




本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/ArMN7QUb18RjRF6Z7C-Gbw

Image
文章篇幅略长,分为上、中和下!
5 评估
5.1 通用视觉问答
Image

Image
Image
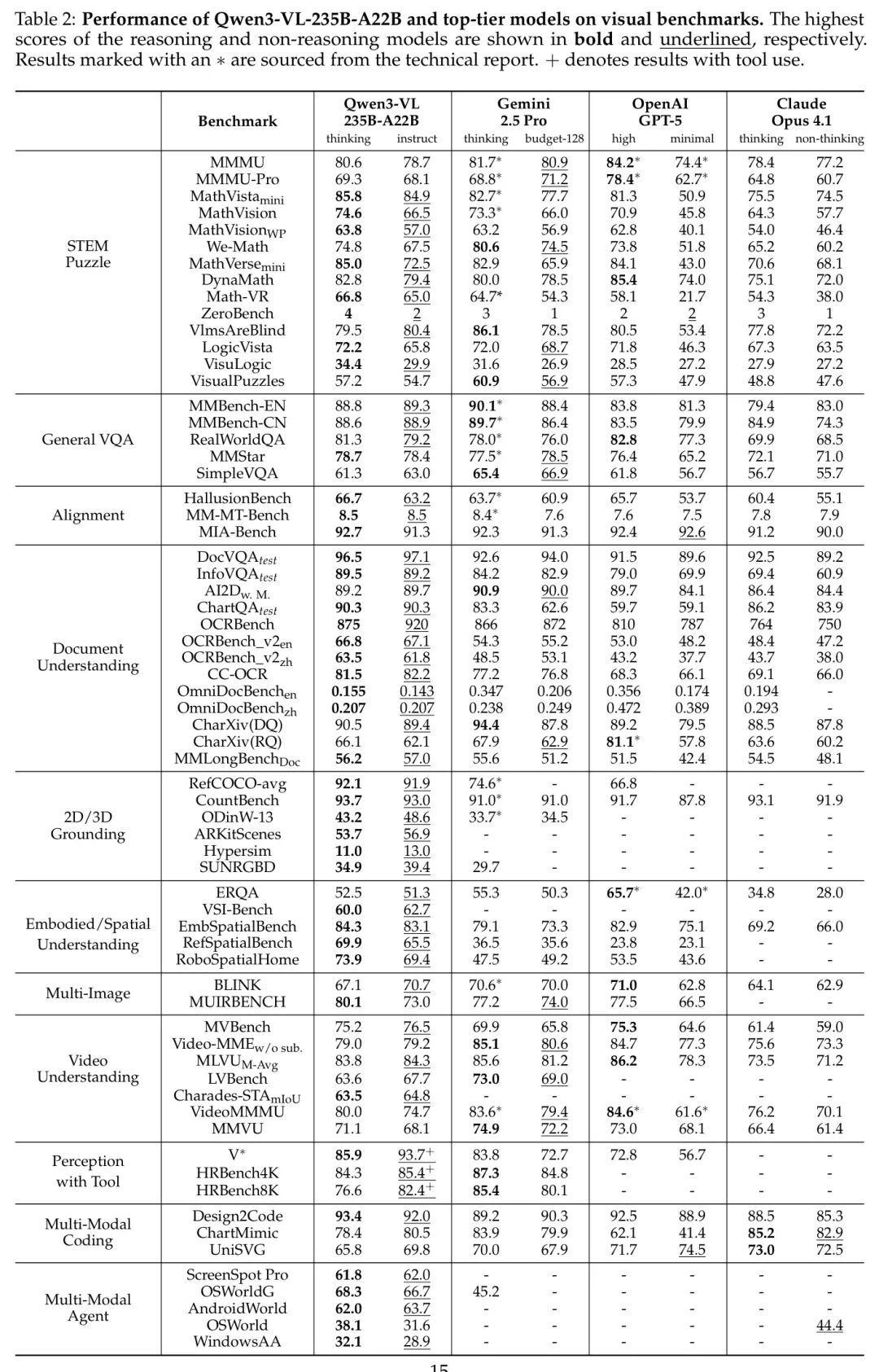
为了全面评估 Qwen3-VL 系列模型的通用视觉问答(Visual Question Answering, VQA)能力,作者在一系列多样化的基准测试上进行了广泛评估,包括 MMBench-V1.1、RealWorldQA(xAI, 2024)、MMStar(Chen et al., 2024a)以及 SimpleVQA。如表2、表3 和表4 所示,Qwen3-VL 系列在从 2B 到 235B 参数量的多种模型规模下,均展现出稳健且极具竞争力的性能。
在思维模式(Thinking mode)的对比中,Qwen3-VL-235B-A22B-Thinking 在 MMStar 上取得了 78.7 的最高分。Gemini-2.5-Pro的思维模式整体表现最佳,但 Qwen3-VL-235B-A22B-Thinking 的表现也十分接近。在非推理模式(non-reasoning mode)的对比中,Qwen3-VL-235B-A22B-Instruct 在 MMBench 和 RealWorldQA 上分别取得了 89.3 和 88.9 以及 79.2 的最高分。
在中等规模模型的实验中,Qwen3-VL-32B-Thinking 在 MMBench 和 RealWorldQA 上均取得了最高分,分别为 89.5 和 79.4。值得注意的是,Qwen3-VL-32B-Instruct 在 RealWorldQA 上的表现甚至超过了 Thinking 变体,得分达到 79.0。
Qwen3-VL系列的可扩展性在小型模型的优异表现中得到充分体现。具体而言,最大规模的模型Qwen3-VL-8B在全部五个基准测试中均取得了最高性能。例如,在MMBench-EN上,“thinking”模式下的得分从2B模型的79.9提升至8B模型的85.3。在其他基准测试中也观察到类似的上升趋势,例如在MMStar上,得分从2B模型(thinking)的68.1提升至8B模型(thinking)的75.3。
5.2 多模态推理
作者在一系列多模态推理基准上评估了 Qwen3-VL 系列模型,主要聚焦于 STEM 相关任务和视觉谜题,包括 MMMU、MMMUPro、MathVision、MathVision-Wildphoto(以下简称 MathVisionWP)、MathVista、We-Math、MathVerse、DynaMath、Math-VR、LogicVista、VisualPuzzles、VLM are Blind 、ZeroBench (Main/Subtasks) ,以及 VisuLogic。如表2 所示,旗舰模型 Qwen3-VL 在“非思考型”与“思考型”模型中均表现出色。值得注意的是,Qwen3-VL-235B-A22B-Instruct 在多个基准上取得了当前报告的最佳结果,涵盖 MathVistamini、MathVision、MathVersemini、DynaMath、ZeroBench、VLMsAreBlind、VisuLogic 和 VisualPuzzlesDirect,且属于非思考型或低思考预算模型。同时,Qwen3-VL-235B-A22B-Thinking 在 MathVista mini、MathVision、MathVersemini、ZeroBench、LogicVista 和 VisuLogic 上达到了当前最优水平。
在中等规模模型中,如表3所示,Qwen3-VL-32B 展现出显著优势,持续优于 Gemini-2.5-Flash 和 GPT-5-mini。与上一代 Qwen2.5-VL-72B 模型相比,中等规模的 Qwen3-VL 模型在推理任务上已实现超越,凸显了视觉语言模型(VLM)的显著进步。此外,作者新推出的 Qwen3-VL-30B-A3B MoE 模型也取得了具有竞争力的性能表现。
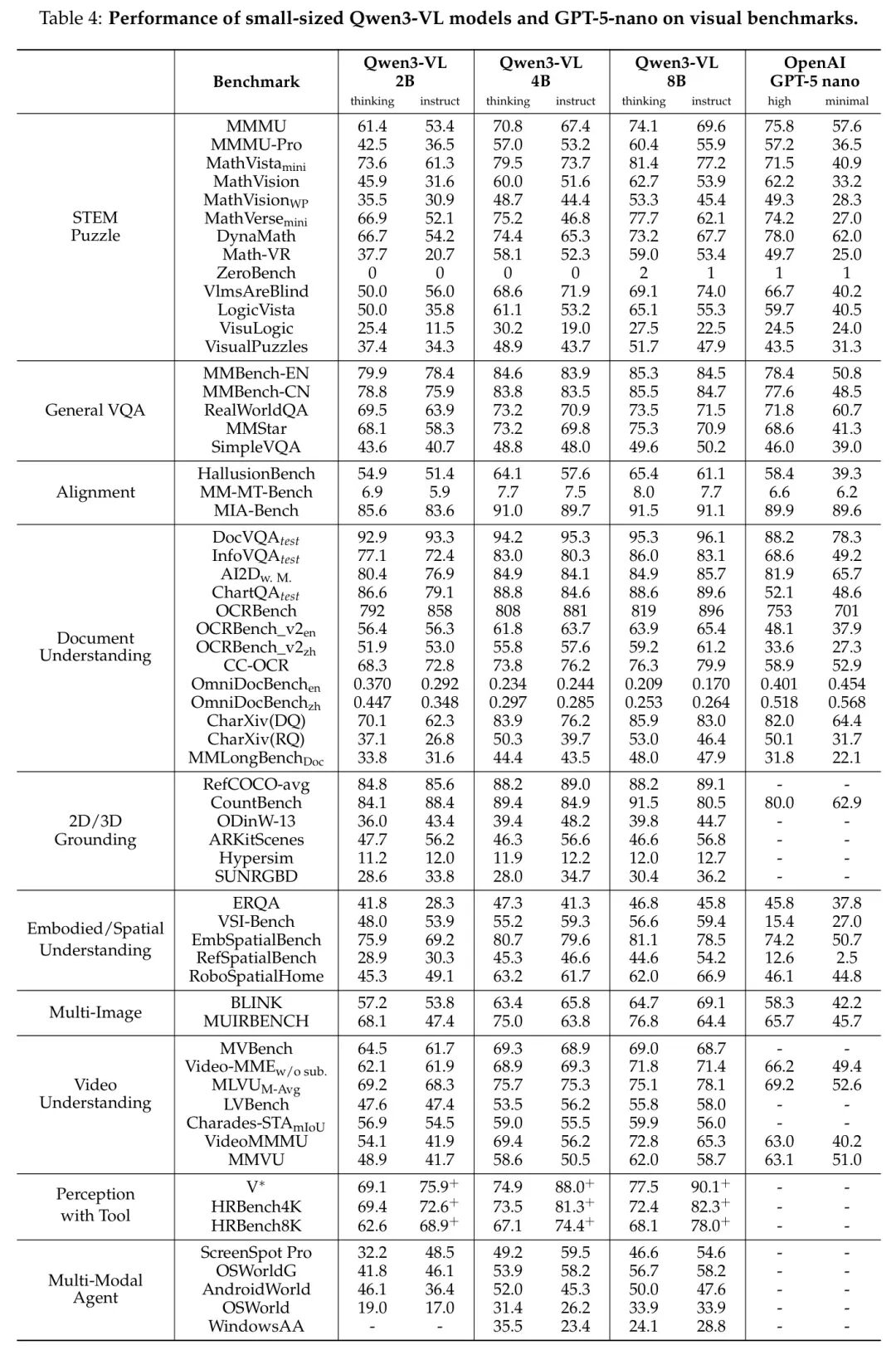
在小型模型中,作者将 Qwen3-VL-2B/4B/8B 与 GPT-5-Nano 进行对比,结果如表4 所示。总体而言,8B 版本保持明显优势,而 4B 模型在 DynaMath 和 VisuLogic 任务上取得了最高得分。值得注意的是,即便是最小的 2B 模型也展现出强大的推理能力。
5.3 对齐与主观任务
能够遵循复杂的用户指令并减少潜在的图像级幻觉,对于当前的大规模视觉语言模型(VLMs)而言至关重要。作者在三个代表性基准测试上评估了Qwen3-VL:MM-MT-Bench、HallusionBench和MIA-Bench。MM-MT-Bench 是一个用于测试多模态指令微调模型的多轮 LLM-as-a-judge 评估基准。HallusionBench 的目标是诊断图像-上下文推理能力,对当前的 VLMs 提出了巨大挑战。MIA-Bench 是一个更全面的基准,用于评估模型对用户复杂指令的响应能力(例如,带有字符限制的创意写作以及组合式指令)。
如表2所示,作者的旗舰模型 Qwen3-VL-235B-A22B 在各项指标上持续优于其他闭源模型。在 HallusionBench 上,作者的思维版本(Thinking version)分别领先 Gemini-2.5-pro、GPT-5和 Claude opus 4.1 3.0、1.0 和 6.3 分。在 MIA-Bench 上,Qwen3-VL-235B-A22B-Thinking 在所有对比模型中取得了综合最优成绩,充分展现了作者在多模态指令遵循能力上的优势。作者进一步分析了 MIA-Bench 的各子任务表现:在数学和文本子任务中,Qwen3-VL分别领先 GPT-5-high-thinking 版本 10.0 和 5.0 分。这一趋势在较小规模的模型中同样显著,例如 Qwen3-VL-30B-A3B 和 Qwen3-VL-32B,它们在与自身规模相当的模型中也表现出领先优势。此外,作者的 2B/4B/8B 系列模型同样表现优异,尤其在 MIA-Bench 上性能下降可忽略不计。
5.4 文本识别与文档理解
作者在与同等规模的其他模型对比时,对 Qwen3-VL 系列在文档相关基准测试中的表现进行了评估,涵盖光学字符识别(OCR)、文档解析、文档问答(QA)以及文档推理任务。
作者在表2列出的基准测试中,将作者的旗舰模型 Qwen3-VL-235B-A22B 与当前最先进的视觉语言模型(VLM)进行对比评估。在以OCR为核心的解析基准测试中——包括 CC-OCR(Yang et al., 2024b)和 OmniDocBench(Ouyang et al., 2024)——以及综合性OCR基准测试如 OCRBench(Liu et al., 2024)和 OCRBench_v2(Fu et al., 2024b),Qwen3-VL-235B-A22B-Instruct 模型取得了新的最先进水平,仅略优于其“思考”版本 Qwen3-VL-235B-A22B-Thinking。在需要同时具备OCR能力与关键词搜索能力的OCR相关视觉问答(VQA)基准测试中,如 DocVQA(Mathew et al., 2021b)、InfoVQA(Mathew et al., 2021a)、AI2D(Kembhavi et al., 2016)、ChartQA(Masry et al., 2022)以及 CharXiv(Wang et al., )的描述子集,Instruct 和 Thinking 两个变体均表现出相当的性能,展现出在这些任务上的持续优异表现。值得注意的是,在 CharXiv 的推理子集上——该任务要求深入理解图表并进行多步推理——Thinking 变体超越了 Instruct 版本,排名仅次于 GPT5-thinking 和 Gemini-2.5-Pro-Thinking。
此外,在Qwen3-VL系列的小尺寸模型中,Qwen3-VL-30B和Qwen3-VL-32B模型在大多数评估指标上均持续优于Gemini-2.5-Flash和GPT-5-mini,如表3所示。即使是在紧凑的稠密模型——Qwen3-VL-8B、Qwen3-VL-4B和Qwen3-VL-2B——也展现出在OCR解析、视觉问答(VQA)以及综合性基准测试套件上的显著竞争力,具体表现详见表4。这凸显了Qwen3-VL架构在不同模型规模下所具备的卓越效率与强大的可扩展性。
在本版 Qwen3-VL 中,作者特别注重提升其对长文档的理解能力。如表2 所示,在 MMLongBench-Doc 基准测试(Ma et al., 2024)的旗舰模型对比中,作者的 Qwen3-VL-235B-A22B 在 instruct/thinking 设置下取得了 的整体准确率,展现出该长文档理解任务上的最先进(SOTA)性能。
Image
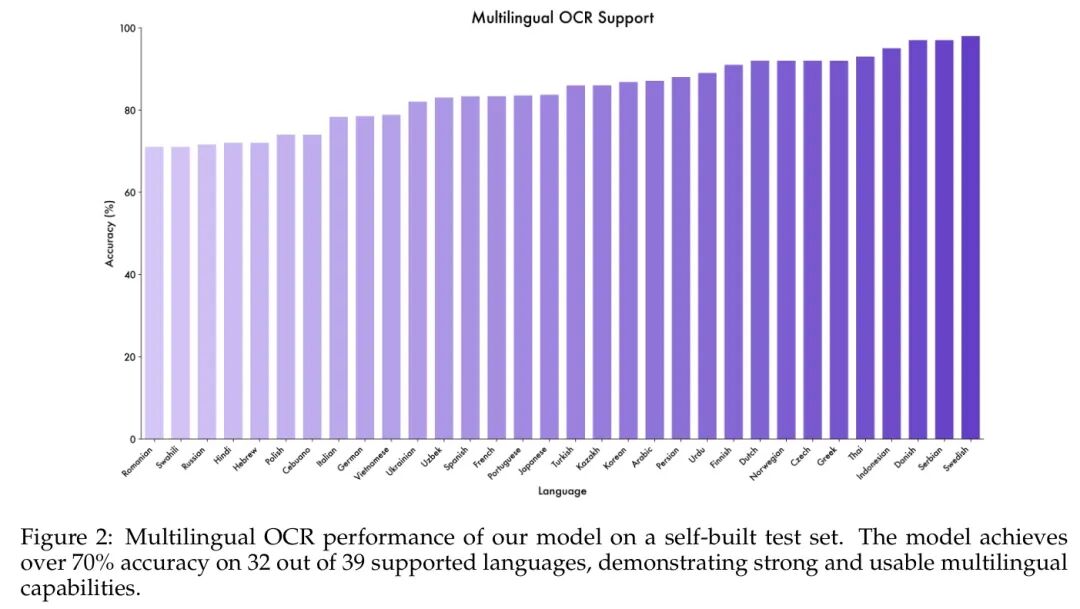
除了在现有基准测试中表现出色外,作者在多语言支持方面也取得了显著进展。这一能力相比 Qwen2.5-VL 支持的 10 种非英语/中文语言,扩展至 Qwen3-VL 中的 39 种语言。作者在一个新构建的内部数据集上评估了这一扩展能力。如图2 所示,该模型在测试的 39 种语言中,有 32 种语言的准确率超过 —— 作者认为这一阈值具有实际应用价值。这表明 Qwen3-VL 强大的 OCR 能力并不仅限于少数几种语言,而是广泛覆盖了多样且广泛的语种。
5.5 2D 和 3D 定位
在本节中,作者对Qwen3-VL系列在2D和3D定位相关基准上的表现进行了全面评估,并将其与具备类似能力的最先进模型进行了对比。
作者在 referring expression comprehension 基准测试 (Kazemzadeh et al., 2014; Mao et al., 2016)、开集目标检测基准 ODinW-13(Li et al., 2022)以及计数基准 CountBench(Paiss et al., 2023)上评估了 Qwen3-VL 的 2D 定位能力。对于 ODinW-13,作者通过将置信度分数设为 1.0,采用平均精度(mean Average Precision, mAP)作为评估指标。为确保与传统的开放集目标检测专用模型具有可比性,作者在评估过程中将所有数据集类别同时包含在 prompt 中。如表2 所示,作者的旗舰模型 Qwen3-VL-235B-A22B 在 2D 定位和计数基准上均表现出色,取得了当前最优(state-of-the-art, SOTA)的结果。值得注意的是,其在 ODinW-13 上取得了 的成绩,展现出在多目标开集目标定位任务中的强大性能。表3 和表4 分别展示了作者较小规模模型变体的详细结果,这些模型在 2D 视觉定位任务中同样表现出具有竞争力的性能。
此外,在本版 Qwen3- 中,作者进一步提升了模型在 3D 物体定位任务中的空间感知能力。作者在 Omni3D(Brazil et al., 2023)这一综合性基准上对 Qwen3-VL 系列与其他同规模模型进行了对比评估,该基准包含 ARKitScenes(Baruch et al., 2021)、Hypersim(Roberts et al., 2021)和 SUN RGB-D(Song et al., 2015)等多个数据集。作者采用平均精度(mean Average Precision, mAP)作为评估指标。每个输入为一个图像-文本对,包含图像及指定目标类别的文本 Prompt (prompt)。为确保与现有视觉语言模型(VLM)的公平比较,作者将IoU(IoU)阈值设为 0.15,并在 Omni3D 测试集上报告 指标,同时将检测置信度固定为 1.0。如表2 所示,作者的旗舰模型 Qwen3-VL-235B-A22B 在多个数据集上均显著优于其他闭源模型。具体而言,在 SUN RGB-D 数据集(Song et al., 2015)上,Qwen3-VL-235B-A22B-Thinking 变体的性能比 Gemini-2.5-Pro 高出 5.2 个百分点。此外,作者的小规模变体(如 Qwen3-VL-30B-A3B、-32B、-8B、-4B、-2B)在 3D 物体定位任务中也表现出极为出色的竞争力,详细结果分别见表3 和表4。
5.6 细粒度感知
作者在三个主流基准上衡量了模型的细粒度感知能力。与前代模型 Qwen2.5-VL-72B 相比,Qwen3-VL 系列在细粒度视觉理解方面实现了显著提升。值得注意的是,当引入工具增强后,Qwen3-VL-235B-A22B 在所有三个基准上均达到了当前最优性能:在 (Wu & Xie, 2024)上达到 93.7,在 HRBench-4k(Wang et al., 2024e)上达到 85.3,在 HRBench-8k(Wang et al., 2024e)上达到 82.3。这一持续的领先表现凸显了 Qwen3-VL 所引入的架构优化与训练策略的有效性,尤其是在处理高分辨率输入以及细微视觉差异方面,这些对于细粒度感知任务至关重要。
其次,或许更为令人意外的是,集成外部工具所带来的性能提升,始终超过单纯增大模型规模所带来的收益。例如,在 Qwen3-VL 系列中,添加工具带来的绝对性能提升在 上始终保持在约 5 个百分点。这些发现进一步坚定了作者的信念:在多模态领域,扩展具备工具集成能力的Agent学习(agentic learning)是一种极具前景的发展方向。
5.7 多图像理解
除了单图像基础对话评估之外,推动视觉语言模型(VLM)具备多图像理解能力具有重要意义。该任务需要在多样视觉模式之间进行更高 Level 的上下文分析,从而实现更先进的识别与推理能力。为此,作者通过全面的跨图像模式学习技术对 Qwen3-VL 进行增强,包括多图像指代定位(multi-image referring grounding)、视觉对应关系(visual correspondence)以及多跳推理(multi-hop reasoning)。作者在两个主流的多图像基准测试上评估了 Qwen3-VL:BLINK(Fu et al., 2024c)和 MuirBench(Wang et al., 2024a)。如表2 所示,与其它领先的 LVLM 相比,Qwen3-VL 在多图像理解方面展现出整体优势。具体而言,Qwen3-VL-235B-A22B-Instruct 的性能可与当前最先进的模型(如 Gemini-2.5-pro)相媲美,而 Qwen3-VL-235B-A22B-Thinking 在 MuirBench 上取得了 80.1 的显著领先得分,超越了所有其他模型。
5.8 身体化与空间理解
在具身化与空间理解任务中,Qwen3-VL 的性能通过一系列具有挑战性的基准测试,与当前最先进的模型进行了严格对比:ERQA(Team et al., 2025)、VSIBench(Yang et al., 2025b)、EmbSpatial(Du et al., 2024)、RefSpatial(Zhou et al., 2025)以及 RoboSpatialHome(Song et al., 2025a)。在这些基准测试中,该模型展现出卓越的能力,其表现可与 Gemini-2.5-Pro、GPT-5 和 Claude-Opus-4.1 等顶尖模型相媲美。这一成功主要得益于模型在高分辨率视觉数据上进行训练,数据包含细粒度的指向标注、相对位置标注以及问答对(QA pairs),从而具备了深刻的空间理解(spatial understanding)能力。这一能力在 EmbSpatial、RefSpatial 和 RoboSpatialHome 基准测试中得到了充分验证,其中 Qwen3-VL-235BA22 在这三个任务上的得分分别为 84.3、69.9 和 73.9。此外,通过在训练过程中融合指向(pointing)、定位(grounding)以及时空感知(spatio-temporal perception)数据,模型的具身智能(embodied intelligence)得到显著增强,在 ERQA(Team et al., 2025)上取得 52.5 的高分,在 VSIBench(Yang et al., 2025b)上达到 60.0 的顶尖水平。
5.9 视频理解
得益于训练数据的规模扩大以及关键架构的优化,Qwen3-VL 在视频理解能力方面表现出显著提升。特别是交错式 MRoPE(interleaved MRoPE)的引入、文本时间戳的插入,以及时间密集型视频字幕的规模化,共同使 Qwen3-VL 8B 版本在性能上达到了与远为庞大的 Qwen2.5-VL 72B 模型相媲美的水平。
作者在一系列多样化的视频理解任务上进行了全面评估,涵盖通用视频理解(VideoMME (Fu et al., 2024a)、MVBench (Li et al., 2024b))、时序视频定位(Charades-STA (Gao et al., 2017))、视频推理(VideoMMMU (Hu et al., 2025)、MMVU (Zhao et al., 2025))以及长时视频理解(LVBench (Wang et al., 2024d)、MLVU (Zhou et al., 2024))。与当前最先进的专有模型(包括 Gemini 2.5 Pro、GPT-5 和 Claude Opus 4.1)相比,Qwen3-VL 展现出具有竞争力的性能,且在多个任务中表现更优。特别地,作者的旗舰模型 Qwen3-VL-235B-A22B-Instruct 在标准视频理解基准测试中达到了与 Gemini 2.5 Pro(思维预算为 128)和 GPT-5 最小版本相当的性能。通过将上下文窗口扩展至 256K tokens,该模型在长视频评估任务中进一步实现或超越 Gemini-2.5-Pro,尤其在 MLVU 任务上表现尤为突出。
在评估细节方面,作者对所有基准测试的视频设置了每视频最多 2,048 帧的限制,以确保视频 token 的总数不超过 224K。VideoMMMU 和 MMVU 的每帧最大 token 数设置为 768,其余所有基准测试则设置为 640。此外,Charades-STA 中的视频以每秒 4 帧(fps)的速率进行采样,而其他所有基准测试均采用 2 fps 的采样率。对于 VideoMMMU,作者采用基于模型的评判器进行评估,因为基于规则的评分方法准确度不足。需要指出的是,由于资源和 API 限制,作者的比较无法完全保证公平性,这限制了评估过程中使用的输入帧数量:Gemini 2.5 Pro 为 512 帧,GPT-5 为 256 帧,Claude Opus 4.1 为 100 帧。
5.10 Agent
作者通过 GUI-grounding 任务(ScreenSpot (Cheng et al., 2024)、ScreenSpot Pro (Li et al., 2025b)、OSWorldG (Xie et al., 2025a))评估 UI 感知能力,并通过在线环境评估(AndroidWorld (Rawles et al., 2024)、OSWorld (Xie et al., 2025c;b))衡量决策能力。在 GUI-grounding 任务中,Qwen3-VL-235B-A22B 在多个任务上均达到当前最优性能,覆盖桌面、移动设备及 PC 等交互式界面,展现出极为出色的 UI 感知能力。在在线评估中,Qwen3-VL 32B 在 OSWorld 上得分为 41,在 AndroidWorld 上得分为 63.7,均超越当前主流基础 VLM。Qwen3-VL 作为 GUI Agent 展现出卓越的规划、决策与反思能力。此外,较小规模的 Qwen3-VL 模型在这些基准测试中也表现出极具竞争力的性能。
5.11 以文本为中心的任务
为全面评估 Qwen3-VL 的文本中心性能,作者采用自动基准测试来评估模型在指令型(instruct)与思考型(thinking)模型上的表现。这些基准测试可归纳为以下几类关键类型:
-
1. 知识类(Knowledge):MMLU-Pro(Wang et al., 2024f)、MMLU-Redux(Gema et al., 2024)、GPQA(Rein et al., 2023)、SuperGPQA(Team, 2025)
-
2. 推理类(Reasoning):AIME-25(AIME, 2025)、HMMT-25(HMMT, 2025)、LiveBench(2024-11-25)(White et al., 2024)
-
3. 代码类(Code):LiveCodeBench v6(Jain et al., 2024)、CFEval、OJBench(Wang et al., 2025c)
-
4. 对齐任务类(Alignment Tasks):IFEval(Zhou et al., 2023)、Arena-Hard v2(Li et al., 2024d)¹、Creative Writing v3(Paech, 2023)²、WritingBench(Wu et al., 2025b)
-
5. Agent类(Agent):BFCL-v3(Patil et al., 2024)、TAU2-Retail、TAU2-Airline、TAU2-Telecom
-
6. 多语言类(Multilingual):MultiIF(He et al., 2024)、MMLU-ProX、INCLUDE(Romanou et al., 2025)、PolyMATH(Wang et al., 2025b)
评估设置:对于 Qwen3-VL 指令模型(包括 235B-A22B、32B 和 30B-A3B),作者配置采样超参数为:temperature ,top-,top-,以及 presence penalty 。对于小型指令模型(包括 8B、4B 和 2B),作者设置 temperature ,top-,top-,以及 presence penalty 。作者设定最大输出长度为 32,768 个 token。
对于采用 Mixture-of-Experts(MoE)架构的 Qwen3-VL 思维模型,作者将采样温度(sampling temperature)设为 0.6,top-p 设为 0.95,top- 设为 20。对于密集型思维模型(dense thinking models),作者将温度(temperature)设为 1.0,top-p 设为 0.95,top- 设为 20,并额外引入存在惩罚(presence penalty)为 1.5,以促进输出的多样性。作者将最大输出长度设为 32,768 个 token,除 AIME-25、HMMT-25 和 LiveCodeBench v6 外,这些任务的长度扩展至 81,920 个 token,以提供充足的思维空间。
详细结果如下。
Image
Image
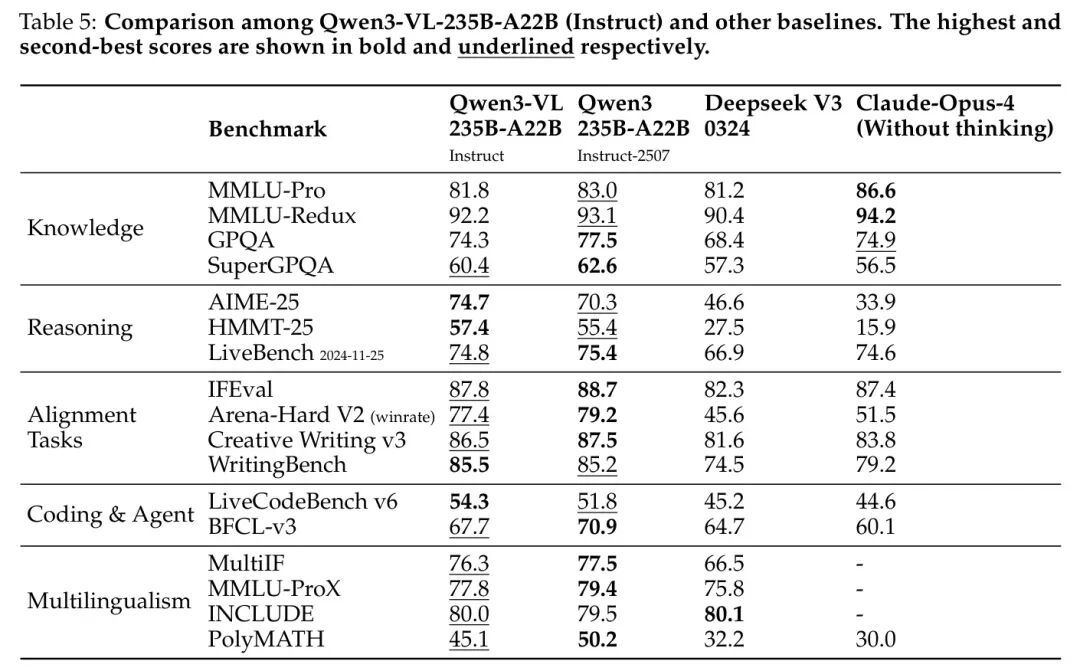
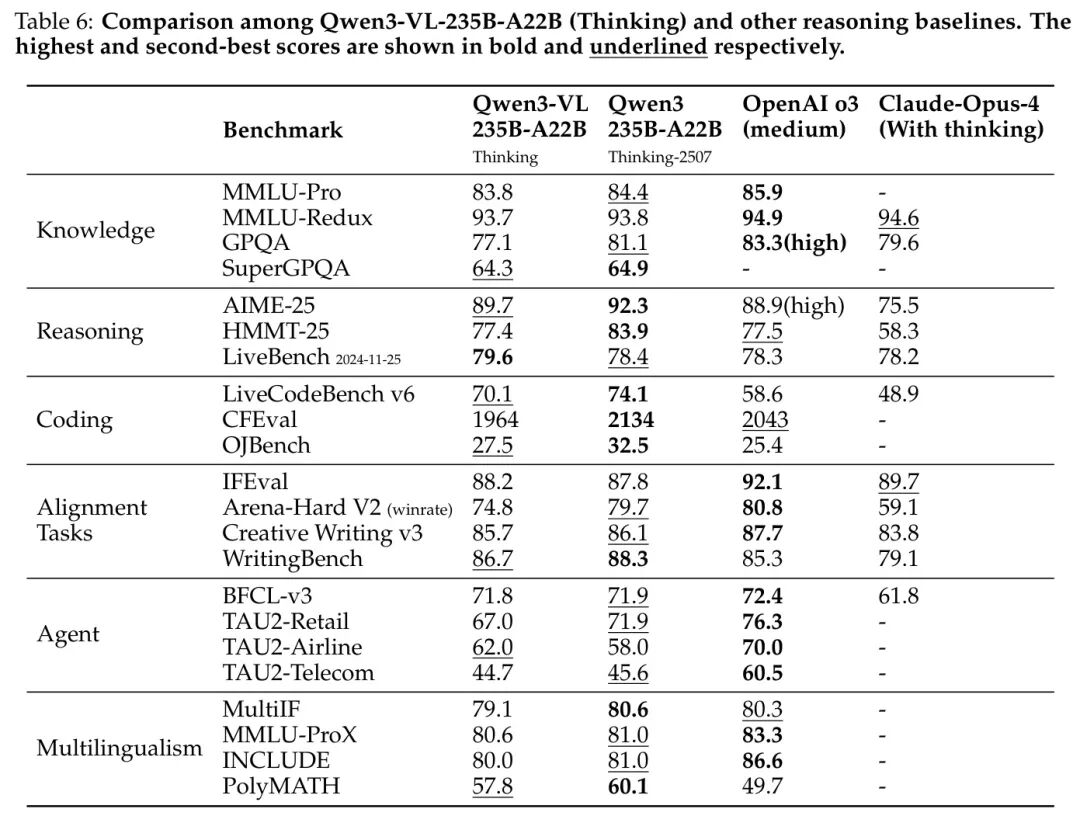
作者将其旗舰模型 Qwen3-VL-235B-A22B 与当前领先的指令模型和思维链模型进行对比。对于 Qwen3-VL-235B-A22B-Instruct,作者以 Qwen3-235B-A22B-Instruct-2507、DeepSeek V3 0324 和 Claude-Opus-4(无思维链)作为 Baseline 模型。对于 Qwen3-VL-235B-A22B-Thinking,作者以 Qwen3-235B-A22B-Thinking-2507、OpenAI o3(medium)和 Claude-Opus-4(带思维链)作为 Baseline 模型。评估结果如表5 和表6 所示。
• 从表5可以看出,Qwen3-VL-235B-A22B-Instruct取得了具有竞争力的性能,其表现可与甚至超越其他领先模型(包括DeepSeek V3 0324、Claude-Opus-4(无思考模式)以及作者此前的旗舰模型Qwen3-235B-A22B-Instruct-2507)相媲美。尤其值得注意的是,Qwen3-VL-235B-A22B-Instruct在需要推理能力的任务(如数学和编程)上优于其他模型。需要强调的是,DeepSeek V3 0324和Qwen3-235B-A22B-Instruct-2507均为大语言模型(Large Language Model),而Qwen3-VL-235B-A22B-Instruct则是一个视觉语言模型(Vision Language model),能够同时处理视觉与文本任务。这表明Qwen3-VL-235B-A22B-Instruct已实现视觉与文本能力的深度融合。
• 从表6可以看出,Qwen3-VL-235B-A22B-Thinking在与其他领先推理模型的对比中也表现出色。Qwen3-VL-235B-A22B-Thinking在AIME-25和LiveCodeBench v6上均超越了OpenAI o3(medium)和Claude-Opus-4(带思考模式),表明Qwen3-VL-235B-A22B-Thinking具备更强的推理能力。
Image
Image
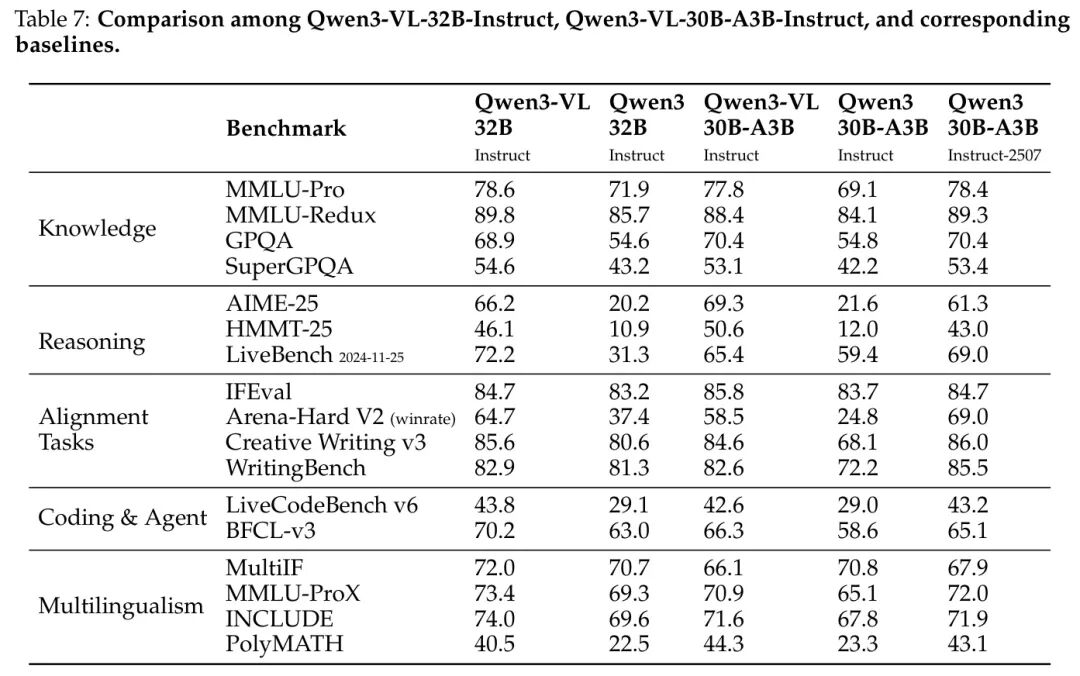
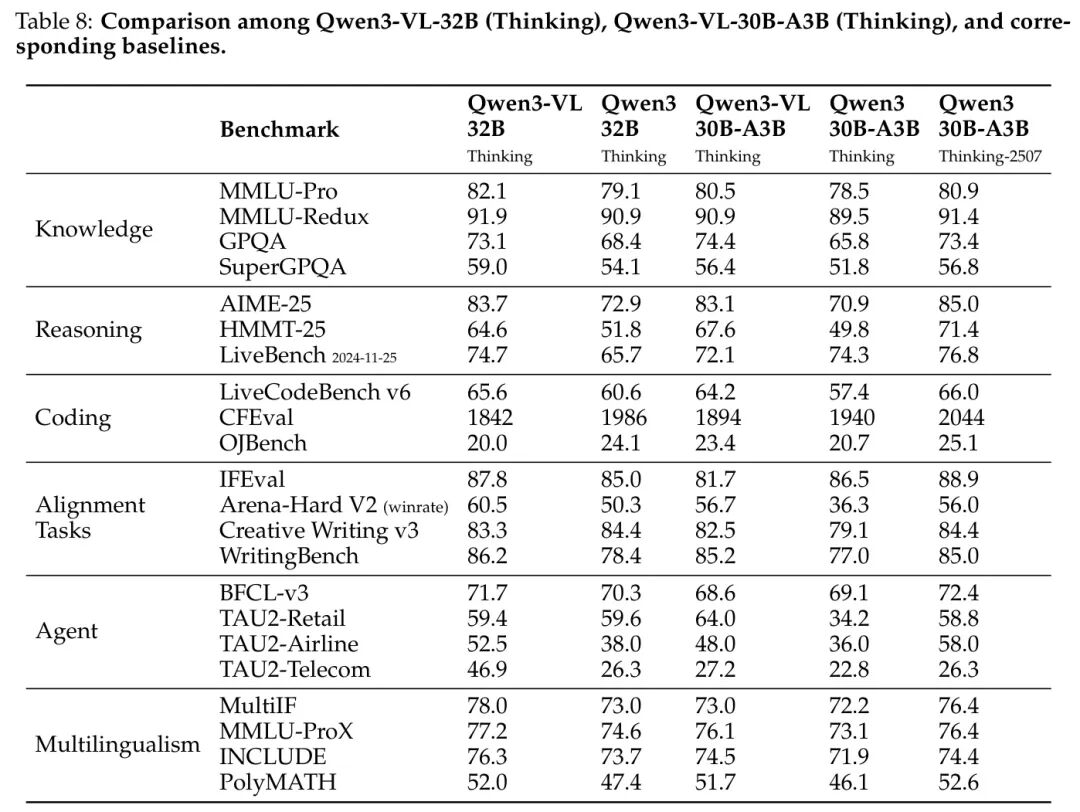
作者将其与对应的纯文本模型 Qwen3-32B、Qwen3-30B-A3B 和 Qwen3-30B-A3B-2507 进行对比,评估结果如表7和表8所示。
• 从表7可以看出,对于指令模型,Qwen3-VL-32B 和 Qwen3-VL-30B-A3B 在所有基准测试上均显著优于 Qwen3-32B 和 Qwen3-30B-A3B。其中,Qwen3-VL-30B-A3B 在 AIME-25 和 HMMT-25 等任务上的表现与 Qwen3-30B-A3B-2507 相当,甚至更优。
• 从表8可以看出,对于思维模型,Qwen3-VL-32B 和 Qwen3-VL-30B-A3B 在大多数基准测试中均超越了 Baseline 模型。Qwen3-VL-30B-A3B 的性能与 Qwen3-30B-A3B-2507 相当。
Qwen3-VL-8B / 4B / 2B
Image
Image
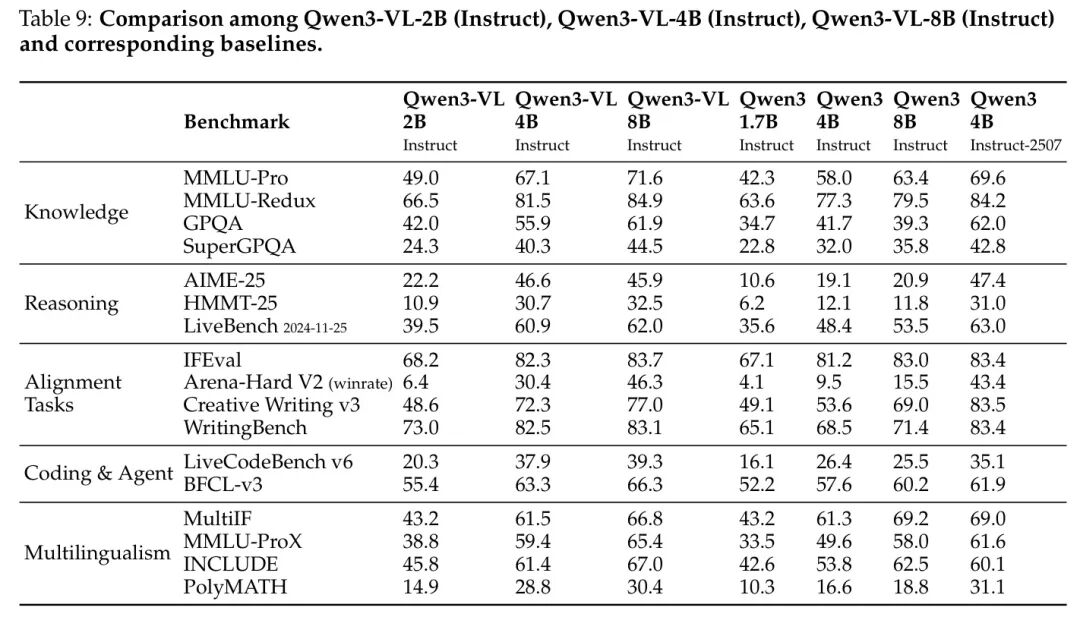
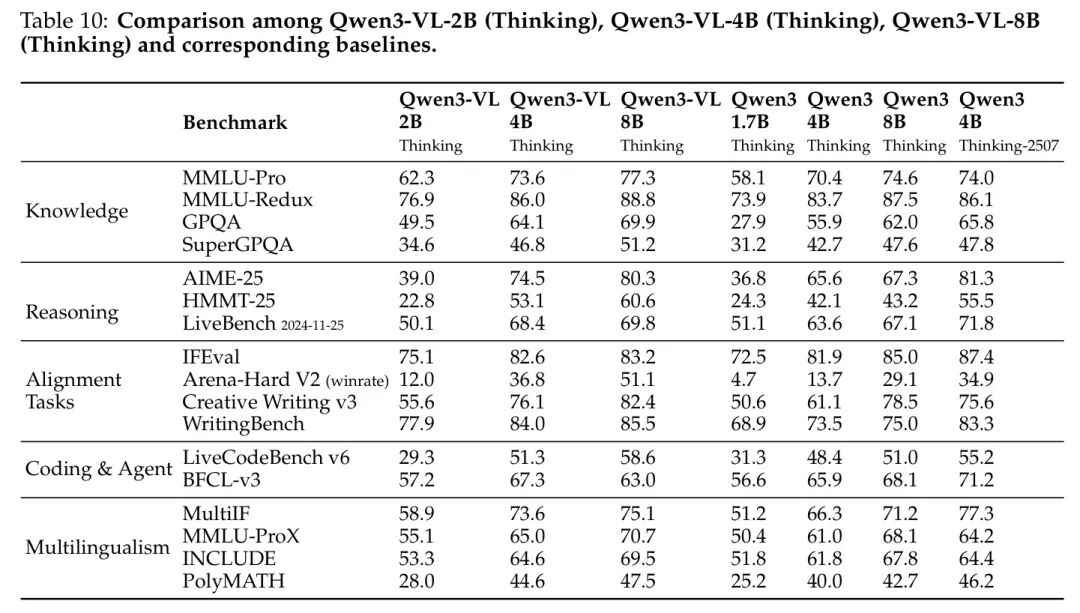
作者在表9和表10中展示了 Qwen3-VL-2B、Qwen3-VL-4B 和 Qwen3-VL-8B 的评估结果。对于 Qwen3-VL-2B 和 Qwen3-VL-8B,作者将其与 Qwen3-1.7B 和 Qwen3-8B 进行对比;对于 Qwen3-VL-4B,则与 Qwen3-4B 和 Qwen3-4B-2507 进行对比。总体而言,这些边缘侧模型表现出色,显著优于 Baseline 模型。这些结果充分证明了作者提出的 Strong-to-Weak Distillation 方法的有效性,使得作者能够以显著降低的成本和投入,构建轻量级模型。
5.12 消融实验
5.12.1 视觉编码器

Image
作者与原始的 SigLIP-2 进行了对比实验。如表11所示,在 CLIP 预训练阶段的零样本评估中,Qwen3-ViT 在标准基准上保持了具有竞争力的性能,同时在 OmniBench(作者内部设计的综合性评估套件)上取得了显著提升。该套件旨在评估模型在多样化且具有挑战性条件下对世界知识的整合能力。此外,当与相同的 1.7B Qwen3 语言模型集成并训练 1.5T Token 后,Qwen3-ViT 在多个关键任务上持续优于基于 SigLIP-2 的 Baseline 模型,并在 OmniBench 上仍保持显著领先,充分展现了其作为更强视觉 Backbone 网络的优势与有效性。
5.12.2 DeepStack

Image
作者进行了消融实验以验证DeepStack机制的有效性。如表12所示,配备DeepStack的模型在多个基准测试中均实现了整体性能提升,充分证明了该机制的有效性。这一提升归因于DeepStack能够整合丰富的视觉信息,从而有效增强模型在细粒度视觉理解方面的能力,例如在InfoVQA和DocVQA基准测试中的表现。
5.12.3 Needle-in-a-Haystack
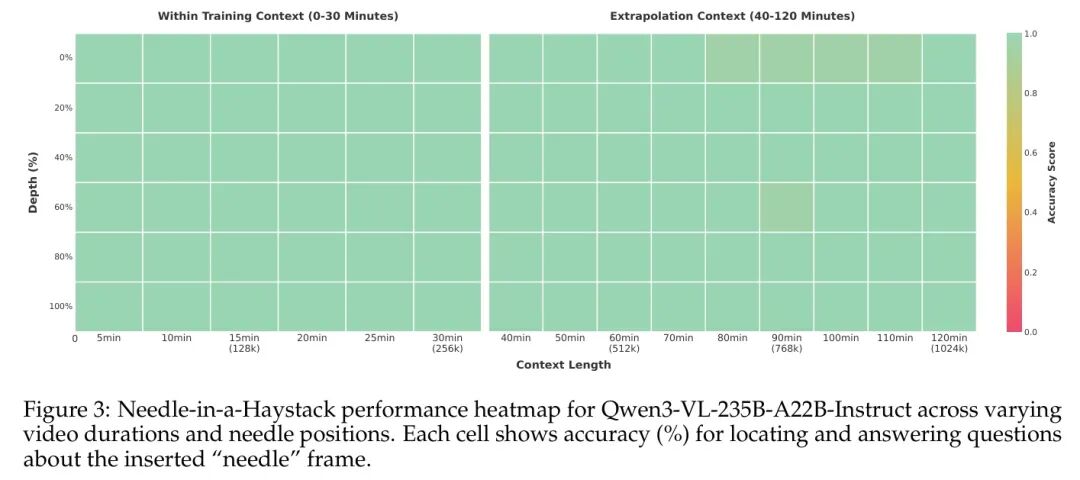
为评估模型处理长上下文输入的能力,作者在 Qwen3-VL-235B-A22B-Instruct 上构建了一个视频“针尖藏于 haystack”(Needle-in-a-Haystack)评估任务。在此任务中,一个语义显著的“针”帧(包含关键视觉证据)被插入到长视频的不同时间位置。随后,模型需从长视频中准确定位目标帧并回答相关问题。评估过程中,视频以 1 FPS 的频率进行均匀采样,帧分辨率则动态调整,以维持恒定的视觉 token 预算。
Image
如图3所示,该模型在时长不超过30分钟的视频上实现了完美的100%准确率——对应上下文长度为256K tokens。令人瞩目的是,即使通过基于YaRN的位置扩展方法外推至长达1M tokens(约2小时视频)的序列时,模型仍保持了99.5%的高准确率。这些结果充分证明了该模型强大的长序列建模能力。
6 结论
在本工作中,作者提出 Qwen3-VL,这是一个先进的视觉-语言基础模型系列,显著推动了多模态理解与生成的前沿发展。通过整合高质量的多模态数据迭代与架构创新——包括增强型交错式-MRoPE(interleaved-MRoPE)、DeepStack 多模态对齐机制以及基于文本的时间定位(text-based temporal grounding)——Qwen3-VL 在广泛的多模态基准测试中实现了前所未有的性能表现,同时保持了强大的纯文本处理能力。其原生支持 256K token 的交错序列,使其能够对长而复杂的文档、图像序列及视频进行稳健推理,因而特别适用于对高保真跨模态理解有严苛要求的真实应用场景。模型提供密集(dense)与混合专家(Mixture-of-Experts)两种版本,确保在不同延迟与质量需求场景下的灵活部署。此外,作者的后训练策略包含非思考(non-thinking)与思考(thinking)两种模式,进一步增强了模型的适应性与实用性。
展望未来,作者期望 Qwen3-VL 成为具身人工智能(embodied AI) Agent 的基础引擎,能够无缝连接数字世界与物理世界。这类Agent不仅能够对丰富的多模态输入进行感知与推理,还能在动态环境中执行具有上下文感知能力的决策性动作——与用户交互、操作数字界面,并通过 grounded(具身的)多模态决策指导机器人系统。未来的工作将聚焦于拓展 Qwen3-VL 的能力,涵盖交互式感知(interactive perception)、工具增强型推理(tool-augmented reasoning)以及实时多模态控制,最终目标是实现能够与人类在虚拟与物理领域中共同学习、适应并协作的 AI 系统。此外,作者正积极探索统一的理解-生成架构,利用视觉生成能力进一步提升整体智能水平。通过在 Apache 2.0 许可证下开放发布整个模型系列,作者旨在推动社区驱动的创新,助力实现真正融合、多模态 AI Agent 的愿景。
参考
[1]. Qwen3-VL Technical Report
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 5487
5487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









