






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:ViT计算复杂度大降50% | BSPF-ViT:基于Block的对称剪枝让视觉Transformer飞起来

精简阅读版本
本文主要解决了什么问题
-
1. 视觉Transformer(ViT)的高计算复杂度问题:由于ViT的自注意力机制具有 O(n^2) 的时间复杂度,导致其在大规模任务中计算开销大,限制了实际部署。
-
2. 现有token剪枝方法的精度下降问题:传统方法通常独立剪枝Query或Key token,忽略了token之间的交互,导致关键信息丢失,从而影响模型性能。
-
3. 缺乏对称性和结构优化的剪枝策略:现有剪枝方法未充分利用注意力矩阵的对称性,难以实现高效的剪枝与加速。
本文的核心创新是什么
-
1. 基于块的对称剪枝策略(Block-based Symmetric Pruning):将输入token划分为块,在Query和Key两个方向上联合评估token的重要性,进行2D剪枝,避免仅考虑单一方向带来的信息损失。
-
2. 基于相似性的融合机制:将被剪枝token的信息通过余弦相似度和剪枝模式相似性融合到保留token中,保留关键信息,提升模型精度。
-
3. 对称注意力矩阵的设计:通过共享Query和Key的权重,使得注意力矩阵对称,仅剪枝上三角部分即可映射到下三角,显著减少计算冗余。
-
4. 局部加权平滑机制:引入可学习的3×3卷积对注意力矩阵进行局部加权,增强token重要性评估的鲁棒性。
结果相较于以前的方法有哪些提升
-
1. 精度显著提升:
-
• 在DeiT-T上,ImageNet分类准确率提升了1.3%;
-
• 在DeiT-S上,提升了2.0%;
-
• 在T2T-ViT和LV-ViT上也分别提升了0.9%和0.8%。
-
-
2. 计算效率大幅提升:
-
• 在DeiT-T上,FLOPs降低了50%(从1.2G降至0.6G);
-
• 在DeiT-S上,FLOPs减少了2.2G;
-
• 总体实现了约40%的推理加速。
-
-
3. 泛化能力增强:
-
• 在目标检测(COCO)和实例分割任务中,BSPF-ViT在APbox和APmask指标上优于现有方法;
-
• 适用于多种ViT架构(如DeiT、T2T-ViT、LV-ViT、CaFormer等)。
-
局限性总结
-
1. 固定块大小限制灵活性:当前方法采用固定大小的块进行剪枝,可能不适用于所有图像内容,未来可探索自适应块划分策略。
-
2. 依赖局部相似性建模:融合机制主要基于局部邻域token的相似性,可能忽略长距离依赖关系。
-
3. 对称性假设可能不适用于所有任务:强制Query和Key共享权重虽然提升了效率,但在某些视觉任务中可能会限制模型表达能力。
-
4. 训练阶段需引入额外机制:目前方法在推理阶段进行剪枝与融合,尚未完全集成到端到端训练中,可能影响极限压缩效果。
深入阅读版本
导读
视觉Transformer(ViT)在各种视觉任务中取得了令人印象深刻的结果,但其高昂的计算成本限制了实际应用。近期的方法旨在通过剪枝不重要token来降低ViT的O(n^2) 复杂度。然而,这些技术通常通过独立剪枝 Query (Q)和键(K)token来牺牲精度,由于忽略了token之间的交互而导致性能下降。为了解决这一局限性,作者引入了一种基于块的对称剪枝与融合的ViT高效方法(BSPF-ViT),该方法联合优化Q/K token的剪枝。与以往仅考虑单一方向的方法不同,BSPF-ViT评估每个token及其邻居,通过考虑token交互来决定保留哪些token。保留的token通过相似性融合步骤进行压缩,在保留关键信息的同时降低计算成本。Q/K token的共享权重创建了对称注意力矩阵,允许仅剪枝上三角部分以加速处理。BSPFViT在所有剪枝 Level 上始终优于最先进的ViT方法,在DeiT-T上将ImageNet分类精度提高了1.3%,在DeiT-S上提高了2.0%,同时将计算开销降低了50%。它在各种ViT上实现了40%的加速,并提高了精度。
1. 引言
视觉Transformer(ViT)[10]被引入用于处理视觉任务,它利用自注意力机制和注意力机制,最初设计用于评估序列中单个token的重要性。自那以后,Transformer已成为广泛视觉任务中的主导架构,包括分类[10, 28, 39, 40, 45]、分割[28, 38, 48]和目标检测[5, 45, 57]。完全依赖自注意力机制和MLP层的ViT,相比传统方法如卷积神经网络(CNN),提供了卓越的灵活性和性能优势。然而,自注意力机制相对于token数量的二次计算复杂度构成了重大挑战,特别是随着对大规模基础模型如CLIP [35]和Llama2 [41]的兴趣日益增长。为缓解这一问题,多项研究[3, 21, 30, 44]提出了高效的注意力机制,包括在预定义窗口内的局部自注意力[8, 11, 13, 27, 28, 37]。
对在不改变ViT架构的情况下优化ViT的token减少方法日益感兴趣。这些方法主要分为三类:Token剪枝[12, 32, 33, 36, 52],通过移除无信息token来减少总数;Token重组[4, 22, 25, 29, 31],通过融合而非丢弃token;Token挤压[23, 46],在不创建额外代表性token的情况下最小化信息损失。
这些token剪枝方法通过减少token数量,从而降低了计算 Query 元素和键元素之间点积的计算成本。然而,大多数融合方法倾向于降低模型性能,并且通常只在一个方向(沿 Query 或键)上进行剪枝。作者的观察表明,虽然这些方法有效地降低了计算成本,但它们往往消除了注意力图中的关键信息,并且通常仅基于单个token进行剪枝决策。
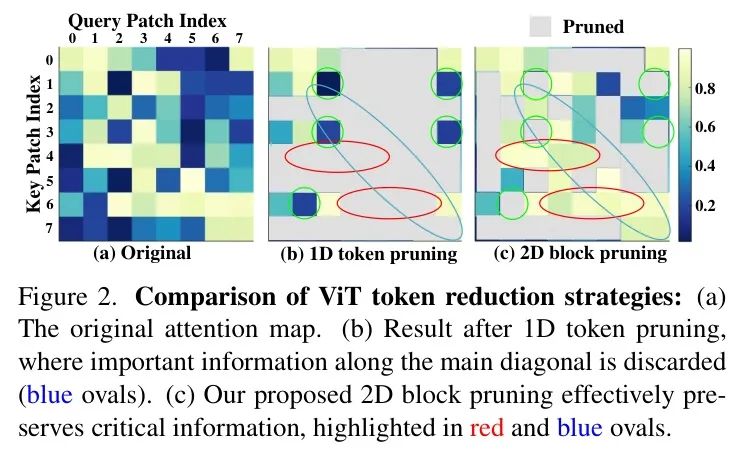
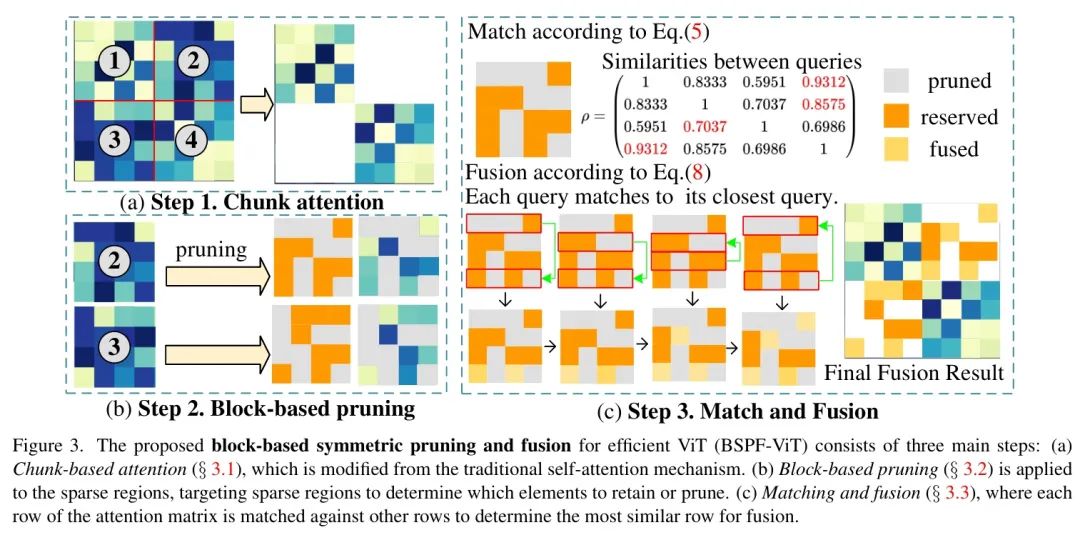
为解决这些问题,作者提出了一种新颖的基于块的对称剪枝与融合方法BSPFViT,该方法通过应用基于块的2D剪枝并对相似性进行融合来优化视觉Transformer。与以往关注单个token的方法不同,这种基于块的剪枝考虑了来自 Query 和键方向的token注意力。它在对块内相邻token进行全面重要性评估后,再决定剪枝哪些token。为保留关键信息,作者通过基于相似性的加权融合方案将剪枝的token整合到保留的token中。为进一步简化自注意力计算,作者在ViT中使用共享的 Query 和键权重,使注意力矩阵对称。这种对称性使作者能够仅剪枝矩阵的上三角部分,并将剪枝位置映射到下三角部分,从而提高了效率。图2提供了ViT token减少策略的High-Level比较,图3概述了所提出的VTPS-ViT方法。
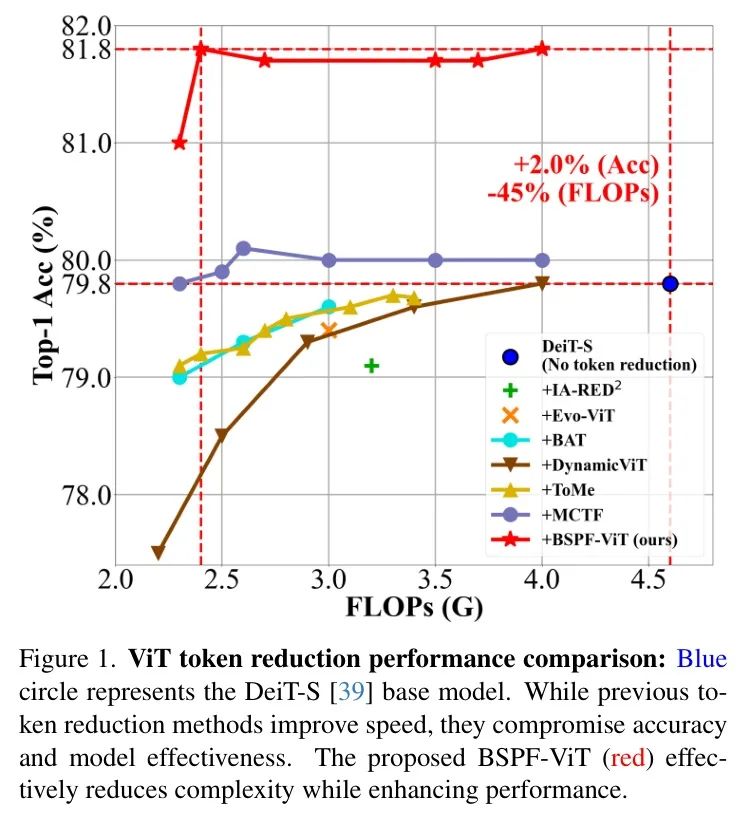
实验表明,将每个token与其相邻token联合考虑能够显著提升效果。BSPF-ViT在性能和计算效率两方面均优于现有方法,如图1所示。BSPF-ViT在DeiT-T上将ImageNet分类准确率提高了1.7%,在DeiT-S上提高了2.0%,同时将FLOPS的计算开销降低了约45%。在T2T-ViT [53]和LV-ViT [18]中,作者观察到类似的加速效果(40%)和性能提升(0.9%和0.8%)。
作者的贡献总结如下:
-
• 作者提出了一种基于块的剪枝方法,通过在 Query (Q)和键(K)方向上评估token重要性来加速ViTs。这种2D剪枝策略使BSPF-ViT区别于传统的仅考虑 Query 或键方向的1D剪枝。
-
• 作者采用基于相似度的融合方法,将剪枝后的token信息整合到保留的token中,从而保留关键信息并提升跨任务准确率。
-
• 作者在ViT中使用 Query 和键的共享权重,以使注意力矩阵对称,从而实现更有效的
基于CI的token剪枝。BSPF-ViT在性能上超越了现有的ViT token剪枝方法,同时显著降低了计算复杂度。
2. 相关工作
2.1. 视觉Transformer
视觉Transformer(ViTs)[10]被引入以处理视觉任务,DeiT [39]和CaiT [40]等进展提升了其数据效率和可扩展性。近期研究[6, 9, 16, 28, 45]将类似CNN的归纳偏置融入ViTs,例如局部性和金字塔结构。与此同时,其他研究[2, 15, 40, 47, 56]专注于扩展和自监督学习以改进基础ViTs。尽管取得了这些进展,ViTs的二次复杂度仍对模型扩展构成重大挑战。
为解决这一复杂性,Reformer [21] 利用哈希函数将二次复杂度降低至 O(Nlog N) ,而Linformer [44]、Performer [7] 和 Nystromformer [49] 则通过近似线性注意力实现线性复杂度。此外,多项研究 [1, 8, 9, 28] 探索了通过减少键或 Query 的数量来实现的Sparse注意力机制。Swin Transformer [28] 和 Twins [8] 通过在固定大小的窗口内应用局部注意力进一步降低了复杂度。
2.2. 自注意力机制
近年来,视觉Transformer(ViT)在计算机视觉任务中的性能得到了显著提升。多项研究引入了新型架构以增强效率和性能。例如,全局-局部自注意力结合的GCViT [13] 能够有效建模长距离和短距离空间交互。结合卷积网络的SMT [27] 具有多头注意力模块和尺度感知模块。通过更大步长的patchify主干和单头注意力,SHViT [54] 减少了计算冗余。RMT [11] 通过基于曼哈顿距离的空间衰减矩阵引入显式空间先验。TransNeXt [37] 通过使用聚合注意力(一种仿生 Token 混合设计)和卷积GLU作为通道混合器来解决深度退化问题,并增强了局部建模能力。这些架构在ImageNet分类、COCO目标检测和ADE20K语义分割等任务上取得了当前最佳性能。
2.3. 视觉Transformer中的Token减少
ViT中的主要计算负担来自于selfattention机制。近期研究[4, 12, 22, 25, 29, 31-33, 36, 52]聚焦于通过减少token数量来缓解这一负担,通常通过评估每个token的重要性并丢弃被认为不那么重要的token来实现。Token减少方法可以大致分为三类:token剪枝、token重组和token挤压,每种方法都有独特的实现高效token减少的方式。
Token剪枝根据注意力分数等标准丢弃重要性较低的token。例如,Fayyaz等人[12]提出了自适应token采样器(ATS)模块,在不损失精度的前提下将GFLOPs减少一半;AdaViT[32]保留关键patch和block,速度翻倍且影响最小;IA-RED2[33]动态移除不相关的token,实现高达的1.4x速度提升;DynamicViT[36]逐步剪枝冗余token,将FLOPs降低31%并提升吞吐量40%;A-ViT[52]自适应停止token计算以加速推理。尽管这些方法高效,但存在关键信息丢失的风险。Hessian感知剪枝[51]在transformer block间全局重新分配参数,但需要大量计算资源,增加了复杂性。
Token重组涉及将重要性较低的token整合为单个具有代表性的token。例如,SPViT [22] 采用一种延迟感知的软token剪枝框架,以降低计算成本同时满足特定设备的延迟要求。Token合并(ToMe)[4] 通过合并相似的token提升吞吐量,且无需重新训练。EViT [25] 通过保留最关注的token并合并最不关注的token来重组token,从而提高效率和准确性。一种高效的token解耦和合并方法 [29] 利用token重要性和多样性将关注的token与不关注的token分离,实现更有效的剪枝。Token池化 [31] 将token视为连续信号中的样本,并选择最优的token集合来近似该信号,从而优化计算-精度权衡。这些重组方法在降低计算成本的同时保留了重要信息。
基于相似性,将重要性较低的token与重要性较高的token进行挤压合并。例如,多标准Token融合(MCTF)[23]使用相似性、信息量及融合Token大小等标准逐步合并Token,并采用一步前向注意力机制评估信息量。联合Token剪枝与挤压(TPS)[46]将剪枝与挤压相结合,保留剪枝Token信息以平衡效率与准确率。然而,这些方法仅在一个方向上进行Token剪枝。Token融合(ToFu)[20]通过MLERP结合剪枝与合并,保留特征范数,在分类和图像生成任务中提升效率与准确率。Zero-TPrune [43]引入零样本剪枝,利用预训练Transformer注意力图减少FLOPs并提升吞吐量,无需微调。
ELSA [17] 在视觉 Transformer ViTs 中采用逐层 N:M Sparse性来优化加速器的Sparse性,显著降低了 Swin-B 和 DeiT-B 模型的 FLOPs,同时在 ImageNet 上几乎没有精度损失。
综上所述,现有的ViT token减少方法主要集中于沿单一方向丢弃不重要token,即 Query 方向或键方向。如图2所示,尽管序列token剪枝能够有效移除低分token,但它往往沿主对角线方向(蓝色圆圈 Token )丢弃重要信息(红色圆圈 Token )。此外,当选择某些 Query 或键方向时,沿所选方向具有较低注意力值的不重要条目仍被保留(图2(b)和图2(c)中的绿色圆圈)。在本文中,作者提出一种解决方案,通过过滤掉不重要token来执行基于块的剪枝,从而保留具有更高注意力的条目。
3. 方法
提出的基于块的对称剪枝与融合(BSPF-ViT)通过图3中概述的精简流程提升ViT效率,该流程包含三个主要步骤:(1)基于块的注意力机制:通过将输入token划分为块并对每个块内应用自注意力机制来适配传统自注意力机制(3.1)。(2)基于块的剪枝:在基于块的注意力机制基础上,引入基于块的剪枝策略,仅保留每个块中最重要的元素。这减少了计算负载,同时保留了关键信息,并应用于Sparse区域,根据Sparse性选择性地保留或剪枝元素(3.2)。(3)匹配与融合:将注意力矩阵的每一行与其他行进行比较,识别并与其最相似的行进行融合。通过将剪枝的token与其最近匹配对齐,模型保留了关键信息流并最小化数据丢失(S 3 . 3)。
3.1. 基于块的注意力机制

3.2. 基于块的剪枝

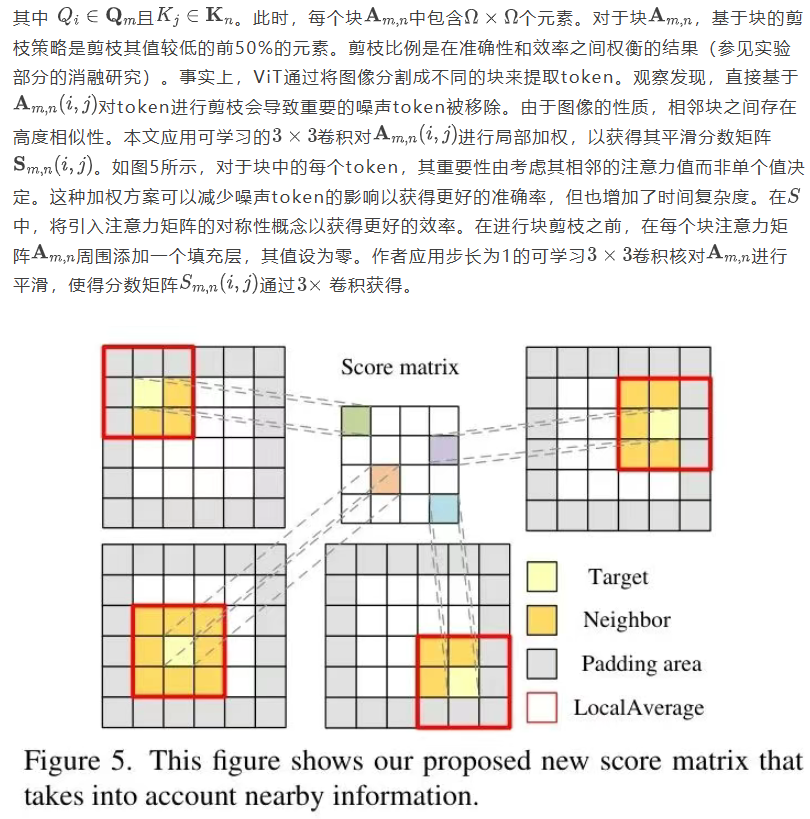

3.3. 匹配与融合
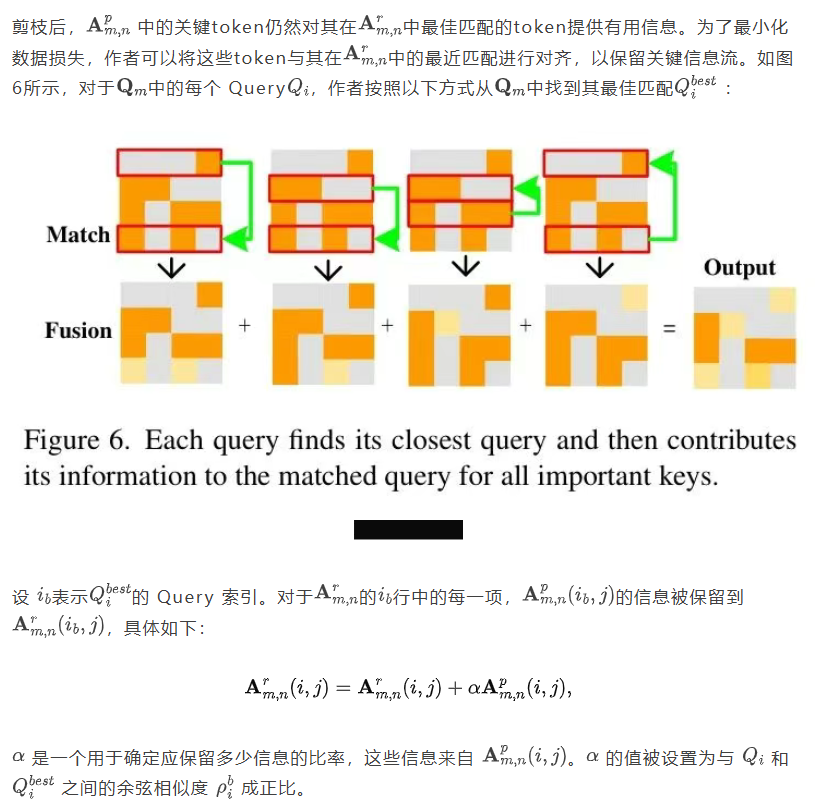


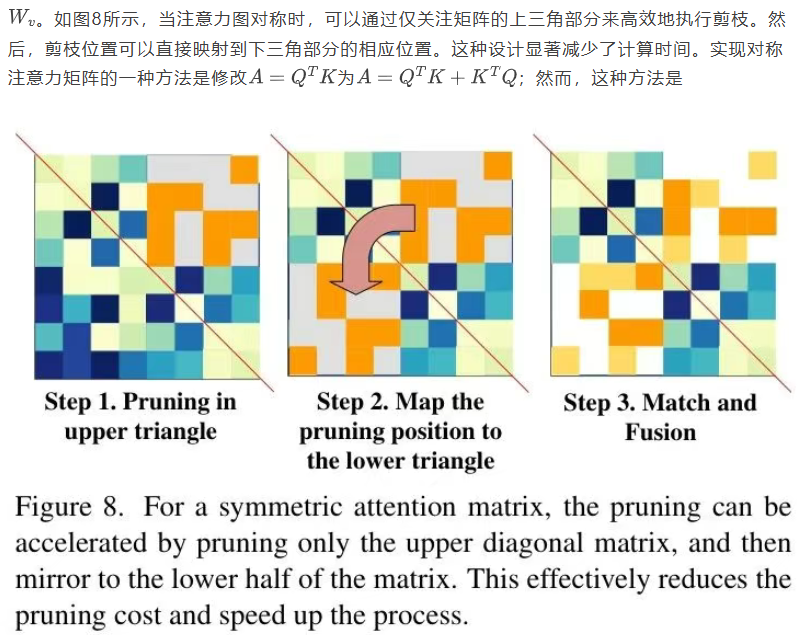
3.4. 对称性

4. 实验结果
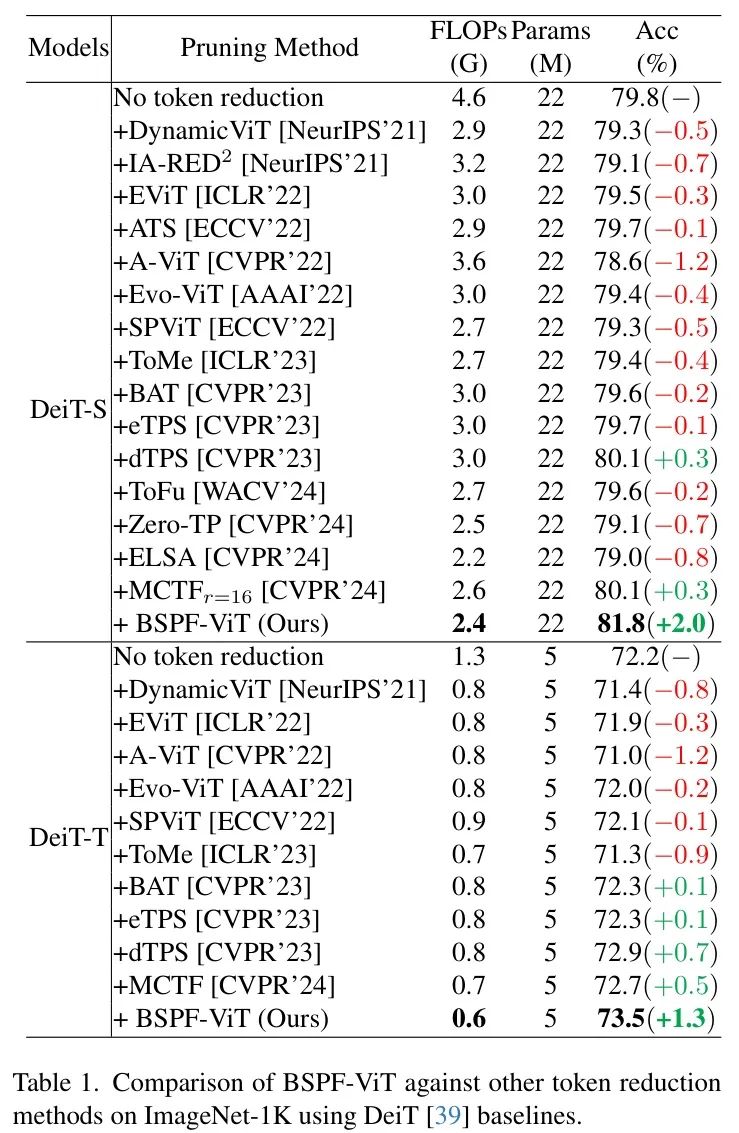
为验证BSPF-ViT在当前最优(SoTA)token减少技术方面的有效性,作者评估了一系列token剪枝方法,包括A-ViT [52]、IARED2 [34]、DynamicViT [36]、EvoViT [50]和ATS [12],以及token融合方法,如SPviT [22]、EViT [25]、ToMe [4]、BAT [29]、ToFu [20]、Zero-TP [43]、ELSA [17]和MCTF [23],并以DeiT [39]作为基准。作者报告了每种方法的效率(GFLOPs)和Top-1准确率(%)。此外,为评估作者的基于块的对称剪枝和融合方法在其他视觉Transformer(如T2T-ViT [53]和LVViT [18])上的表现,作者将作者的结果与其官方得分进行了比较。在表1至表3中,灰色表示基础模型,绿色和红色分别表示相对于基础模型性能的提升和下降。
对token减少方法的比较。表1展示了作者的BSPF-ViT与其他token减少方法之间的性能比较。BSPF-ViT始终表现优异,在DeiT [39] Baseline 上实现了最高精度和最低FLOPs。值得注意的是,BSPF-ViT是唯一在保持极低FLOPs的同时在DeiT-T和DeiT-S上实现1.0%性能提升的方法。具体而言,BSPF-ViT在DeiT-T中将精度提升了1.3%,并将FLOPs减少了50%。同样,在DeiT-S中,BSPF-ViT实现了2.0%的精度提升,同时将FLOPs减少了2.2 G。虽然TPS和MCTF在DeiT-T上取得了一些改进,但它们在DeiT-S上的提升有限。相比之下,BSPF-ViT始终将DeiT-S的精度提升2.0%,展示了其相对于其他1D token剪枝技术的优越性。
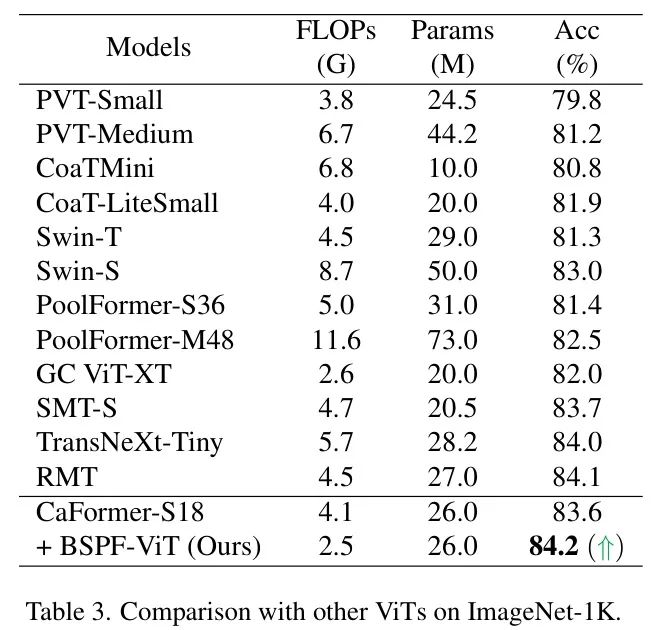
与基于块的剪枝和不基于块的剪枝的SoTA ViTs的比较。为了进一步评估BSPF-ViT的有效性,作者将其应用于额外的Transformer架构,如表2所示。虽然MCTF在这些架构中实现了31%的加速,且不牺牲性能,但BSPFViT超越了MCTF,提供了10%的加速提升和1%的精度改进。值得注意的是,当与LV-ViT结合时,作者的BSPF-ViT在FLOPs和精度方面均优于所有其他Transformer和token减少方法。与其他会降低LV-ViT性能的方法不同,BSPF-ViT实际上增强了其性能。这些发现证实BSPF-ViT是各种ViT架构中一种稳健的token减少方法。
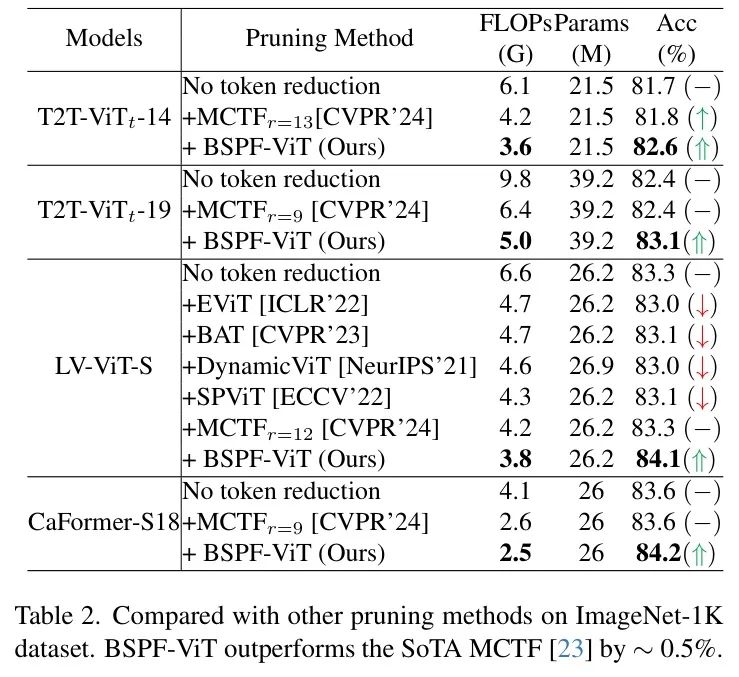
在表3中,作者还比较了在MetaFormer框架内应用于CaFormer-S18架构的所提方法与其他ViT架构的性能。BSPF-ViT显示出良好的潜力,在CaFormer-S18上实现了10%的速度提升和0.6%的精度提高。BSPF-ViT不仅提高了模型效率,还提升了精度,进一步验证了BSPF-ViT在剪枝过程中能有效保留关键信息。
4.1. 下游任务
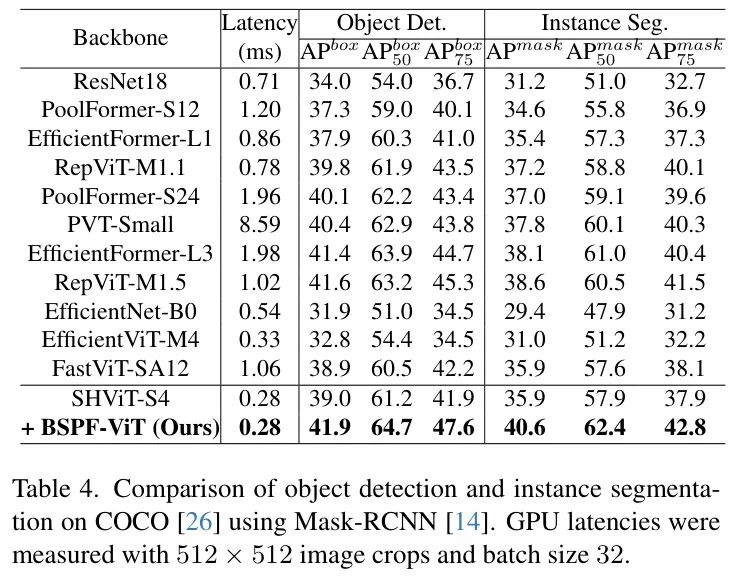
目标检测与实例分割。作者通过将BSPF-ViT集成到SHViT中,评估其在目标检测和实例分割任务上的泛化能力。遵循[24],作者将剪枝后的SHViT集成到Mask R-CNN框架[14]中,并在MS COCO数据集[26]上进行了实验。如表4所示,BSPF-ViT在APbox和APmask指标上均优于竞争模型,即使模型规模相似。具体而言,它在APbox上领先RepViT-M1.1主干网络2.1,在APmask上领先3.4。与SHViT相比,剪枝后的SHViT在APbox上表现相当,但在APmask上表现更高,这展示了BSPF-ViT在高分辨率视觉任务中的显著优势与通用性。这些结果清晰地突显了BSPF-ViT在迁移到下游视觉任务中的优越性。
4.2. 消融研究
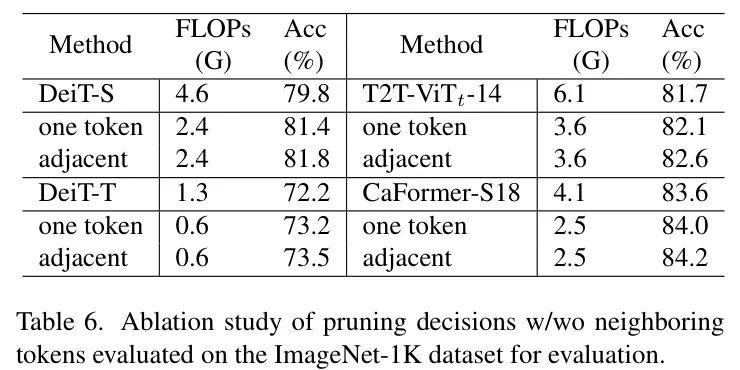
带与不带邻近 Token 的剪枝决策。作者假设在ViT任务中,相邻 Token 之间存在相关性,因为图像被划分为固定大小的 Token 并输入到自注意力机制中。在表6中,作者考察了不同的剪枝决策对所提出的BSPF-ViT在四种架构(DeiT-S、DeiT-T、T2T-ViT和CaFormer-S18)上的影响。结果表明,利用邻近 Token 的综合表达能力进行剪枝决策比仅依赖单个 Token 的效果更好。这一观察结果支持了作者的假设,即 Token 之间确实存在相关性,因此在做出剪枝决策时,邻近 Token 应同时被考虑。
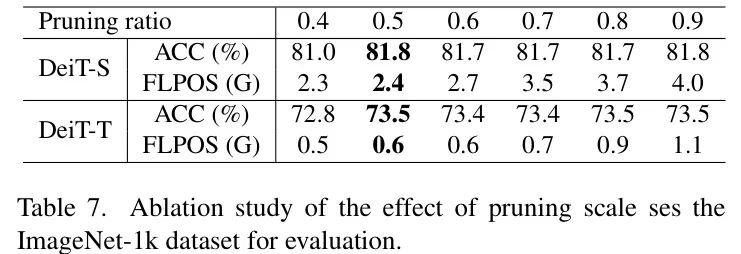
剪枝比例。表7展示了不同剪枝比例的消融研究。当剪枝比例为0.9或0.8时,模型保持稳定的精度(DeiT-S: 81.8% A DeiT-T: 73.5%),但计算成本显著增加。相比之下,0.4的较低剪枝比例会导致精度明显下降(DeiT-S: 81.0%,DeiT-T: 72.8%),这是由于信息损失过多。在这些剪枝比例中,0.5提供了最佳平衡,既能保留重要信息,又能有效减少FLOPs(DeiT-S: 2.4G,DeiT-T: 0.6G),同时不牺牲精度。因此,作者选择0.5作为效率和性能的最佳剪枝比例。
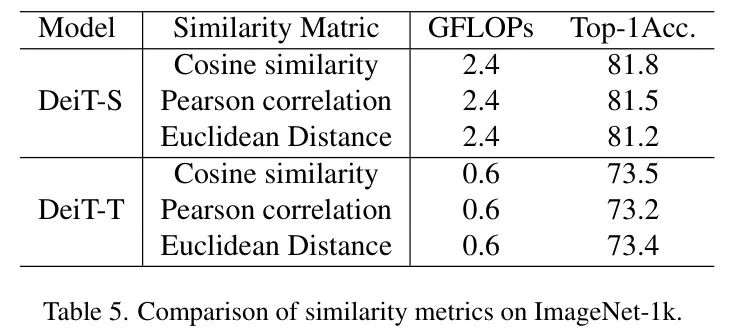
相似度矩阵。作者将BSPF-ViT应用于DeiTS和DeiT-T模型,比较了各种相似度度量方法。表5中的结果清晰地表明,余弦相似度优于欧几里得距离和皮尔逊相关系数。欧几里得距离关注绝对差异,可能会忽略深度学习特征空间中的重要相似性。皮尔逊相关系数测量线性关系,但在高维空间中,特征之间的关系可能并非线性,这使得它在捕捉复杂相似性方面不如余弦相似度有效。
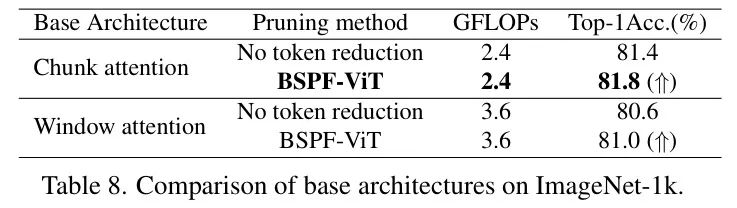
基础架构的消融研究。在图3中,作者用块注意力机制替换传统注意力机制以降低计算复杂度。此前,窗口注意力机制被用于类似目的。表8比较了块注意力机制和窗口注意力机制与有无BSPF-ViT的两种注意力机制。不进行token减少的方法往往准确性较低。这两种方法仅关注对角线附近的元素,忽略了远距离token之间的相关性。通过引入BSPF-ViT,可以保留重要信息,提高准确性和效率。此外,块注意力机制比窗口注意力机制更有效,因为作者使BSPF-ViT的尺寸与块尺寸对齐,允许模型并行处理注意力和执行BSPF-ViT,进一步提高了效率。
5. 结论
本文提出了一种基于区块的token剪枝方法,用于高效ViTs,在准确性和计算效率之间取得平衡。通过利用 Query 和键之间的对称性,作者保持对称注意力矩阵,简化剪枝过程中的计算。BSPF-ViT结合邻近token评估token的重要性,实现更精确的剪枝。通过基于相似性的融合,将剪枝信息恢复到保留的token中,增强了数据完整性和模型准确性。BSPF-ViT将DeiT-S模型的准确性提高了2.0%,并将FLOPs降低了2.2G,在下游任务中的应用展示了其通用性。与1D剪枝方法不同,BSPF-ViT捕捉了更广泛的token交互,并支持并行区块处理,加速推理。未来的工作将探索自适应区块大小和灵活的剪枝策略,以进一步降低计算成本。
参考
[1]. Block-based Symmetric Pruning and Fusion for Efficient Vision Transformers
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2924
2924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









