




本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/jPyIkYo7hrvXoExRBDBDHQ
引言

深度估计是一项计算机视觉任务,模型通过该任务预测图像或视频帧中相机与物体之间的距离。其输出结果为深度图——一种梯度图像,其中较亮的像素代表距离较近的物体,较暗的像素代表距离较远的物体。
这种深度图能够帮助机器理解环境的三维结构,因此在自动驾驶、机器人技术、增强现实和三维场景重建等应用中具有重要价值。 本文将深入探讨多种主流深度估计模型,包括Depth Anything V2、DepthCrafter、MiDaS、Depth Pro、Marigold和FoundationStereo,重点分析它们的优缺点、性能对比,并提供选型建议,助力您找到最适合自身需求的模型。
常用评估指标
-
单目图像深度估计指标
-
AbsRel(平均相对误差):衡量预测深度与真实深度之间的平均相对误差,数值越低越好。
-
δ₁:表示预测深度在真实深度25%误差范围内的像素占比,数值越高越好。
-
F1:在深度图场景中用于衡量边界精度,具体评估模型在深度图中勾勒物体清晰边界的能力,数值越高越好。
-
-
立体图像深度估计指标
-
BP-2(Bad Pixel 2):立体图像中,预测视差与真实视差的差值超过2个像素的像素占比(视差指立体图像对中左右图像中同一点的水平偏移),数值越低越好。
-
D1:立体图像中,视差误差大于3个像素且超过真实视差值5%的像素占比,数值越低越好。
-
EPE(端点误差):整幅图像的平均像素级视差误差,数值越低越好。
-
1. Depth Anything V2
Depth Anything V2是一款单目深度估计模型,能够生成鲁棒性强、细节丰富的深度图,可精准捕捉复杂场景中的精细信息,在各类多样化、复杂场景中均能稳定发挥性能。
单目深度估计仅通过单张RGB图像推断深度,与需要从不同视角拍摄的两张或多张图像的立体视觉或多视图方法不同。该模型的深度预测结果为相对深度,仅能表明像素与相机的远近关系,无法估算真实世界中的绝对距离。
核心特性
相较于前代模型Depth Anything V1,该模型通过三大关键优化实现性能提升:

-
采用高精度合成图像替代所有带标签的真实图像,用于训练教师模型;
-
提升教师模型的容量,并利用其生成带伪标签的真实图像;
-
在大规模带伪标签的真实图像上训练轻量级学生模型,使其既能有效泛化到真实世界数据,又能实现更快的部署速度和更高的效率。
优势
-
与基于Stable Diffusion构建的近期模型(如Marigold)相比,Depth Anything V2系列模型效率显著提升(速度快10倍以上),参数数量更少,且深度估计精度更高;
-
对复杂场景的预测性能稳定可靠,包括复杂布局、透明物体(如玻璃)和反射表面(如镜子、屏幕)等场景。
劣势
现有合成训练数据集的多样性不足,可能会限制模型的泛化能力。
基准测试表现

在这里插入图片描述
-
在DA-2K基准测试集(包含多种动态场景,用于评估合成场景和真实世界场景下的深度估计精度)中,Marigold的准确率为86.8%,而Depth Anything V2的小型模型(基于Vision Transformer骨干网络,ViT-S)表现出显著优势,准确率达到95.3%;
-
在KITTI数据集(包含真实驾驶场景,具有挑战性的光照和环境条件)中,MiDaS V3.1(ViT-L)的AbsRel为0.127,δ₁为0.850,而Depth Anything V2(ViT-L)的AbsRel低至0.074,δ₁高达0.946,性能全面超越前者;
-
latency方面,拥有9.48亿参数的Marigold处理单张图像需5.2秒,准确率为86.8%;而参数规模在3.35亿-8.91亿之间的Depth Anything V2大型模型,仅需213毫秒即可达到97.1%的准确率。
2. DepthCrafter
DepthCrafter是一种视频深度估计方法,专为开放世界视频设计,能够生成时间一致性强、细节丰富的长序列深度图。
该模型解决了视频深度估计中的核心挑战,可处理具有多样化外观、运动状态、相机运动和长度的视频,且无需相机姿态或光流等额外信息。其深度估计结果为相对深度。
核心特性
作为一款视频到深度的模型,它基于预训练的图像到视频扩散模型,通过三阶段训练策略完成训练:
-
第一阶段:在DepthCrafter真实数据集(约20万对视频-深度序列,源自具有多样场景和运动特性的双目视频)上训练模型,帧长范围为1-25帧,以适配短视频的空间和时间层;
-
第二阶段:仅在更长序列(最长110帧)上微调时间层,在控制内存占用的同时捕捉长程时间一致性;
-
第三阶段:在DepthCrafter合成数据集(约3000个序列,源自DynamicReplica和MatrixCity,每个序列约150帧)上微调空间层,以优化深度图的细节精度。
优势
-
能够生成时间一致性强的长序列深度图,在开放世界场景中,对于包含复杂细节的视频,性能优于Depth Anything V2,且无需相机姿态或光流等辅助信息;
-
尽管专为视频深度估计设计,但也可用于单图像深度估计,甚至能生成比Depth Anything V2更精细的深度图。
劣势
速度慢于Depth Anything V2,在单张NVIDIA A100 GPU上,处理分辨率为1024×576的图像时,每帧推理时间为465.84毫秒,而Depth Anything V2仅需180.46毫秒。
基准测试表现

在这里插入图片描述
-
在Sintel数据集(包含50帧合成动态图像,常用于评估模型在复杂运动和纹理场景下的性能)中,DepthCrafter的AbsRel为0.270,δ₁得分为0.697,优于Depth Anything V2(0.367/0.554)和Marigold(0.532/0.515),AbsRel指标提升25.7%;
-
在ScanNet数据集(包含90帧室内静态图像,用于评估真实世界室内场景的深度估计性能)中,DepthCrafter的AbsRel为0.123,δ₁得分为0.856,超过Depth Anything V2(0.135/0.822)和Marigold(0.166/0.769),AbsRel指标提升5.4%。
3. MiDaS
MiDaS(基于多数据集融合的单目深度估计)是一种先进的深度学习单目深度估计方法。该模型通过融合多个具有不同深度标注特性的多样化训练数据集,实现了从单张RGB图像中进行鲁棒且泛化性强的深度预测。其深度估计结果为相对深度。
核心特性
-
解决了在具有不同深度范围、尺度和传感模式(如立体相机、激光雷达、结构光传感器)的数据集上训练深度估计模型的难题;
-
在视差(逆深度)空间中采用新颖的尺度和位移不变损失函数,使模型能够在深度尺度和全局位移未知的情况下,从异构数据集中有效学习;
-
基于多目标优化的原则性数据集融合策略,通过合理组合数据集最大化模型泛化能力;
-
引入新的大规模数据集,该数据集源自3D电影,包含从19部影片中提取的75074帧训练数据,为模型训练提供了多样化的动态场景。
优势
-
零样本跨数据集迁移能力强,无需微调即可在未见过的数据集上稳定运行,且支持融合多个标注不兼容的数据集进行训练;
-
不仅能对照片进行合理的深度估计,还能处理线稿和绘画作品,只要这些图像中存在一定的视觉深度线索。
劣势
-
继承了训练数据中存在的部分偏差,例如图像重建时可能会出现图像下部物体始终更靠近相机的偏差,这一问题与人类的深度标注方式相关;
-
对旋转图像的处理能力较弱,容易误解反射和绘画内容,仅根据图像内容而非物理位置推断深度;
-
常见失效场景包括:强边缘处的虚假深度、遗漏细小组件、非连接物体间的相对深度判断错误,以及由于分辨率限制和远距离真实值不完善导致的背景模糊。
基准测试表现

在这里插入图片描述
以仅在ReDWeb(RW)数据集上训练、基于ImageNet预训练ResNet-50编码器的基准模型为对比对象:
-
在ETH3D数据集(用于评估室内外环境下的高精度度量深度)中,MiDaS的AbsRel为0.129,性能提升14.6%;
-
在TUM数据集(包含有人物的动态室内场景,用于测试模型在复杂运动和遮挡情况下的性能)中,MiDaS的δ₁准确率达到0.8571,性能提升34.1%。
4. Depth Pro
Depth Pro是一款基础模型,专为零样本度量单目深度估计设计,能够从单张图像中生成高分辨率深度图,无需相机内参或图像元数据。该模型输出的深度图以物理单位(米)计量,不存在歧义或尺度不确定性,属于绝对深度图。
核心特性
-
零样本度量深度估计:无需焦距、光学中心等相机内参,也无需EXIF元数据、领域标签或在目标图像上进行预调优,适用范围广泛;
-
高分辨率与清晰边界:输出分辨率为1536×1536像素的深度图,能以极高精度捕捉物体的精细结构和边界(如头发、毛发、植被等);
-
高效快速推理:处理速度快,在标准V100 GPU上生成225万像素的深度图仅需0.3秒。采用基于补丁的多尺度视觉Transformer(ViT)架构,支持高度并行运算,非常适合交互式和实时应用场景;
-
边界聚焦的进阶训练:采用两阶段训练方法,首先利用真实和合成数据集实现广泛泛化,然后在合成数据上通过多尺度导数损失函数优化边界精度,确保即使在真实值监督不完善或存在噪声的情况下,模型仍能保持良好性能。
优势
-
在标准GPU(如V100)上,可在0.3秒内生成原生分辨率为1536×1536的深度图;
-
无需相机内参即可输出具有绝对尺度的度量深度结果。
劣势
-
对透明物体和体积散射场景的处理能力较弱,这类场景中像素级深度估计本身存在固有的歧义性或不适定性;
-
依赖合成数据集获取高质量真实值,可能会限制模型在某些训练场景中的真实性。
基准测试表现

在这里插入图片描述
-
在Sintel基准测试中,Depth Pro的F1得分为0.409,远超Depth Anything V2(0.228)、MiDaS(0.181)和Marigold(0.068),边界精度提升1.8倍至6倍;
-
在Sun-RGBD基准测试中,Depth Pro的δ₁得分为0.89,优于Depth Anything V2(0.724),在所有参评模型中展现出卓越的零样本度量深度准确率。
5. Marigold
Marigold是一系列模型及微调协议,旨在将预训练的文本到图像扩散模型(如Stable Diffusion)重新用于密集图像分析任务,包括单目深度估计。
该协议充分利用大规模生成模型中蕴含的丰富视觉先验知识,通过小型高质量合成数据集进行微调,实现了强大的泛化能力。其深度估计结果为相对深度。
核心特性
-
生成式条件扩散:将深度估计视为条件图像生成问题,基于输入RGB图像建模深度图的分布。从含噪声的 latent 表示出发,根据输入图像特征逐步去噪,最终生成深度图;
-
仿射不变深度归一化:对深度图进行仿射不变归一化处理,确保预测结果对不同场景中的未知尺度和位移具有鲁棒性,保障跨数据集和跨环境的迁移可靠性;
-
合成数据训练:仅在合成数据集上训练,这类数据集提供了完整、无噪声的数据,不存在像素缺失和真实世界采集伪影,支持密集监督和高效学习。尽管如此,Marigold在各类真实世界基准测试中仍表现出出色的泛化能力。
优势
-
基于预训练的Stable Diffusion模型构建,在单张NVIDIA RTX 4090 GPU上仅需约2.5天即可完成训练;推理速度快,在标准硬件上运行时间不足0.1秒,大多数实验室和研究人员均可便捷使用;
-
零样本迁移能力强,在未见过的数据集上表现达到当前最优水平。即使不使用任何真实图像,也能准确提取深度图、表面法向量和本征图像分解结果。
劣势
-
合成数据与真实数据之间存在多样性不足和领域差异问题,可能会限制模型的泛化能力;
-
默认处理分辨率为768像素,对大幅图像进行下采样和上采样处理时会导致细节丢失。
基准测试表现

在这里插入图片描述
模型展现出强大的零样本泛化能力,无需任何真实深度标注即可实现优异性能:
-
在NYUv2大型室内RGB-D数据集上,Marigold v1.1的AbsRel为0.055-0.059,δ₁为0.961-0.964,性能优于MiDaS,接近Depth Anything V2;
-
在ETH3D数据集(包含室内外场景的高精度深度图像)上,Marigold-Depth v1.1的AbsRel为0.069,δ₁为0.957,性能超越Depth Anything V2。
6. FoundationStereo
立体深度估计通过分析一对左右图像中对应物体的视差来计算场景深度。尽管深度立体匹配方法已取得显著进展,但这类方法通常需要针对特定领域进行微调,需在适配驾驶场景、室内空间或户外环境等特定环境的数据集上重新训练模型。
相比之下,CLIP和DINO等视觉基础模型展现出卓越的零样本泛化能力,无需额外训练即可在多种任务中高效发挥作用。FoundationStereo将这种零样本能力拓展至立体深度估计领域,使单一模型无需领域特定再训练即可泛化到多种场景。
该模型在输入立体图像对时,可输出绝对(度量尺度)深度。
核心特性
-
训练数据集:基于FoundationStereo数据集(FSD)训练,该数据集是大规模合成数据集,包含超过100万对多样化、照片级真实感的立体图像对,涵盖室内外场景、飞行物体和多种相机设置。通过自筛选流程自动移除模糊或低质量样本,确保数据质量和模型鲁棒性;
-
特征融合:融合来自Depth Anything V2等大规模深度模型的单目先验知识,通过基于CNN的侧调优适配器(STA)融合单目和立体特征,提升模糊或无纹理区域的估计精度;
-
迭代优化:采用基于GRU的迭代优化流程,以粗到精的方式逐步优化视差预测结果,并结合上下文单目先验知识实现更精准的深度估计。
优势
-
零样本性能出色,可泛化到多种未见过的领域,包括室内、户外和纹理缺失环境,无需针对特定领域进行微调;
-
基于100万对照片级真实感合成立体图像对训练,通过自动筛选移除模糊样本,远超以往依赖Scene Flow等含4万对图像数据集的立体深度模型。
劣势
-
模型效率尚未优化,在NVIDIA A100 GPU上处理375×1242分辨率的图像需0.7秒;
-
训练数据集包含的透明物体样本有限,可能会影响模型在这类场景下的鲁棒性。
基准测试表现
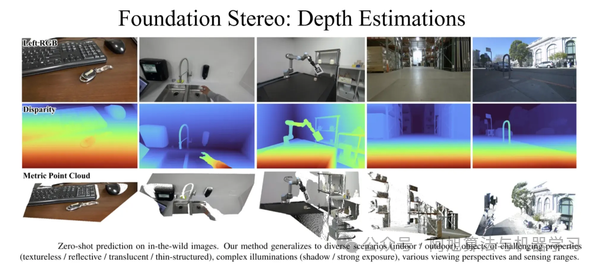
在这里插入图片描述
-
在Middlebury数据集(用于评估高质量室内立体图像)上,模型的BP-2仅为1.1%,即每100个像素中仅有1个像素的误差超过2个像素;
-
在KITTI真实驾驶基准测试中,该模型在KITTI-12数据集上的D1误差为2.3%,在KITTI-15数据集上为2.8%,在安全关键的自动驾驶场景中展现出可靠性能;
-
在Scene Flow合成基准测试中,将EPE从0.41降至0.33,相比以往最优模型提升约20%,凸显其出色的合成到真实场景泛化能力。
如何选择最优深度估计模型
-
综合平衡之选:Depth Anything V2:整体性能均衡,推理速度快(每帧约0.3秒),在多样化场景中鲁棒性强,能输出高质量结果且无明显速度损耗。提供从小型到巨型等多种模型尺寸供选择;
-
质量最优之选:Marigold与Depth Pro:适合优先考虑质量而非速度的场景。Marigold擅长捕捉极致精细的细节,但速度相对较慢,单张图像处理需1-2秒;Depth Pro则兼具清晰边界、精准度量深度和更快的处理速度,处理225万像素图像仅需约0.3秒;
-
视频场景之选:DepthCrafter:专为视频设计,注重时间一致性,可一次性处理1-110帧(可变长度),能有效消除闪烁伪影;
-
立体相机场景之选:FoundationStereo:立体相机配置下精度最高的方案。通过利用几何约束,经适当校准后可输出真实度量深度,是机器人技术和三维重建领域的成熟解决方案;
-
无相机内参需求之选:Depth Pro:无需相机内参即可实现真实度量深度估计,内置焦距估计功能,可将估计的逆深度转换为具有绝对尺度的真实度量深度。
总结
深度估计领域正快速发展,不同模型针对特定任务各具独特优势。通过深入了解各模型的优势与局限,您可以选择最符合项目需求的解决方案。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









