




本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/1gJW6fiNsBnWY4Jj1UVzTQ

精简阅读版本
本文主要解决了什么问题
-
1. 如何在保持低延迟和轻量级架构的同时,提高图文模型(如CLIP)的零样本准确率。
-
2. 如何改进多模态强化训练方法,使其更高效、可扩展且可重现。
-
3. 如何优化数据集质量、教师模型选择和字幕生成器,以提升小规模模型的性能。
本文的核心创新是什么
-
1. 提出了改进的多模态强化训练方法,包括使用更好的CLIP教师集成(DFN数据集训练)和改进的字幕生成器(在DFN数据集上训练并微调)。
-
2. 引入了新的模型架构变体(MobileCLIP2-S3和MobileCLIP2-S4),采用五阶段设计,显著提升了高分辨率下的推理效率。
-
3. 通过消融实验发现了对比知识蒸馏中温度调整的重要性、字幕生成器微调对字幕多样性的有效性,以及结合多个模型生成的合成字幕的改进效果。
结果相较于以前的方法有哪些提升
-
1. MobileCLIP2-B在ImageNet-1k准确率上比MobileCLIP-B提升了2.2%。
-
2. MobileCLIP2-S4在ImageNet-1k上的零样本准确率与SigLIP-SO400M/14相当,但体积小2倍,延迟降低2.5倍,同时优于DFN ViT-L/14。
-
3. 在密集预测任务(如实例分割、语义分割和深度估计)上,MobileCLIP2预训练显著优于监督预训练,成为分层架构的良好预训练选择。
局限性总结
-
1. DFNDR-2B数据集对零样本分类任务(特别是ImageNet-1k)存在偏向,导致在检索任务上的性能不如DataComp及其衍生数据集训练的模型。
-
2. 合成字幕的多样性和数量对性能的提升有限,超过一定数量后收益饱和。
-
3. 长上下文支持不足,当前模型对长描述的处理能力有限,未来需结合改进的损失函数和训练策略进一步优化。
深入阅读版本
导读
具有零样本能力的基础图文模型(如CLIP)能够实现广泛的应用。MobileCLIP是最近的一族图文模型,具有3-15毫秒的延迟和50-150M参数,并具有最先进的零样本准确率。MobileCLIP的主要组成部分是其低延迟和轻量级架构,以及一种新颖的多模态强化训练,这种训练使得从多个字幕生成器和CLIP教师进行知识蒸馏变得高效、可扩展和可重现。在本文中,作者通过以下方式改进了MobileCLIP的多模态强化训练:1) 在DFN数据集上训练的更好的CLIP教师集成,2) 在DFN数据集上训练并在多样化的高质量图像-字幕数据集选择上进行微调的改进的字幕生成器教师。作者通过消融实验发现了新的见解,例如对比知识蒸馏中温度调整的重要性,字幕生成器微调对字幕多样性的有效性,以及结合多个模型生成的合成字幕所带来的附加改进。作者训练了一个名为MobileCLIP2的新模型族,并在低延迟下实现了最先进的ImageNet-1k零样本准确率。特别是,作者观察到与MobileCLIP-B架构相比,MobileCLIP2-B在ImageNet-1k准确率上有的提升。值得注意的是,MobileCLIP2-S4在ImageNet-1k上的零样本准确率与SigLIP-SO400M/14相当,但体积小2倍,并在延迟低的情况下改进了DFN ViT-L/14。作者发布了作者的预训练模型1和数据生成代码2。数据生成代码使得使用分布式可扩展处理创建具有任意教师的新强化数据集变得容易。
1 引言
CLIP (Radford等人, 2021) 是一个图像-文本模型,它将图像和文本输入映射到一个共享的嵌入空间,在这个空间中,描述图像的文本(也称为标题)被映射到与其描述相匹配的图像附近,而远离不相似的图像。基于大量文献(Frome等人, 2013; Socher等人, 2014; Karpathy & Fei-Fei, 2015; Kiros等人, 2014; Faghri等人, 2018),CLIP大幅增加了训练数据和模型的规模。因此,随着图像-文本检索性能的提升,新的zero-shot分类能力也出现了,在没有通过linear probing进行任何带有分类标签的显式监督训练的情况下,在分类任务上取得了不可忽视的准确率。图像编码器可以通过linear probing(固定编码器)或full fine-tuning来进一步专门化以适应新任务,从而在各种任务上实现state-of-the-art性能(Wortsman等人, 2022)。鉴于其能力和应用的多样性,CLIP是最早被称为foundation model的模型之一(Bommasani等人, 2021)。
CLIP的成功导致模型和数据集规模的增加,从而使性能逐步提升(Fang等人,2024b;Zhai等人,2023;Gadre等人,2023;Fang等人,2024a)。最近,这一趋势已经逆转为适用于移动设备应用的小尺寸、低延迟模型。值得注意的是,TinyCLIP(Wu等人,2023)和MobileCLIP(Vasu等人,2024c)提出了总参数(图像和文本编码器参数之和)少至5000万的模型。例如,MobileCLIP-S0的总延迟为3毫秒(图像和文本编码器延迟之和),在比原始OpenAI ViT-B/16 CLIP小且快5倍的情况下,实现了相似的平均性能。与之前的最先进大型模型(如SigLIP(Zhai等人,2023))相比,它也表现出改进的性能。
本文中,作者提出了多模态强化训练的消融研究,并提出了一种改进的训练方案。作者训练了一系列新模型MobileCLIP2,该模型在一系列延迟条件下实现了新的最先进ImageNet-1k准确率,匹配了更大的SigLIP (Zhai et al., 2023)和DFN (Fang et al., 2024a)模型的性能,同时体积小了高达4 (作者的MobileCLIP2-S2与SigLIP2-B/32相比),并且速度快了高达(作者的MobileCLIP2-S4与DFN ViT-L/14相比)。此外,作者发布了高效的分布式代码,用于使用任意教师模型生成强化数据集。
2 改进的训练
MobileCLIP引入了一系列低延迟图像文本模型,包括S0、S1、S2、B和B-LT变体,其综合图像文本延迟范围为3.8-13.7毫秒。这些低延迟是通过基于FastViT(Vasu等人,2023b)的专门架构和一种称为多模态强化训练(multi-modal reinforced training)的改进训练方法实现的。作者寻求进一步探索和改进多模态强化训练的每个步骤。作者还考虑了更多样化的架构家族,以覆盖更广泛的延迟范围。
强化训练是一种通过预训练模型等额外来源的改进来从基础数据集获得更好性能的方法(Faghri等人,2023)。Vasu等人(2024c)中提出的多模态强化训练通过预训练的图像-文本模型以及预训练的合成字幕生成器向图像-文本数据集添加信息。具体来说,他们向DataComp-1B数据集添加了以下额外信息:1)来自两个CLIP教师模型对每张图像的10次随机增强的图像嵌入;2)来自两个CLIP教师模型对原始文本以及由CoCa字幕生成器生成的5个合成字幕的文本嵌入。给定一个强化数据集,他们修改训练损失以包含基于教师模型对每个样本的嵌入的知识蒸馏损失(Hinton等人,2015)。为确保教师模型和学生模型之间的一致性,通过存储的增强参数重现相同的图像增强(Beyer等人,2022;Faghri等人,2023)。他们进行消融实验,以找到在ImageNet上提供最大性能提升以及在DataComp的38项评估中提供最高平均准确率的CLIP教师模型、字幕生成器和图像增强的组合(Gadre等人,2023)。
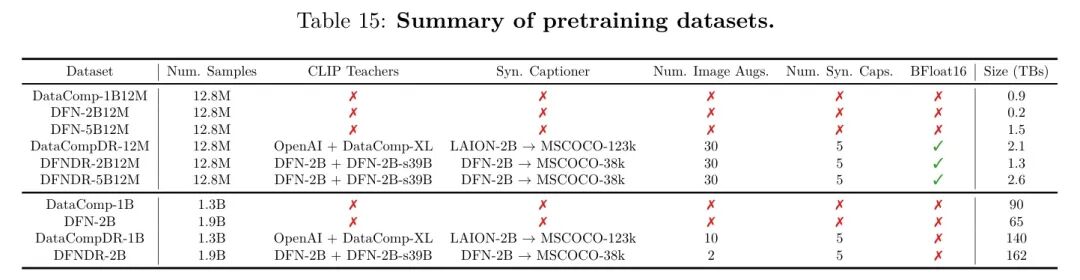
作者遵循与MobileCLIP类似的多模态强化训练方法,同时在所有方面进行了改进,并将得到的模型系列命名为MobileCLIP2。表1总结了每项主要改进带来的收益。简而言之,与MobileCLIP相比,作者使用了更好的训练数据、更好的CLIP教师模型,以及更好更多样的合成字幕生成器。在所有消融实验中,作者在包含1280万张图像的数据集上训练MobileCLIP-B模型进行了30k次迭代(约20个周期)。作者在表15中提供了本文使用的数据集的摘要。
2.1 多模态强化训练
Dataset Reinforcement (DR) (Faghri等人, 2023)是一种改进数据集的方法,旨在以对训练代码的最小更改和最小的计算开销实现更高的准确性。DR最初被引入用于训练图像分类器,Faghri等人(2023)通过高效存储来自强大分类器集成的分类概率来改进ImageNet数据集。在给定存储的概率的情况下,训练本质上是Knowledge Distillation (Hinton等人, 2015),无需计算教师预测的开销。成本效率使得进行更长时间的训练以获得更大的收益成为可能,正如Beyer等人(2022)所观察到的。Vasu等人(2024c)采用DR来训练图像-文本CLIP模型,通过存储来自强大CLIP模型集成的知识以及来自图像标题生成器的合成标题。他们证明了与非增强CLIP训练相比,学习效率提高了高达1000x。

2.2 更好的基础数据集:DFN
多模态强化训练始于一个基础数据集,该数据集包含通常从网络收集的真实图像-文本对。DataComp(Gadre等人,2023)证明,通过基于图像和文本兼容性等分数进行过滤,可以显著提高大规模图像-文本数据集的质量。他们提出的BestPool过滤方法应用于120亿样本池,生成了DataComp-1B数据集,该数据集被用作MobileCLIP中的基础数据集。DataComp还发布了原始的120亿样本作为数据集筛选和过滤方法的基准。DFN(Fang等人,2024a)提出使用在高质量数据上训练的过滤网络来过滤数据。将他们的模型应用于DataComp-12B样本池生成了DFN-2B数据集。他们另外从网络收集了与DataComp-12B不重叠的更大规模图像集,经过过滤后得到另外30亿样本,并共同创建了DFN-5B数据集。
作者研究了用DFN-5B替换MobileCLIP中的基础数据集的影响。作者使用DataComp-1B的1200万均匀采样子集(称为DataComp-1B12M)进行消融实验,该子集在(Vasu et al., 2024c)中引入,用于快速实验。作者同样从DFN-5B中采样了一个1200万的子集,称为DFN-5B12M。表2比较了使用和不使用蒸馏/合成标题进行训练的性能。作者观察到,DFN-5B12M结合蒸馏和合成标题可带来高达1.4%的性能提升。尽管与不使用蒸馏/合成标题时高达6%的增益相比,这一增益较小,但它仍然超过了标准差。

2.3 DFN CLIP 教师
在多模态强化训练中,一种强化来源是来自CLIP教师的嵌入,这些嵌入在CLIP蒸馏中被用作目标。(Vasu等人,2024c)对发表时现有的强大CLIP教师进行了全面研究,并发现ViT-L-14-openai和ViT-L-14-datacomp_xl_s13b_b90k的集成能够带来最佳的学生模型性能。在这里,作者研究DFN预训练模型作为教师模型的有效性。基于ViT-L-14和ViT-H-14架构的DFN预训练CLIP模型在DataComp的Avg. 38项评估中实现了最先进的性能(Fang等人,2024a),优于其他流行模型如SigLIP(Zhai等人,2023)。
由于字幕生成器和CLIP教师的选择可能相互依赖,作者通过分析CLIP教师对未微调的CoCa模型生成的合成字幕的影响来降低分析的复杂性(见第2.4节)。作者在第2.5节中通过微调来探索合成字幕的多样性。
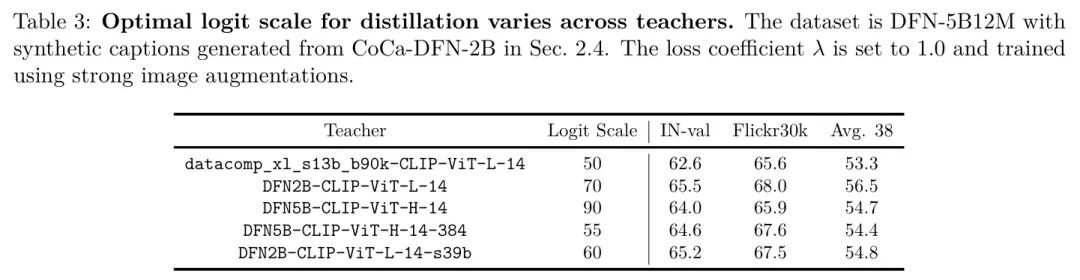
Logit scaling. CLIP模型在训练过程中使用一个在0-100范围内调整的logit scale进行训练。MobileCLIP使用与KD loss中的temperature scaling相同的logit scalar。作者观察到DFN和DataComp模型中的logit scalar对于KD并非最优,因此作者进一步调整了该参数。表3显示了用于训练MobileCLIP-B模型的每个教师模型所使用的最优logit scale。作者观察到logit scale不是一个敏感的hyperparameter,在5点范围内的值都能达到相似的性能。
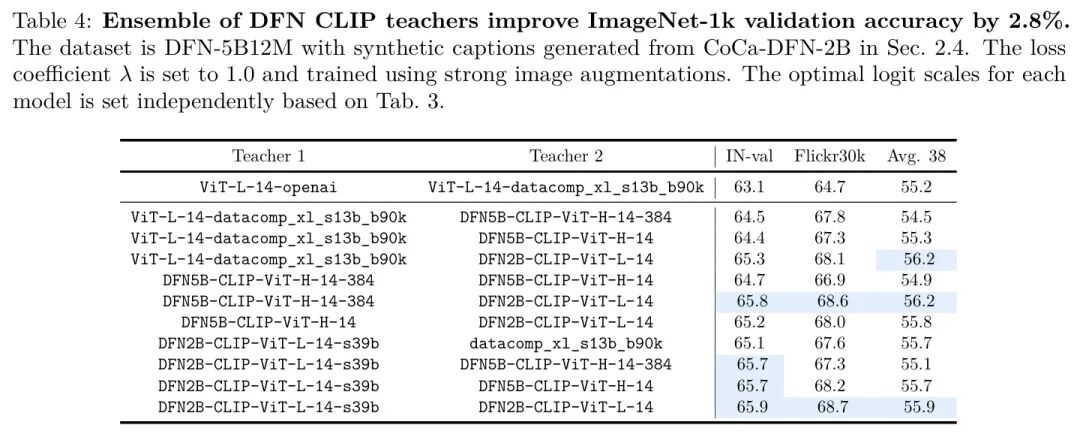
集成教师。作者使用DataComp和DFN教师构建大小为二的集成。表4展示了使用各种集成的嵌入训练MobileCLIP-B模型的性能。与MobileCLIP中使用的教师相比,作者观察到显著的改进。具体而言,IN-val和Flickr30k的性能提高了高达3%。基于其性能和成本效率,作者为MobileCLIP2选择了DFN2B-CLIP-ViT-L-14-s39b和DFN2B-CLIP-ViT-L-14的集成,与其他更大或更高分辨率的集成相比。作者利用为集成中每个成员独立找到的最优logit尺度。当一起使用时,集成的最优logit尺度可能会有所不同,但作者没有进一步联合优化logit尺度。
2.4 DFN 字幕生成器
训练MobileCLIP2的另一种增强来源是由图像标题生成器生成的合成标题。MobileCLIP使用了一个单一的CoCa标题生成器,该生成器具有双塔图像文本架构,并配有一个文本解码器(Yu et al., 2022)。与大多数最新的VLM相比,文本解码器相当轻量级,这使得整体标题生成器比最近的VLM相对更快(Liu et al., 2024b; Vasu et al., 2024a)。由于MobileCLIP在数十亿张图像上生成了多个合成标题,运行CoCa的成本是一个重要的决策因素。他们没有对标题生成器的选择提供分析,但观察到使用合成标题进行训练相比不使用合成标题有显著提升(30k训练迭代中提升了7.4%)。MobileCLIP每张图像生成5个合成标题,尽管他们观察到大部分增益来自前1-2个合成标题。
作者探索使用DFN数据集训练一个新的CoCa模型,以提高合成字幕的质量。作者采用与MobileCLIP中使用的CoCa模型相同的架构,该架构基于ViT-L/14图像编码器。他们利用了在LAION-2B数据集上训练并在MSCOCO-128k数据集上微调的模型。作者使用OpenCLIP (Ilharco等人, 2021)在DFN-2B上对相同的架构进行预训练,处理了130亿个已见样本。
2.5 微调字幕生成器
在第2.4节中,作者展示了在DFN-2B上预训练CoCa模型,当用于多模态强化训练时,会带来IN-val和Avg. 38性能的提升。然而,检索性能却有所落后,这是由于缺乏在高质量数据集上的fine-tuning。MobileCLIP使用了在MSCOCO (Chen et al., 2015)上进行fine-tuning的CoCa模型。MSCOCO-2017包含12.3万张带有字幕的图像,这些字幕的质量高于DataComp和DFN数据集中的平均图像-文本对。
在本节中,作者研究了微调对各种高质量数据集的影响。除了来自MSCOCO的123k个样本(作者称之为MSCOCO-123k)外,作者还考虑了一个包含38k个样本的子集,这些样本具有宽松的许可证(CC署名2.0、CC署名-相同方式共享2.0和CC署名-禁止演绎2.0),作者称之为MSCOCO-38k。作者还考虑了GBC-1M/10M(Hsieh等人,2024)、DOCCI-9kshort/extended/complete(Onoe等人,2025)、DCI-8k(Urbanek等人,2024)和ReCap-COCO-30k(Li等人,2024)。作者在每个数据集上对DFN-CoCa进行微调,处理12M个已见样本,使用与CoCa预训练相同的损失函数。
在MSCOCO38k和MSCOCO128k上进行微调。作者观察到,将微调限制在具有宽松许可证的MSCOCO样本上不会对性能产生负面影响。
关于合成字幕数量和束搜索的消融研究
(Vasu等人,2024c)观察到,尽管可以从CoCa模型生成多个合成字幕,但对于分类任务,其有效性在每个样本2个时达到饱和。作者使用单个CoCa模型和不同的采样策略观察到了类似的结果。作者探索了不同的生成方法和超参数。具体来说,作者使用了top-p、top-k和beam-search,并观察到beam-search在质量上产生了更多样化的字幕,然而,当用于强化训练时,作者没有观察到下游性能有任何改善。
在GBC1M、GBC12M、DOCCI、DCI、ReCap-COCO30k上进行fine-tuning。作者观察到大多数fine-tuning数据集的表现不如MSCOCO fine-tuning,或者在一个标准差范围内表现相当。一个例外是在DOCCI上进行fine-tuning,在38项评估中平均提升了,这比MSCOCO-38k的结果超过了一个标准差。
上下文长度的影响
训练CLIP和CoCa模型的上下文长度通常设置为77。作者通过将训练和生成的上下文长度设置为255,探索训练CoCa模型以生成更长的描述。大多数结果保持在一个标准差范围内。最近的研究通过改进的损失函数和训练策略,提高了CLIP模型对长描述的支持(Zhang等人,2024;Zheng等人,2024;Najdenkoska等人,2024)。作者将将这些修改扩展到CoCa模型的工作留给未来研究。
合成字幕多样性的影响
作者进一步探索使用由在不同数据集上微调的CoCa模型集合生成的多样化字幕集合进行训练。其动机是微调数据集的多样性会增加合成字幕的多样性,从而提高额外合成字幕的有效性。作者观察到,使用多达10个不同的CoCa模型所得到的性能仍然在最佳性能的一个标准差范围内。
增强型DFN数据集
作者的最终数据集DFNDR-5B12M和DFNDR-2B12M包含5个使用MSCOCO-38k进行微调的合成标题,以及来自第2.3节讨论的两个DFN2B-ViTL/14教师模型集成的嵌入,这些嵌入用于30种图像增强以及真实标题和合成标题。作者探索了仅在DFN的2B子集上进行训练,与使用DataComp的12B数据池之外的3B样本扩展的完整5B数据集进行对比。表7显示,对于两个数据集,在38项评估中的平均性能都在标准偏差范围内,而使用来自5B的12M样本时,ImageNet-1k验证准确率更高。然而,作者没有观察到在更大规模训练时这种改进能够保持,因此作者将作者的方案限制在2B数据集上。
3 架构
作者的MobileCLIP2包含与MobileCLIP相似的架构以及两个新变体。具体来说,作者训练了MobileCLIP2-S0、MobileCLIP2-S2和MobileCLIP2-B,其中作者为MobileCLIP2-S0使用标准的"Base"文本编码器,并舍弃了S1变体。除了MobileCLIP中引入的架构外,作者在MobileCLIP2系列中引入了两个新变体,即MobileCLIP2-S3和MobileCLIP2-S4。这些变体的文本编码器是基于纯transformer的架构,而图像编码器基于FastViT(Vasu等人,2023b),该架构使用了(Vasu等人,2023a)中引入的训练时过参数化块。较小的变体MCi0、MCi1和MCi2是具有四个不同计算阶段的混合视觉transformer。作者为MCi3和MCi4引入了一个额外的transformer阶段,该阶段之前对输入张量进行下采样,如图3a所示。当扩展规模时,5阶段设计有两个优势;首先,参数可以分布在五个阶段中,最大的层在四倍更少的token上运行。
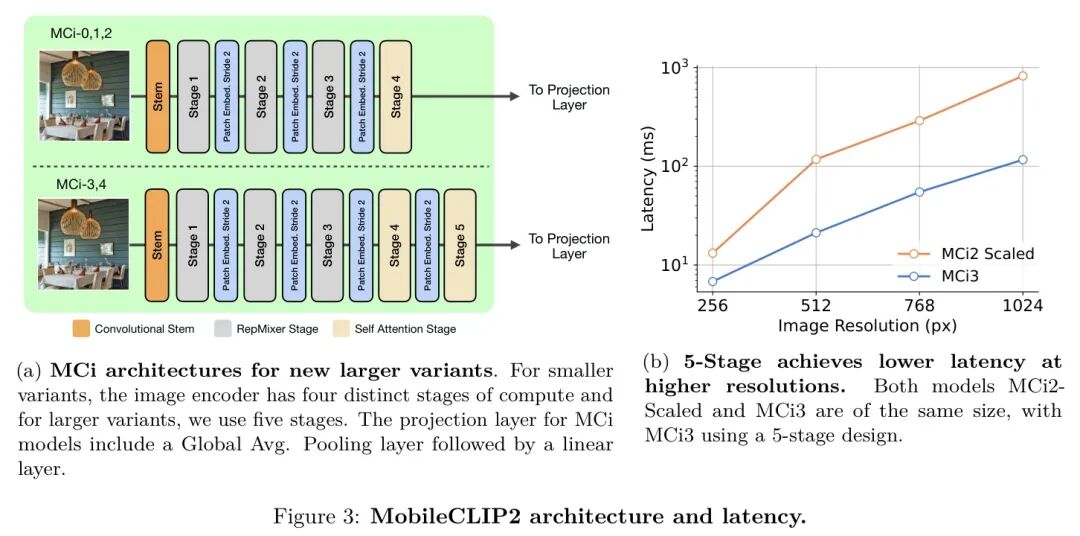
其次,该设计能够更有效地扩展到更高分辨率。
作者通过多种图像分辨率实证验证了作者的设计选择。在图3b中,作者将MCi2缩放至与MCi3相同的大小(1.25亿参数),并在四种输入分辨率上对其性能进行基准测试。作者的结果表明,采用五阶段设计的MCi3与缩放后的MCi2相比,提供了显著更好的权衡。在低图像分辨率(即256 256)下,MCi3比同等大小的MCi2快1.9倍;而在更大的输入分辨率(即1024 1024)下,MCi3比同等大小的MCi2快7.1倍。当图像编码器针对密集预测任务(如图像分割,其输入图像分辨率为512 512)进行微调时,更高分辨率的响应能力尤为重要。
4 实验
在本节中,作者训练了一个新的高效CLIP模型系列MobileCLIP2,并在多样化的任务集上进行了评估。根据作者在第2节的发现,作者创建了增强数据集DFNDR-2B,其中包含由作者的CoCa-ViT-L/14模型生成的五个合成标题,该模型在DFN-2B上预训练并在MSCOCO-38K上微调。DFNDR-2B还包含来自CLIP模型集成DFN2B-CLIP-ViT-L-14-s39b和DFN2B-CLIP-ViT-L-14的图像文本嵌入,适用于所有图像、真实标题和合成标题。与MobileCLIP相比,作者训练了更多样化的架构系列,并在38个零样本分类任务上评估了它们的性能(Gadre等人,2023)。特别是,作者介绍了在DFNDR-2B上训练的MobileCLIP2-S3和MobileCLIP2-S4架构,以及在DataCompDR-1B上训练的变体,作者称之为MobileCLIP-S3和MobileCLIP-S4。表8显示了作者的结果与其他具有相似延迟的模型的比较。训练和超参数的细节在附录A中描述。
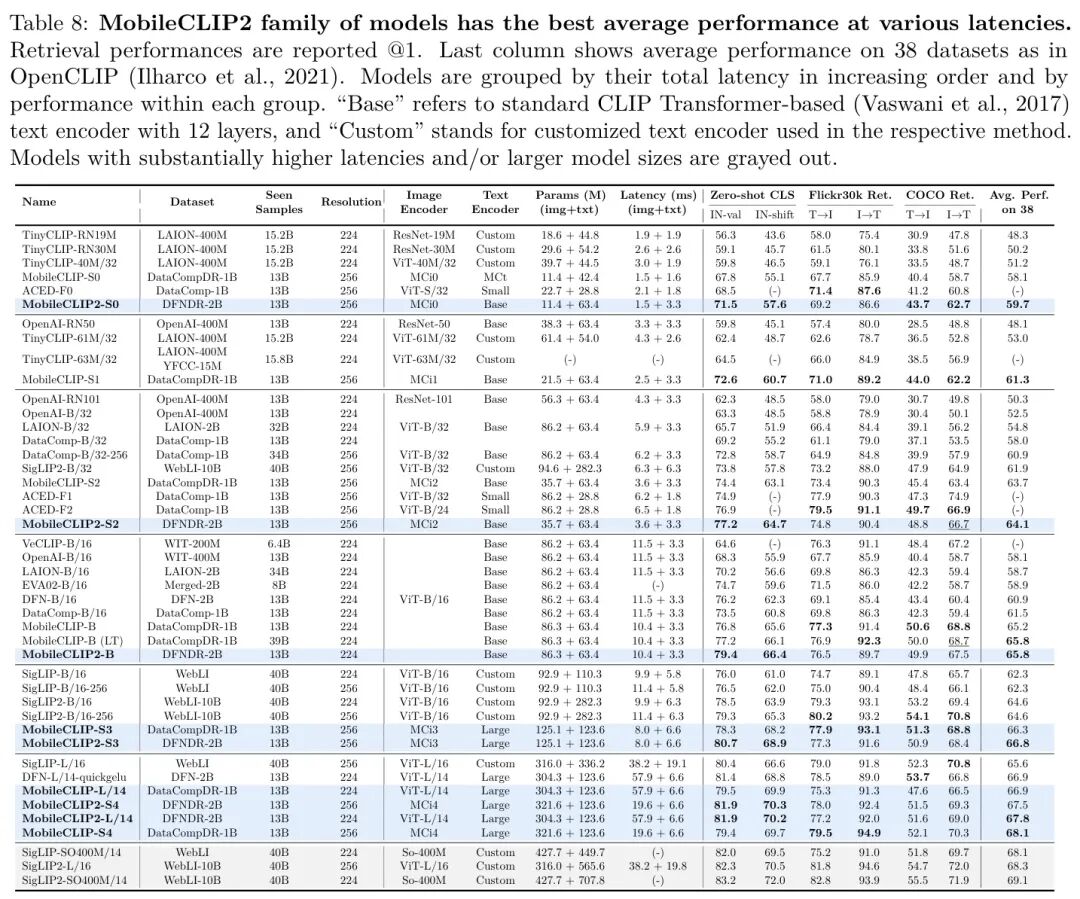
作者将MobileCLIP2与先前的小型CLIP架构TinyCLIP(Wu等人,2023)进行比较,该架构在LAION(Schuhmann等人,2022;2021)和ACED(Udandarao等人,2024)上进行了训练。作者还与来自OpenAI的CLIP(Radford等人,2021)、DataComp(Gadre等人,2023)、VeCLIP(Lai等人,2023)、EVA(Sun等人,2023)、DFN(Fang等人,2024a)、SigLIP(Zhai等人,2023)和SigLIP2(Tschannen等人,2025)的更大模型进行了比较。作者使用OpenCLIP(Ilharco等人,2021)和DataComp(Gadre等人,2023)评估所有模型。在某些情况下,如SigLIP2,作者观察到与其论文中报告的结果存在正/负差距。
MobileCLIP2在各种延迟下实现了最先进的ImageNet-1k验证零样本准确率。值得注意的是,MobileCLIP2-S4在ImageNet验证集上匹配了SigLIP-SO400M/14的零样本准确率,同时体积小了2 ,并在延迟降低2.5 的情况下优于DFN ViT-L/14。考虑到延迟,作者也改进了ACED模型在ImageNet-1k上的性能。由于ACED针对低推理浮点运算次数优化了他们的模型,ACED-F1和ACED-F2的延迟与作者的MobileCLIP2-S2架构相当,但仍有更高的延迟和更多参数。SigLIP-B/16和SigLIP2-B/16模型在大小和延迟上更接近作者新的更大架构。特别是,与SigLIP模型相比,SigLIP2模型的文本编码器要大得多。
作者注意到,在DFNDR-2B上预训练的模型并不总能达到最先进的检索性能。作者将此归因于DFNDR-2B数据集对零样本分类任务特别是ImageNet-1k的偏向。作者观察到,在DataComp、WebLI及其衍生数据集上训练的模型与DFN数据集及其衍生数据集相比可能实现更高的检索性能,但在Avg. 38性能上较低。因此,作者也在DataCompDR-1B上训练了作者的新架构,称为MobileCLIP-S3和MobileCLIP-S4。这两类架构的组合将为更广泛的应用提供灵活性。
4.1 VLM评估
作者报告了在LLaVA-1.5设置(Liu et al., 2024a)中使用MobileCLIP2预训练模型进行的视觉语言评估。作者在所有运行中保持视觉 Backbone 网络冻结,并使用Qwen2-7B替代Vicuna-7B。所有其他训练细节与原始LLaVA-1.5设置相同,更多细节在附录中提供。作者评估了在DataComp、DFN、DataCompDR和DFNDR上预训练的ViT-B/16模型,针对130亿个已见样本。在表9中,作者观察到平均而言,在DFNDR上训练的模型比DFN预训练模型的准确率高3.5%,比DataComp预训练模型高1.6%,比DataCompDR预训练模型高。

4.2 密集预测任务
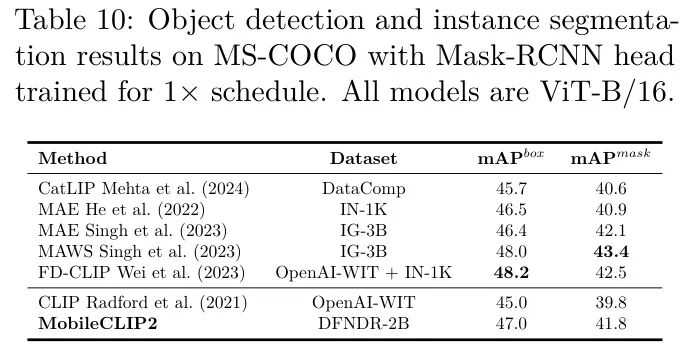
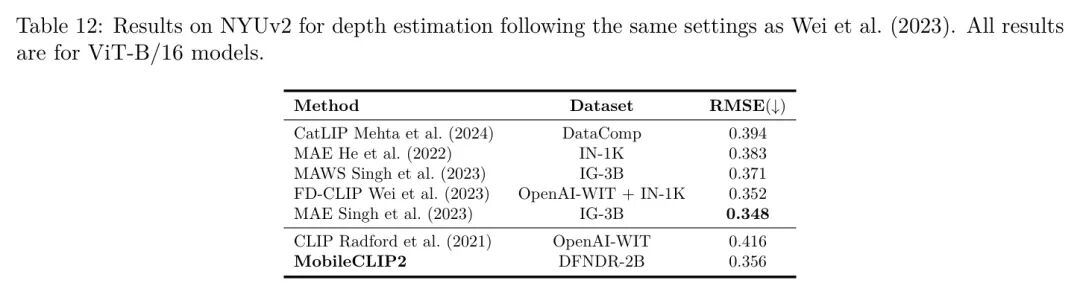
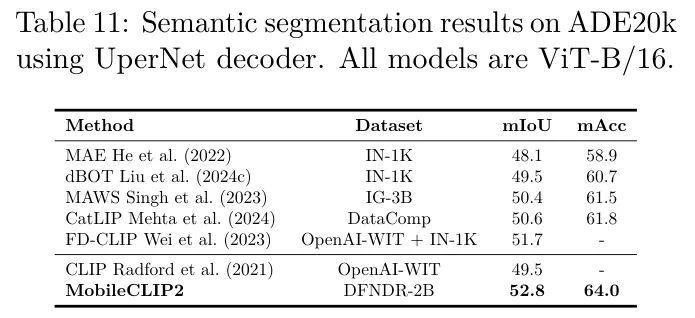
作者通过在目标检测、语义分割和深度估计等密集预测任务上微调图像编码器,来评估所学视觉表示的质量。在表10中,作者报告了使用MaskRCNN He et al. (2017)头的ViT-B/16模型在MS-COCO Chen et al. (2015)数据集上进行实例分割的性能。所有模型均使用MMDetection库Chen et al. (2019)进行训练,采用调度和单尺度测试,如Wei et al. (2023)中所述。作者遵循Wei et al. (2023)中描述的微调设置,更多细节见附录。在表11中,作者报告了使用UperNet Xiao et al. (2018)头的ViT-B/16模型的性能,该模型使用Liu et al. (2024c)中描述的相同设置在ADE20k (Zhou et al., 2017)数据集上进行训练。在表12中,作者报告了在NYUv2数据集Nathan Silberman & Fergus (2012)上的均方根误差(RMSE)。作者使用与Vasu et al. (2024b)中描述的相同设置,更多细节在附录中提供。
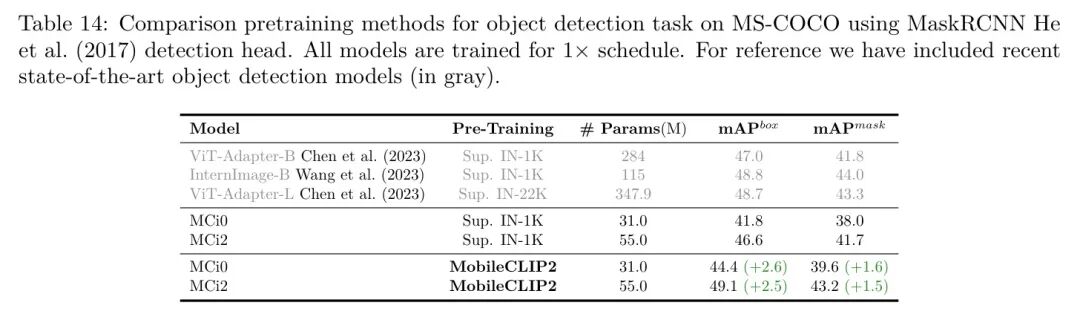
此外,作者评估了较小的MobileCLIP2变体在密集预测任务上的性能。流行的预训练方法如MAE(He等,2022)不直接适用于分层卷积和混合架构,如作者的MCi模型,因此作者将MobileCLIP2预训练与相同架构的监督预训练进行了比较。在表13和表14中,作者看到MobileCLIP2预训练明显优于监督预训练,并且可以成为分层架构的一个良好预训练选择。

5 相关工作
数据方法要么对数据集进行过滤,要么通过额外信息对其进行增强。基本的过滤方法首先选择或爬取大量候选图像-文本对数据集,然后基于URL或图像和描述的统计信息使用特定规则进行过滤(Radford等人,2021;Schuhmann等人,2021;2022;Xu等人,2024)。更先进的过滤方法涉及在高质量数据上训练的过滤模型,用于移除低质量的图像-文本对。这些方法可能利用预训练的CLIP模型(Gadre等人,2023)或更专门的过滤模型(Fang等人,2024a)。数据方法的挑战在于特定规则或预训练模型引入的偏见。例如,大多数公开可用的数据集如DataComp都过滤为仅包含英语数据,这限制了模型在非英语任务上的能力(Carlsson等人,2022;Nguyen等人,2024;Pouget等人,2024)。或者,预训练模型可用于基于样本难度的主动数据选择(Evans等人,2024a;b)。还观察到,重复高质量数据可以实现更高的利用率(Goyal等人,2024)。
更广泛地说,预训练模型的输出可以存储为新增强数据集的一部分。例如,多项研究利用图像描述模型为数据集中的图像生成合成描述(Yang et al., 2023a; Nguyen et al., 2023; Lai et al., 2023; Liu et al., 2024d; Li et al., 2024)。大语言模型也可用于重写真实描述(Fan et al., 2023),以及与文本到图像模型一起生成完全合成的数据集(Hammoud et al., 2024)。MobileCLIP引入了多模态数据集增强方法,他们利用图像描述模型生成合成描述,并使用大型CLIP模型集成来存储多个图像增强和合成描述的CLIP嵌入,并高效存储它们(Vasu et al., 2024c)。作者采用类似的方法,同时通过更好的DFN模型(Fang et al., 2024a)改进描述生成器和CLIP嵌入生成器。
另一种方法是改进多模态训练的目标函数。原始的CLIP论文采用了一种对比损失,该损失鼓励数据集中配对的图像和文本表示彼此保持接近,同时与小批次中的其他图像和文本保持更远的距离(Radford等人,2021)。SigLIP引入了一种基于Sigmoid而非Softmax的变体,在更大的批次大小下实现了更高的训练效率(Zhai等人,2023;Tschannen等人,2025)。其他方法利用基于图像 Mask (Yang等人,2023b;Fang等人,2023;Sun等人,2023;Li等人,2023b)和单模态自监督(Mu等人,2022;Li等人,2021)以及多分辨率训练(Li等人,2023a)的目标函数,以实现经济高效的训练。多模态蒸馏实现了更显著的改进,特别是对于较小的架构变体(Wang等人,2022b;Kuang等人,2023;Wang等人,2022a;Wu等人,2023)。值得注意的是,MobileCLIP(Vasu等人,2024c)通过利用离线知识蒸馏方法(Shen和Xing,2022;Yun等人,2021;Faghri等人,2023)实现了高训练效率。作者利用与MobileCLIP类似的目标函数,包括对图像-文本对和合成标题的嵌入蒸馏。
最后,架构改进旨在在给定参数、flops或延迟预算的情况下提高推理效率和性能。CLIP架构通常借鉴自单模态图像和文本模型。特别是,原始CLIP和后续各种工作使用了标准ViT架构以及修改后的BERT文本编码器(Dosovitskiy等人,2020;Devlin等人,2019;Radford等人,2021)。CLIP的高效架构包括剪枝ViT的TinyCLIP(Wu等人,2023)、减少tokens的Cao等人(2023)的研究,以及通过减少参数来降低flops的Evans等人(2024b)的研究。MobileCLIP引入了专为CLIP设计的高效架构,其中为其图像和文本编码器都引入了低延迟的卷积-Transformer混合架构。作者通过引入两种新的变体进一步改进了他们的架构,这些变体填补了常见B和L架构之间的巨大延迟差距。
6 结论
作者介绍MobileCLIP2,这是一个新的低延迟图像文本模型系列,在ImageNet-1k上实现了最先进的零样本验证准确率。MobileCLIP2通过利用更强大的CLIP教师模型以及作者新训练的图像描述模型来改进多模态强化训练。作者特别对CLIP教师模型的调整和集成以及高效图像描述模型的训练和微调进行了全面研究。值得注意的是,MobileCLIP2-S4在ImageNet-1k上匹配了SigLIPSO400M/14的零样本准确率,同时体积小了2X,并在延迟降低2.5 的情况下优于DFN ViT-L/14。作者发布了MobileCLIP2预训练权重和数据生成代码,这些代码促进了大规模数据集的生成。
参考
[1]. MobileCLIP2: Improving Multi-Modal Reinforced Training
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









