视觉任务!
另外受大语言模型中推理成功的启发,一系列工作趋势旨在将“思维链”能力引入视觉领域,使其能够在不同的视觉任务中进行推理。
但当下的推理模型通常设计为仅处理单一任务,并且只能单独在图像或视频上运行,这种割裂极大地限制了它们的实际通用性。

面向视频与图像的一体化推理模型
那么再进一步,结合上述两个基础模型特性,从输入和输出角度,我们能否训练一个一体化的多模态推理通用模型,能够同时处理图像和视频,并完成问答、定位、跟踪、分割等十多项复杂任务?
今天给大家介绍来自港中文和美团的最新研究:一个统一的多模态推理通用模型,它打破了图片与视频的界限,能够处理广泛的视觉推理任务。所有代码、模型和数据均已开源。
# Paper
OneThinker: All-in-one Reasoning Model for Image and Video
# 论文
https://arxiv.org/pdf/2512.03043
# 代码
https://github.com/tulerfeng/OneThinker
# 模型
https://huggingface.co/OneThink一、视觉领域的专业推理模型?
Vision-R1 擅长分析静态图像,目标是增强多模态大语言模型的推理能力,回答关于图片内容的各种复杂问题。在广泛使用的MathVista基准测试上达到了73.5%的准确率,仅比领先的推理模型OpenAI O1低0.4%。
直接应用强化学习训练面临一个根本问题:缺乏高质量的多模态推理数据。利用现有 MLLM 和 DeepSeek-R1,通过模态桥接和数据过滤,获得了20万条高质量多模态思维链数据。
Video-R1 也是港中文的工作,专注于视频理解,首次系统性地将基于规则的强化学习范式引入视频推理领域,能够对视频内容进行深度推理。
在多个视频推理基准测试中表现卓越,特别是在视频空间推理基准VSI-bench上达到了37.1%的准确率,甚至超越了商业专有模型GPT-4o。
Seg-R1 专门负责图像分割任务,使用强化学习增强大型多模态模型的像素级理解和推理能力,引入了一个解耦的推理-分割框架。
采用基于 GRPO 的强化学习来生成明确的思维链推理和位置提示,模型以前景分割图像-掩码对为基础,让LMM能够以“下一个词元”的方式生成点和边界框提示,这些提示随后用于指导SAM2产生分割掩码。

现实世界不按上述专业模型划分,比如一个自动驾驶系统需要同时理解静态图像(识别路标)、分析动态视频(预测车辆轨迹)、进行视觉语言交互(理解乘客指令)并执行精细分割(识别道路边界)。
二、AI大一统的全能模型
面对这些挑战,研究团队提出了一个大胆设想:为什么不训练一个真正的“全能选手”,能够在一个模型中处理各种基本视觉任务。
OneThinker 在 10 项基本视觉任务的 31 个基准测试中表现出色,同时展现了跨任务知识迁移和有希望的零样本泛化能力。
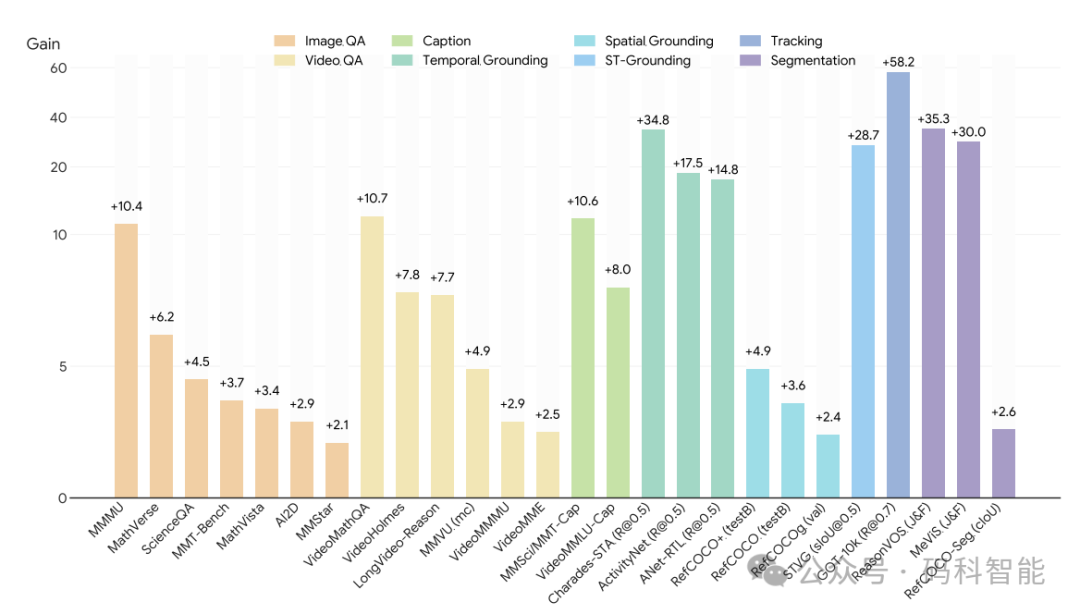
在图像问答任务中,准确率达到70.6%;在数学推理任务中,准确率达到64.3%;在物体跟踪任务中,性能指标达到84.4;在视频分割任务中,综合得分为54.9。
OneThinker 构建了包含 60 万个样本的训练数据集,涵盖所有任务类型。还利用模型标注了34万条高质量的“思维链”数据,让AI学会一步步思考。
具体的,能看图说话:理解图片内容,回答问题

视频解读:分析动态画面,追踪变化

精准定位:在图像或视频中找到任意指定物体

智能分割:精确区分不同区域

自然描述:用语言描述看到的内容
在未来的家用机器人上,你只需要说:“帮我把桌上那个红色的杯子拿过来”,机器人就能理解你的指令(语言理解),找到桌子(定位),识别红色杯子(检测),并规划取物路径(推理与执行)。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 8779
8779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









